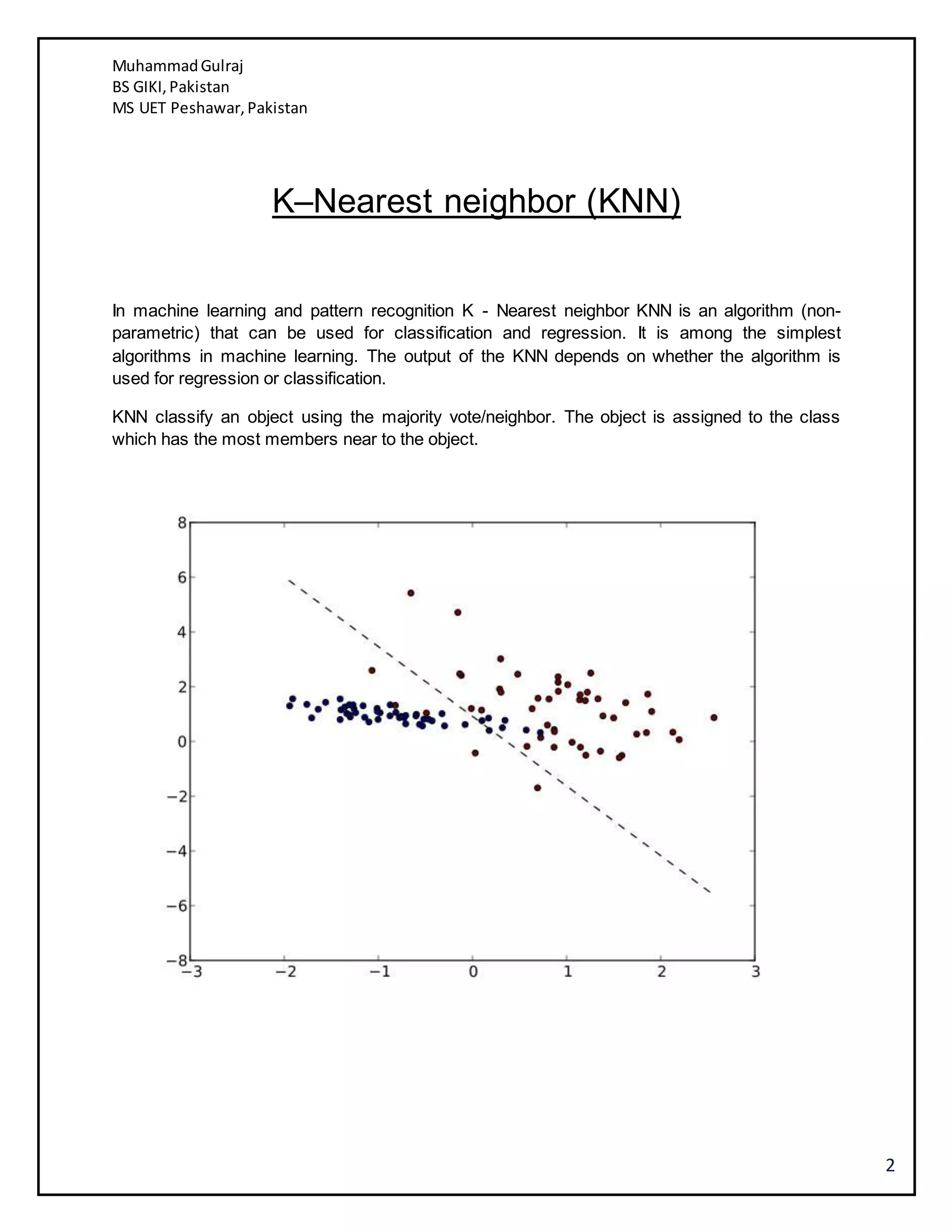
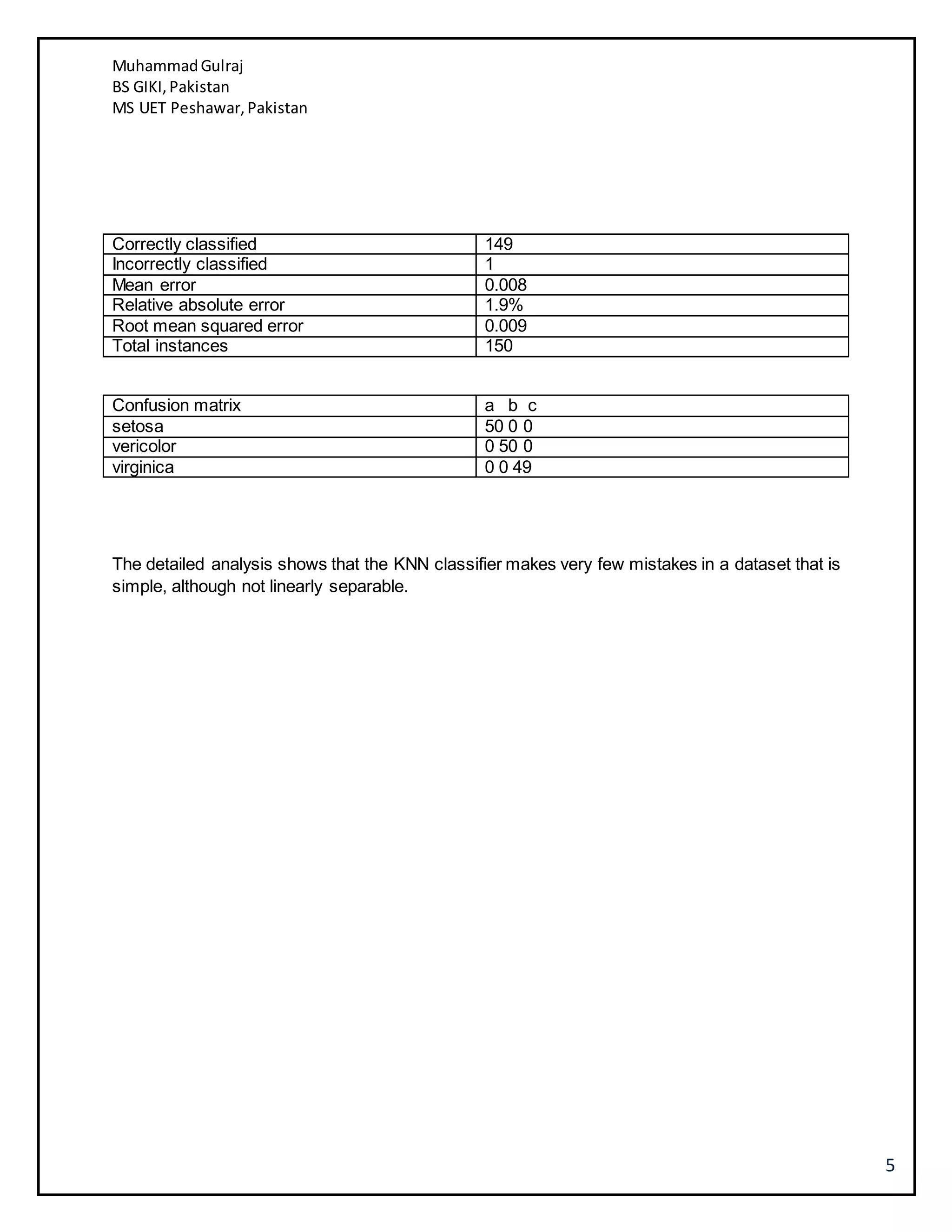
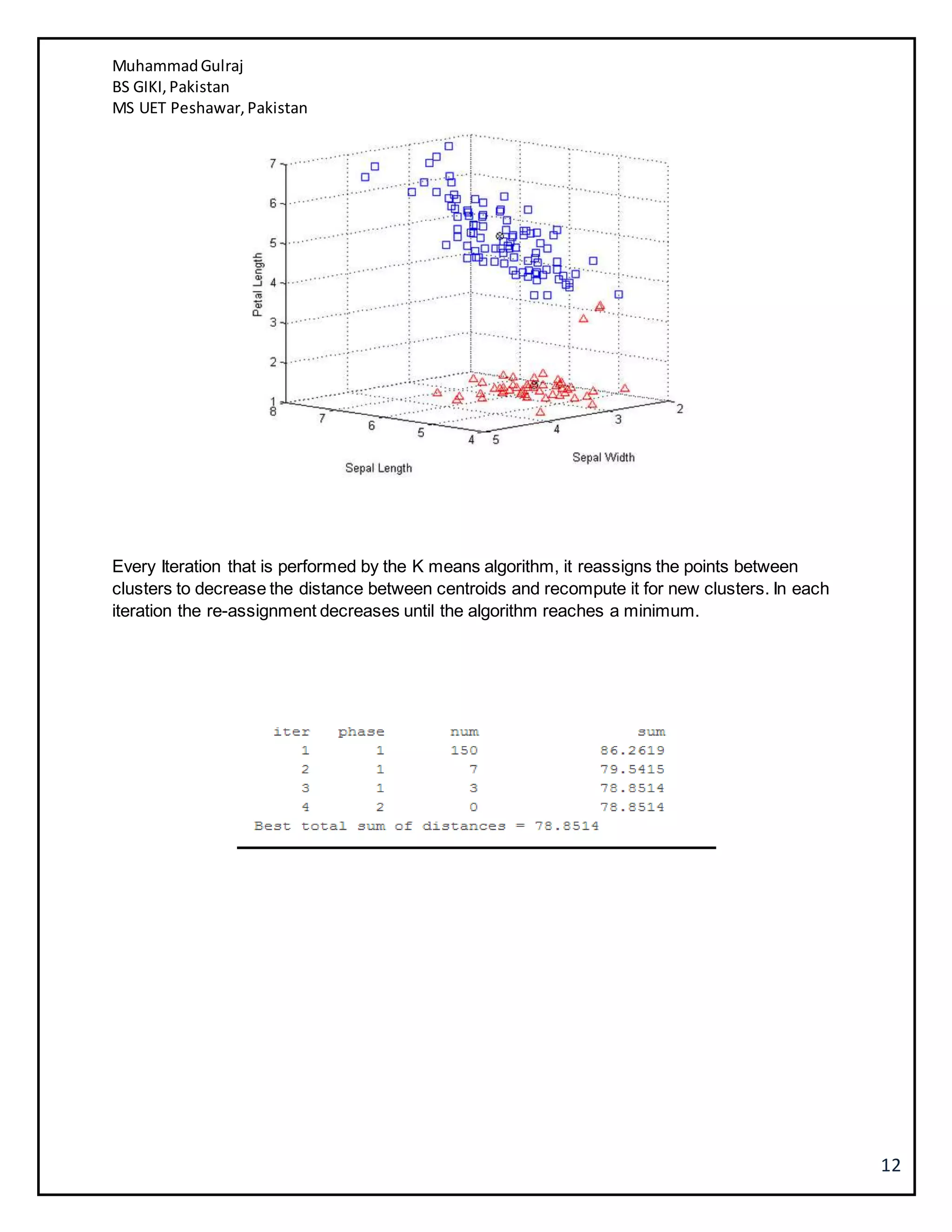
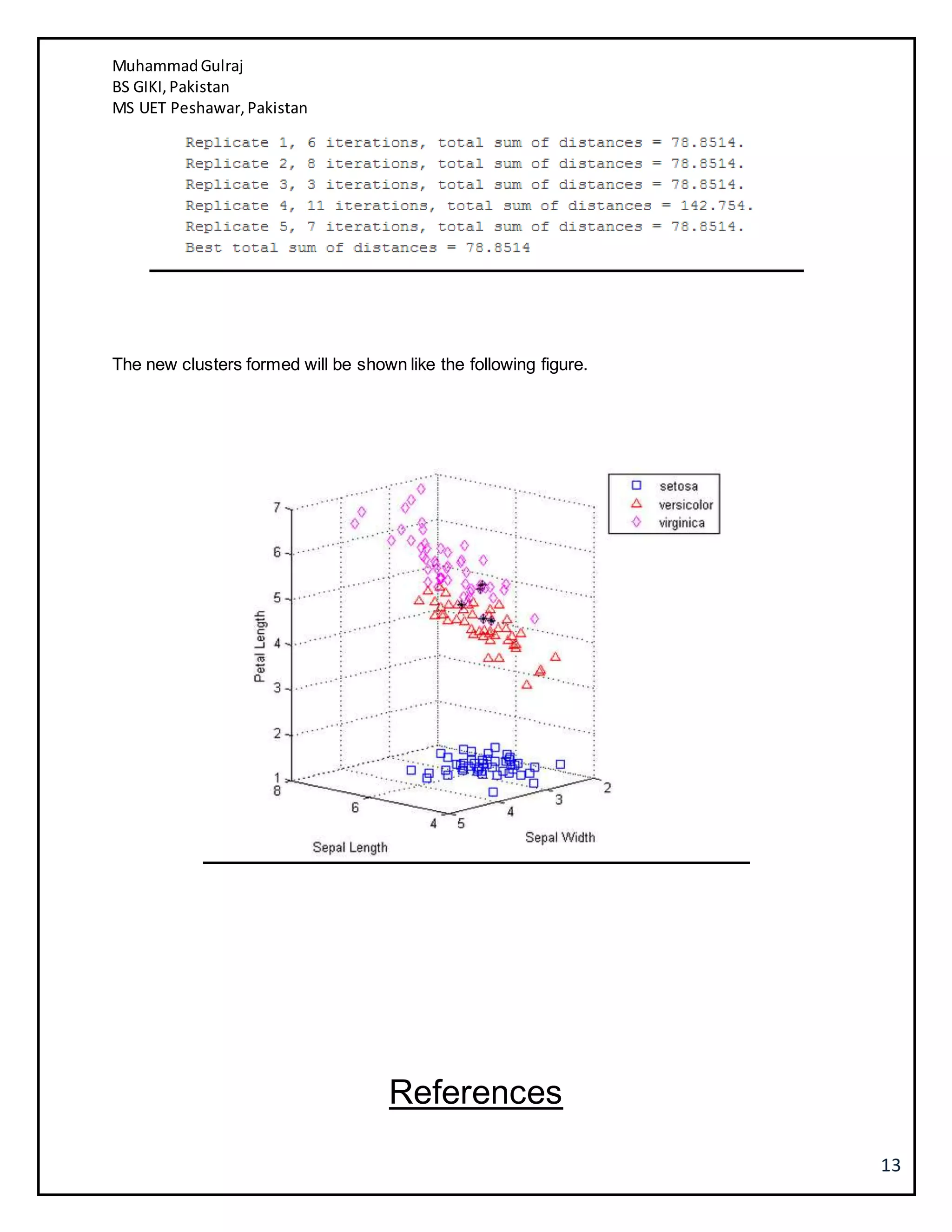
This document discusses several machine learning algorithms including K-nearest neighbors (KNN), Naive Bayes classification, and K-means clustering. KNN is described as a simple algorithm that classifies objects based on the majority class of its K nearest neighbors. Naive Bayes classification uses Bayes' theorem to update classification probabilities based on additional evidence or features. K-means clustering partitions observations into K clusters by assigning each observation to the nearest cluster mean and iteratively updating the cluster means. Examples and implementations of each algorithm are provided.