Download to read offline






![This product will get you 100.000 United Kingdom "HOTMAIL" Emails Leads
Source: http[:]//6qlocfg6zq2kyacl.onion/viewProduct?offer=857044.38586](https://image.slidesharecdn.com/mariadbsteveclees-180306225536/75/M-18-How-InfoArmor-Harvests-Data-from-the-Underground-Economy-8-2048.jpg)
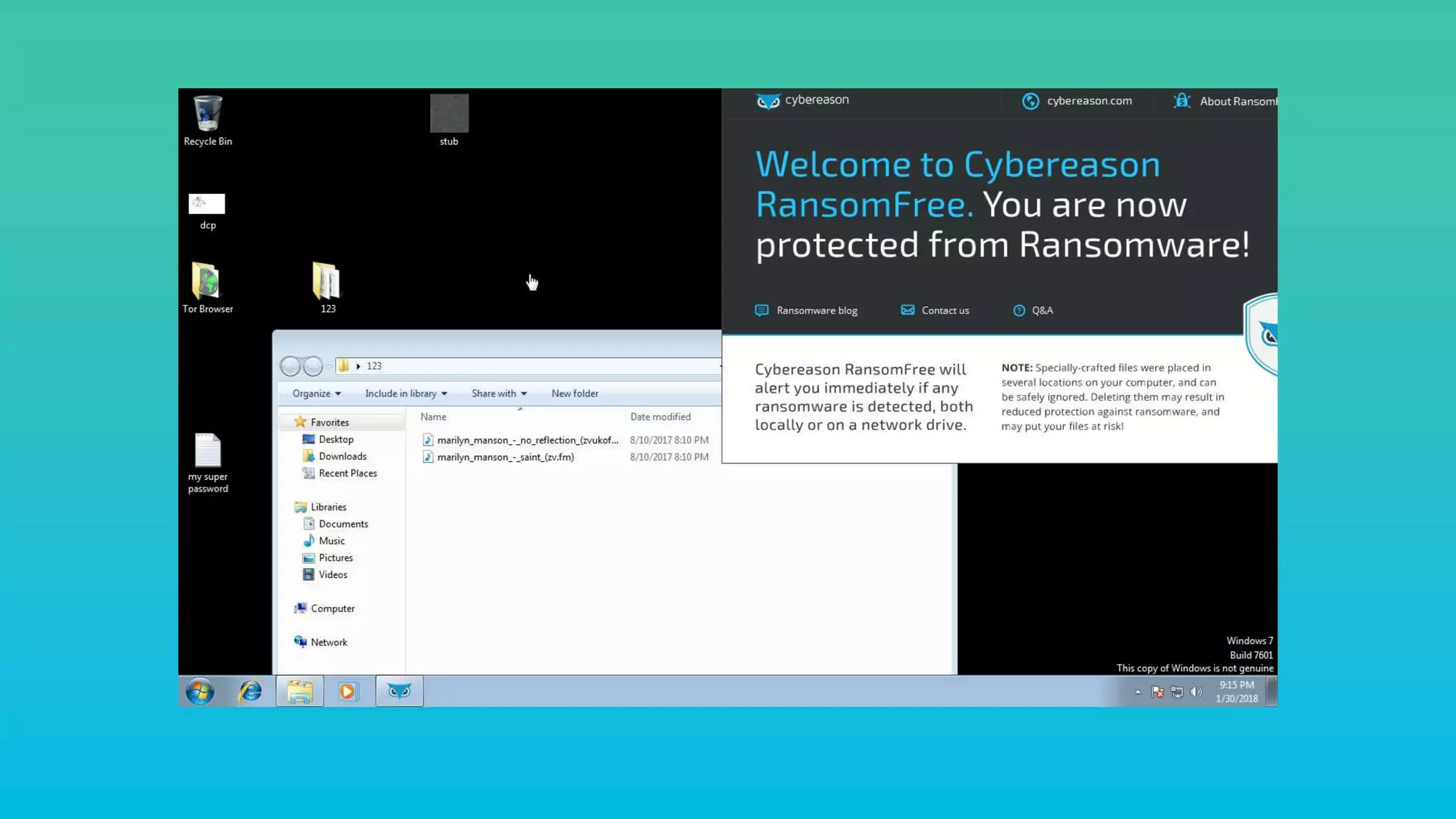

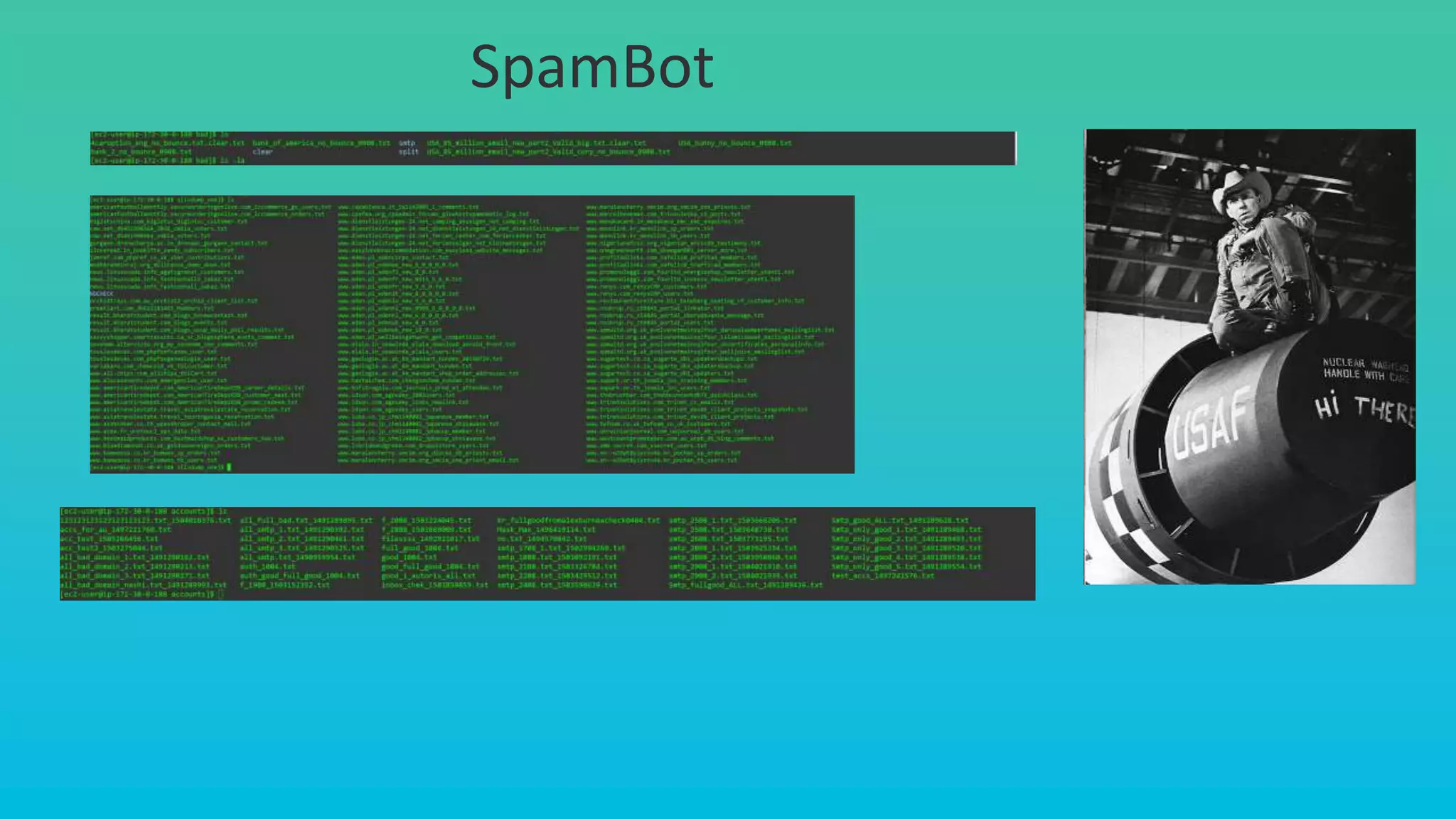











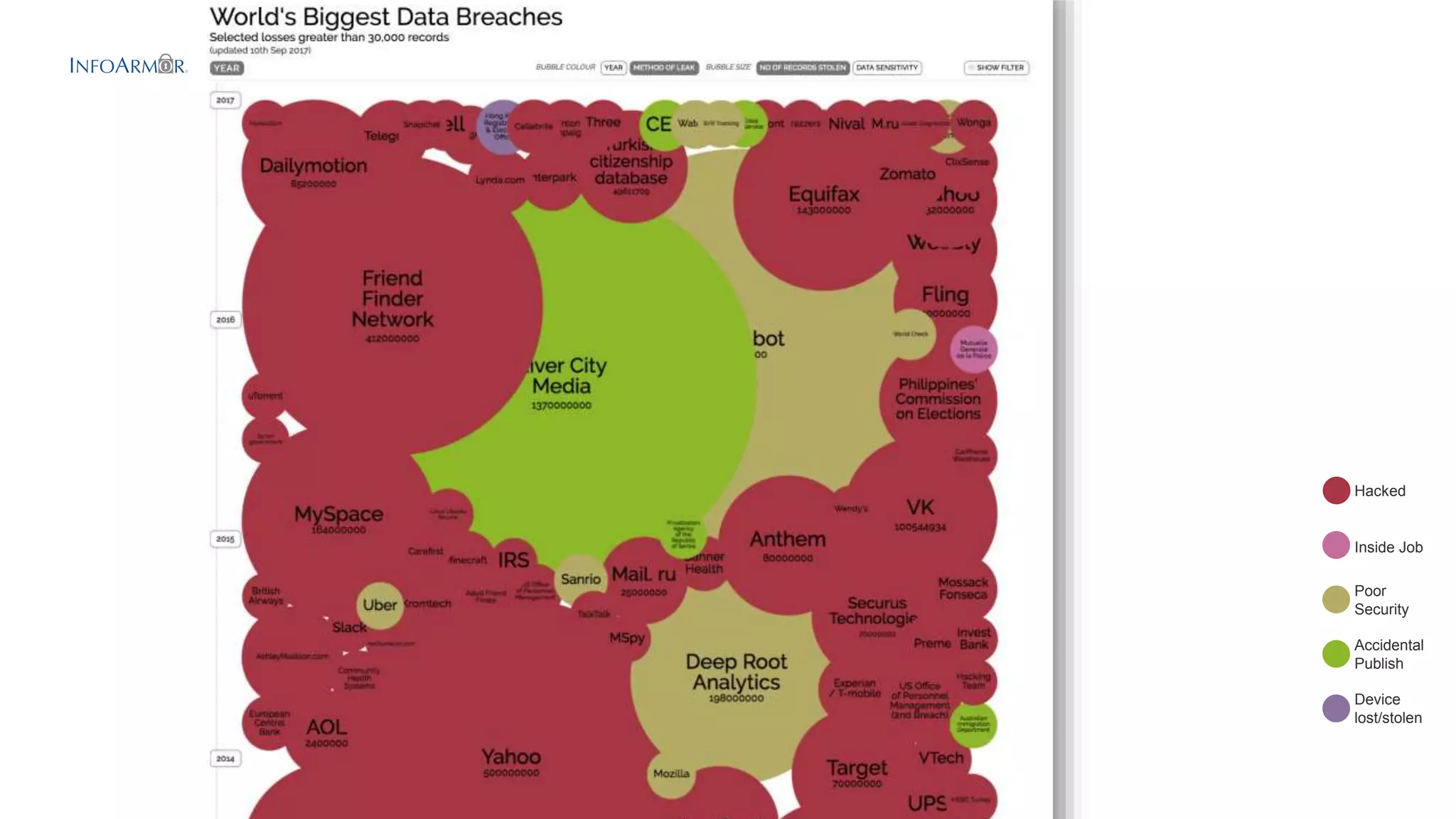
This document provides an overview of InfoArmor's threat intelligence and data ingestion capabilities. It begins with a brief history of InfoArmor and its vision for the future. It then discusses how threat data is collected from the dark web and other sources through techniques like forum scraping, human operatives, and threat actor profiling. The document also discusses lessons learned from processing over 1 billion rows of data in databases like Elasticsearch and MariaDB. It cautions against issues like poor schema design, not closing database connections, importing too much data at once, and allowing malicious scripts into databases. The key takeaways are that data should be ingested and processed incrementally and that remote DBAs can help manage infrastructure challenges.






































































![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)