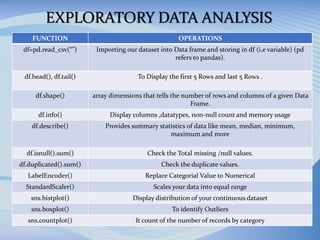
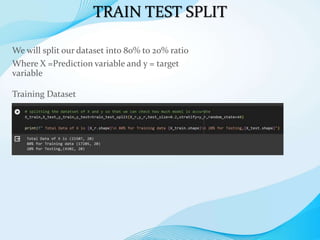
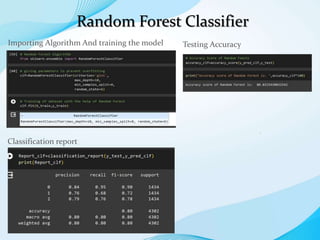
The document outlines the development of a machine learning model to predict accident severity based on various factors such as age, gender, and driving experience. It details the approach, including data preprocessing, exploratory data analysis, and utilizing algorithms like random forest and gradient boosting for model training. The goal is to provide insights into the factors affecting accident outcomes and improve driving safety.




























































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)

![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)


