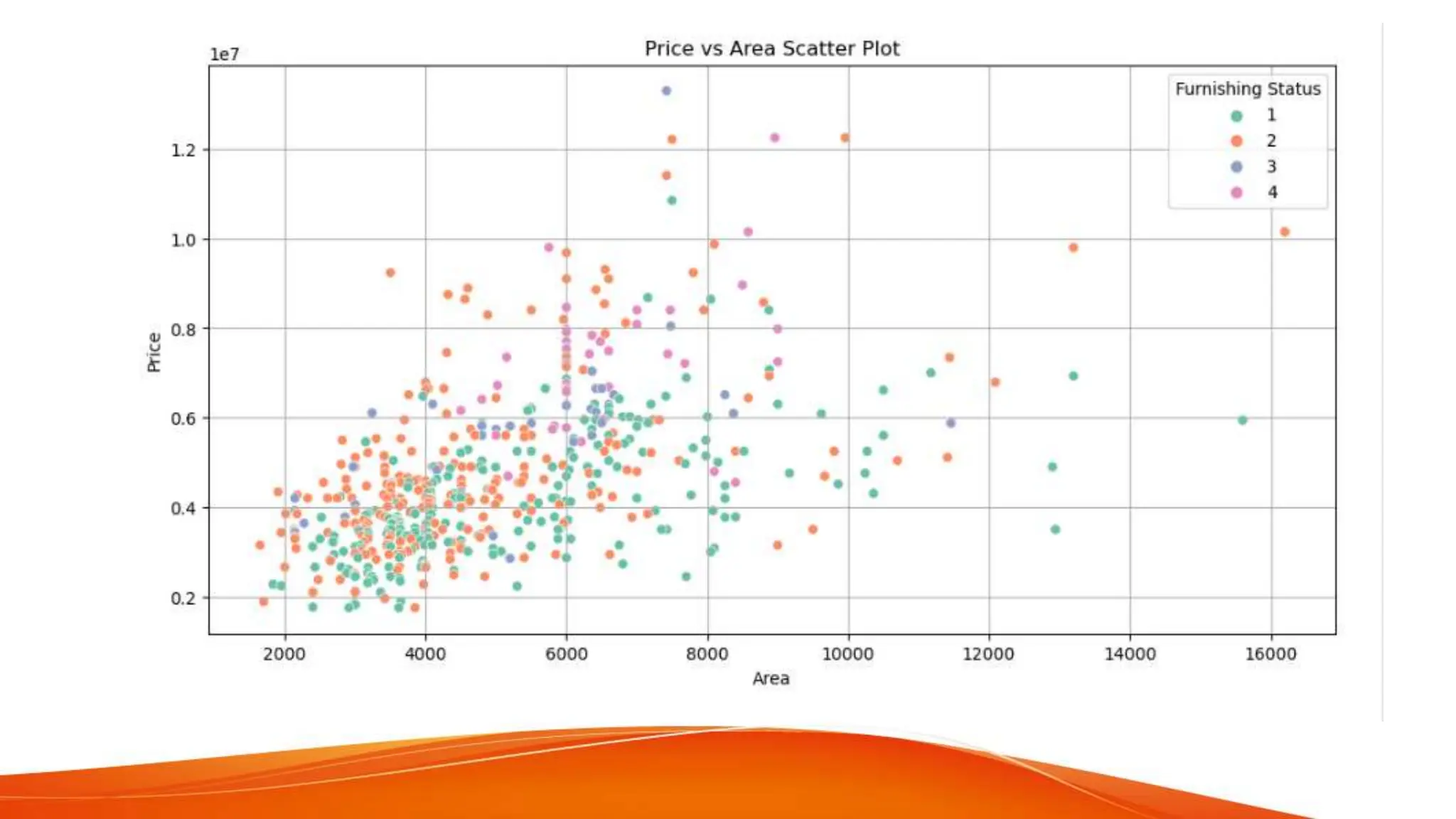
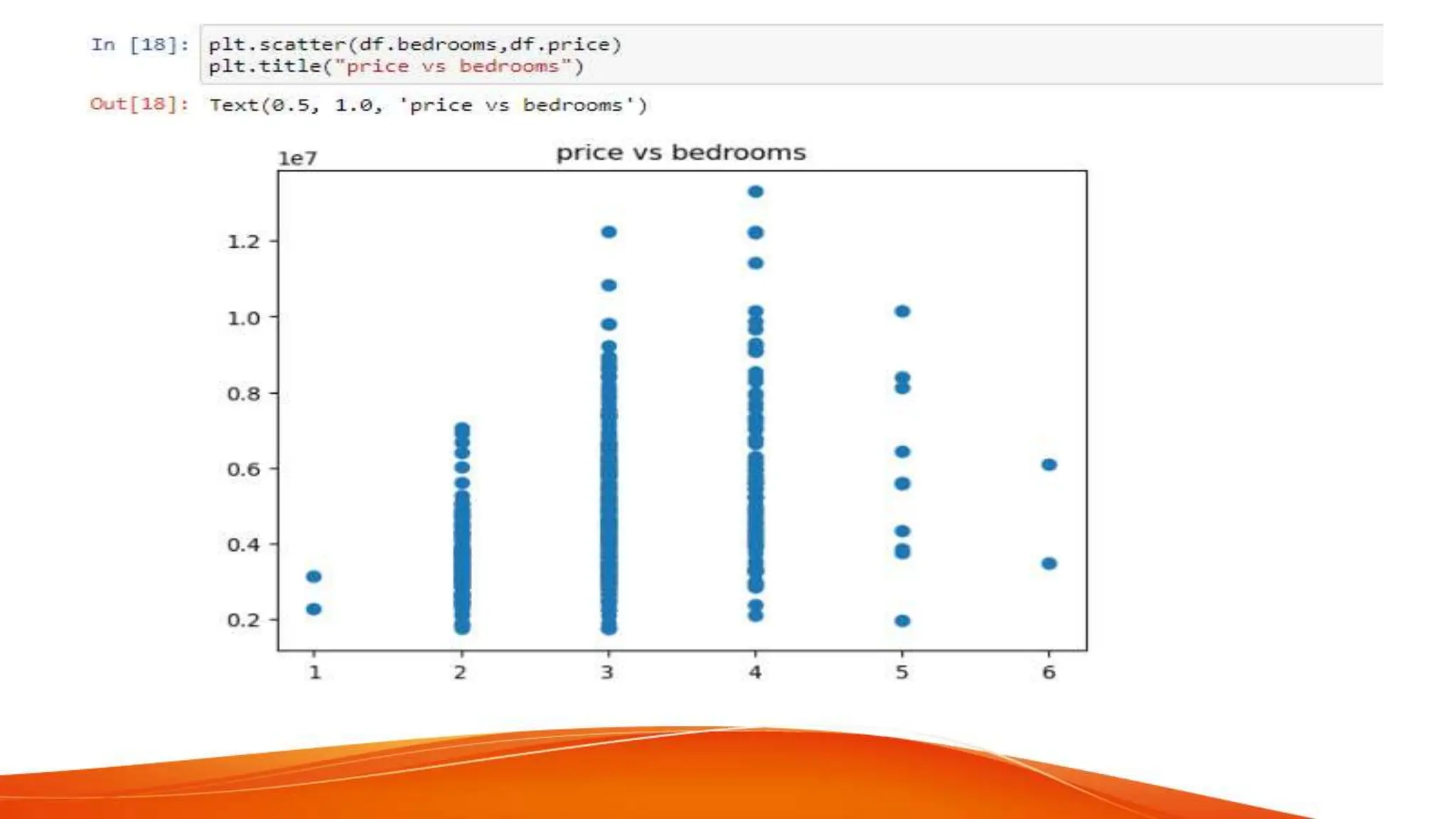
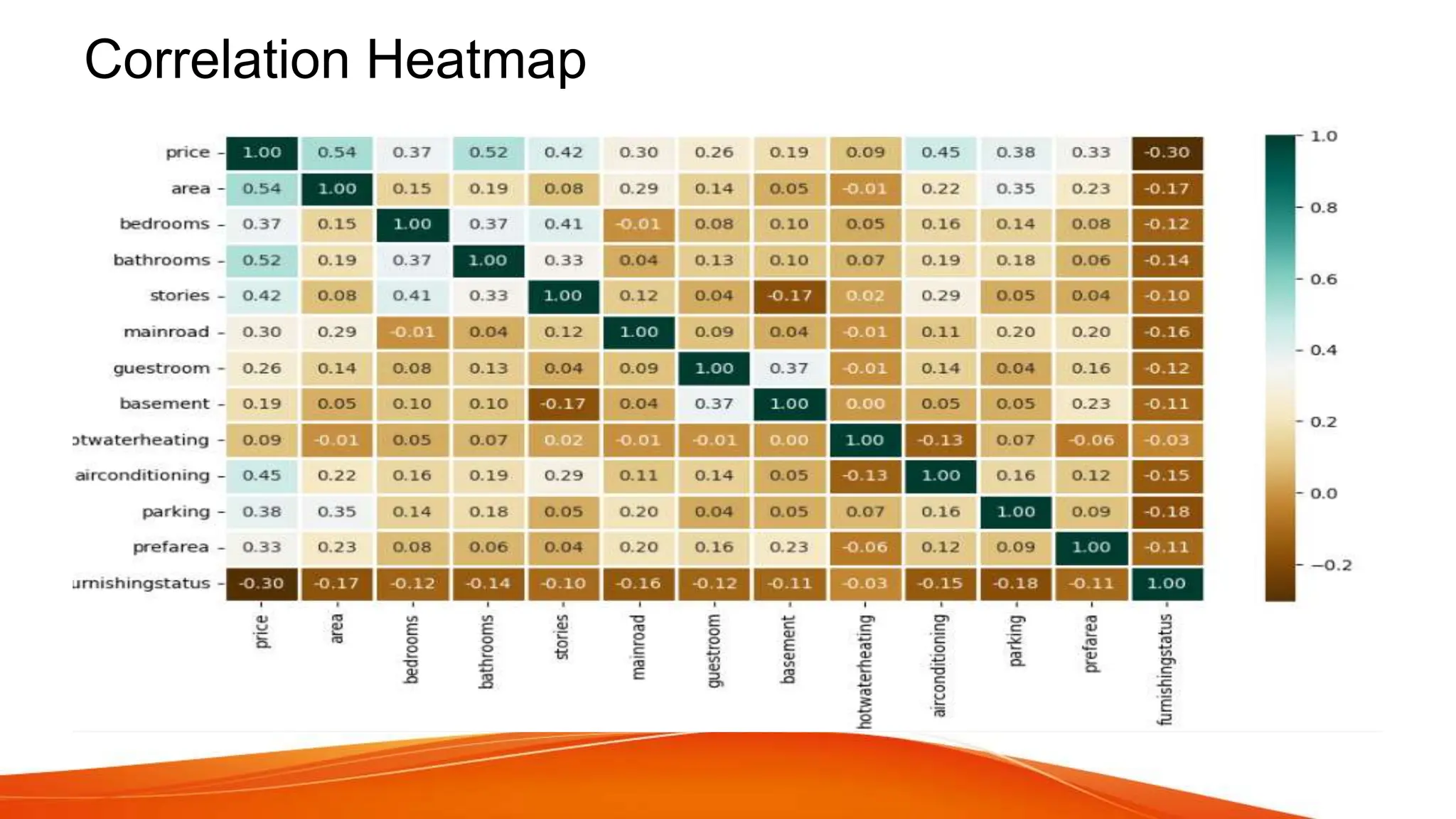
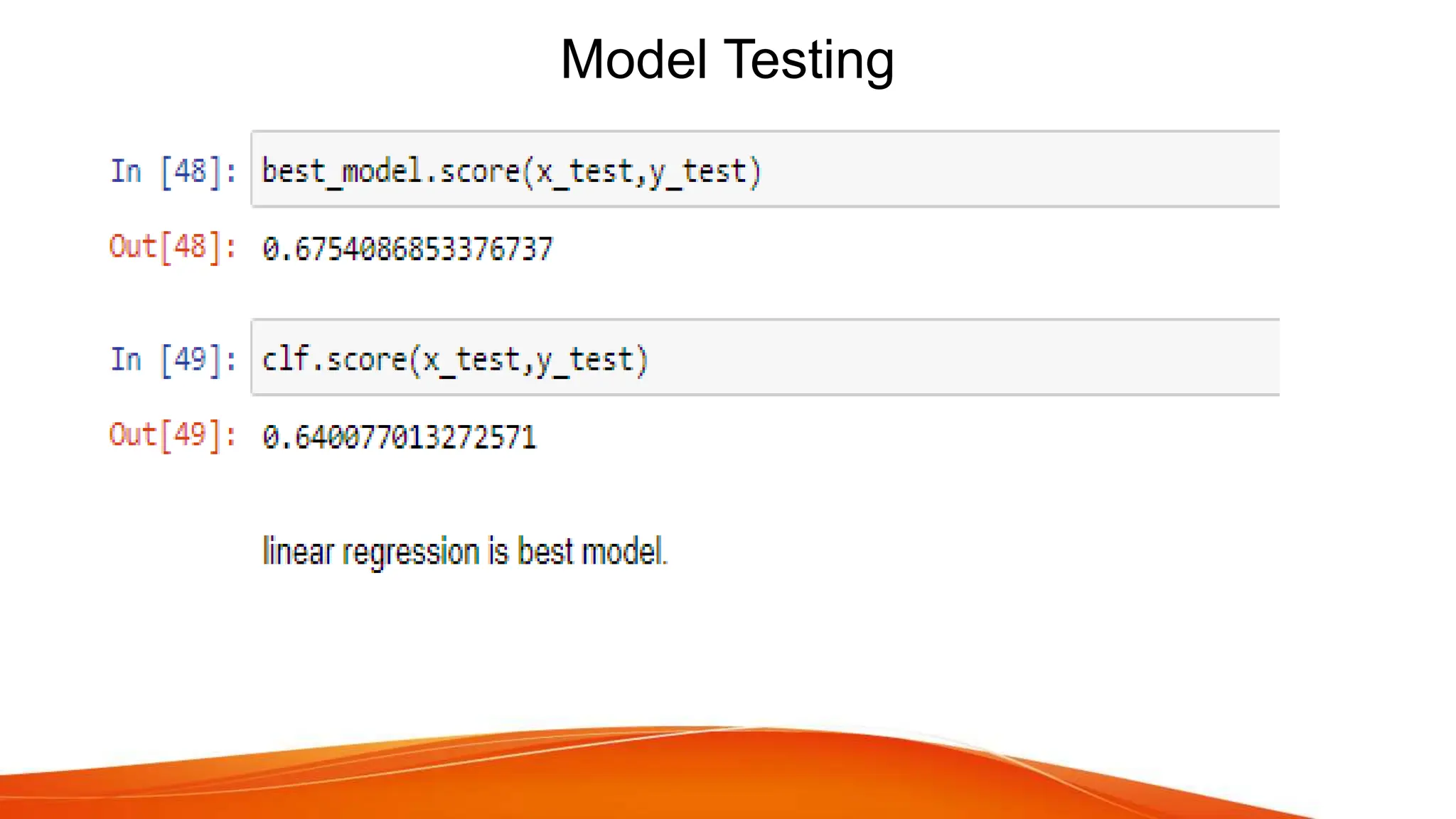
The document discusses house price forecasting using machine learning techniques applied to historical property data in India. It highlights the effectiveness of multiple linear regression, which outperforms gradient boosting in terms of accuracy for predicting house prices. The study also covers data selection, visualization, and evaluation metrics, concluding that the proposed model can provide valuable price predictions for buyers and sellers.
















































































![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)