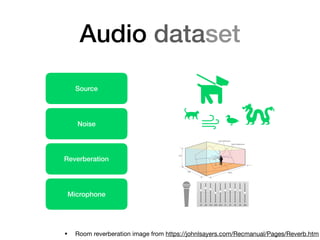
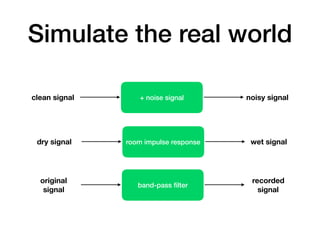
This document serves as a guide for software engineers and deep learning practitioners on how to work with audio signals in deep learning, covering dataset preparation, signal pre-processing, network design, and outcome expectations. It emphasizes the importance of understanding audio data characteristics, choosing appropriate audio representations, and using established practices in deep learning and transfer learning. The content stresses the need for practical approaches while recognizing the complexities involved in audio signal processing.











![Audio representations
Type Description
Data shape and size
for e.g., 1 second,
sampling rate=44100
Waveform x
44100 x [int16]
Spectrograms
STFT(x)
Melspectrogram(x)
CQT(x)
513 x 87 x [float32]
128 x 87 x [float32]
72 x 87 x [float32]
Features
MFCC(x)
= some process on STFT(x)
20 x 87 x [float32]
Spoiler: log10(Melspectrograms) for the win,
but let's see some details](https://image.slidesharecdn.com/qconkeunwoochoi-190609193832/85/Deep-Learning-with-Audio-Signals-Prepare-Process-Design-Expect-16-320.jpg)