Download as PDF, PPTX


![About the Music and AI Lab @ Sinica
• About Academia Sinica
National academy of Taiwan, founded in 1928
About 1,000 Full/Associate/Assistant Researchers
• About Music and AI Lab (musicai)
Since Sep 2011
Members
PI [me]
research assistants
PhD/master students
3 AAAI full papers + 3 IJCAI full papers in last two years
MidiNet, MuseGAN, PerformanceNet, etc
2](https://image.slidesharecdn.com/20191119machinelearningxmusic-191119091514/85/machine-learning-x-music-2-320.jpg)
![About the Music AI Team @ Taiwan AI Labs
• About Taiwan AI Labs
Privately-funded research organization (like openAI),
founded by Ethan Tu (PTT) in 2017
Three main research area: 1) HCI, 2) medicine, 3) smart city
• About the Music AI team
Members
scientist [me]
ML engineers (for models)
musicians
program manager
software engineers (for frontend/backend)
3](https://image.slidesharecdn.com/20191119machinelearningxmusic-191119091514/85/machine-learning-x-music-3-320.jpg)



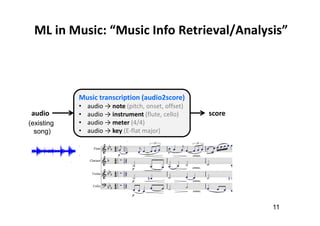
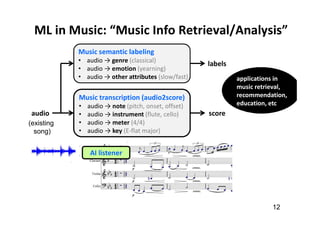
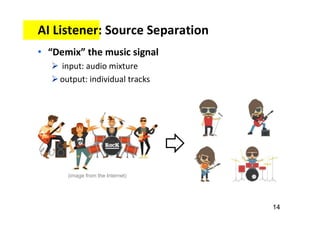

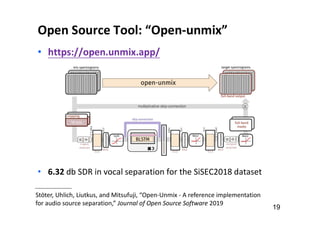
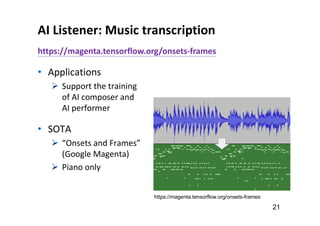
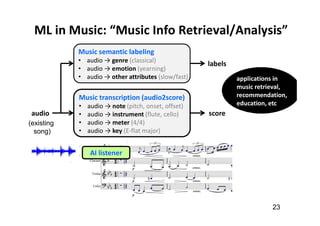
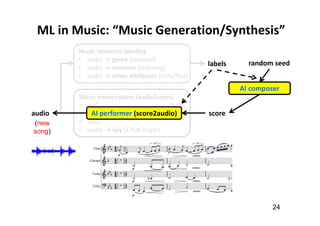



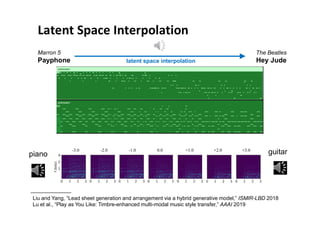



![Music AI Research (at the Taiwan AILabs)
49
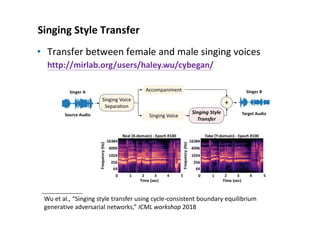
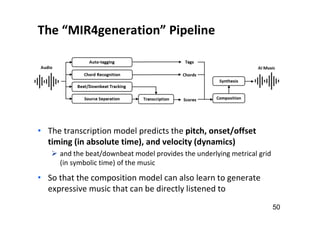
• “audio in, audio out”
audio → audio: source separation (SS) [denoising]
audio → score: music transcription (MT) [ASR]
score → score: composition [NLG]
score → audio: synthesis [TTS]](https://image.slidesharecdn.com/20191119machinelearningxmusic-191119091514/85/machine-learning-x-music-28-320.jpg)

The document provides an overview of research and developments in music and AI at Taiwan AI Labs and Academia Sinica, detailing the Music and AI Lab's contributions in music information retrieval, transcription, and machine learning models. It discusses various applications of AI in music, including recommendation systems, source separation, and music generation. Additionally, it highlights the roles of AI as musicians in analyzing, creating, and synthesizing music.



































































