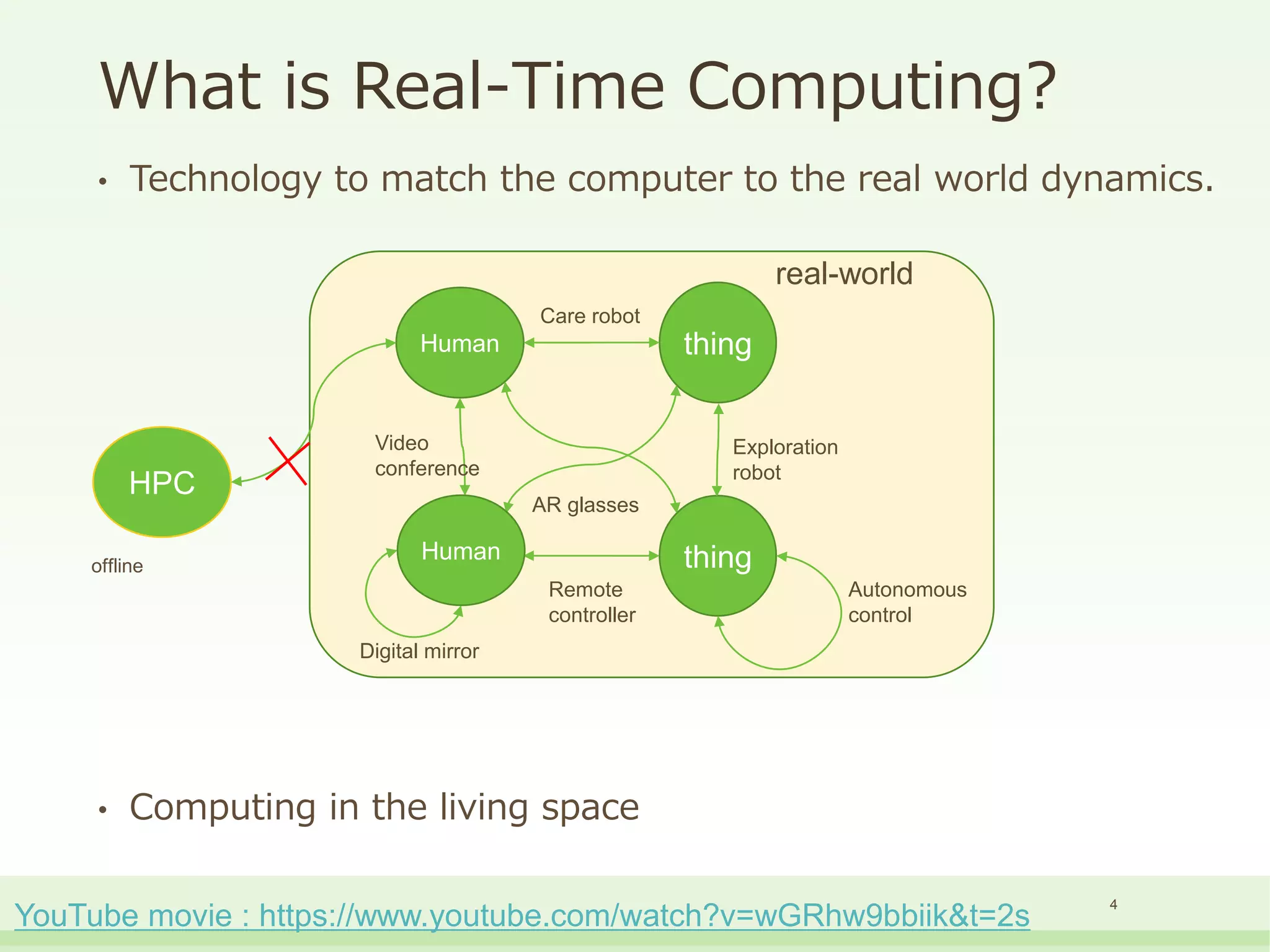
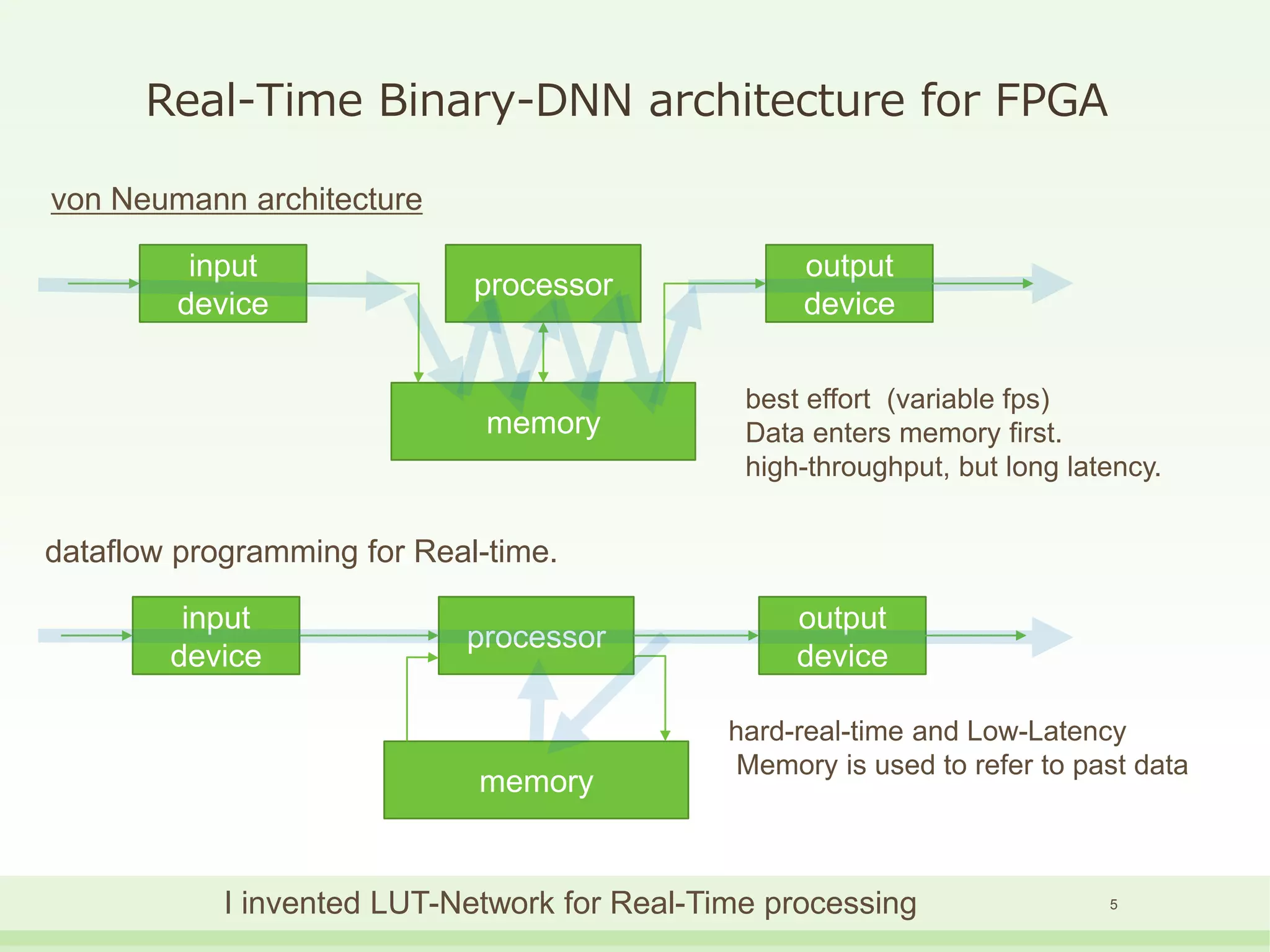
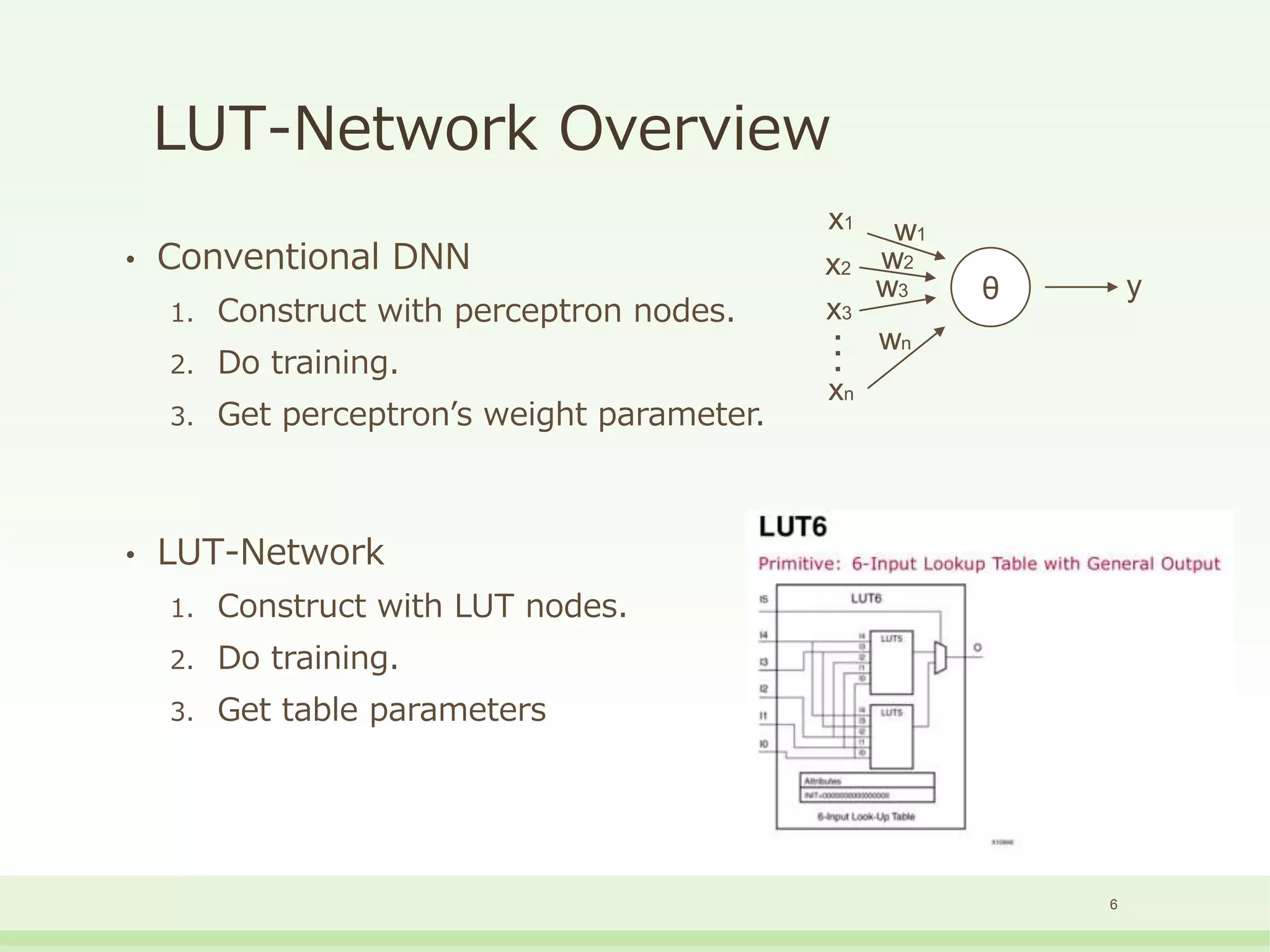
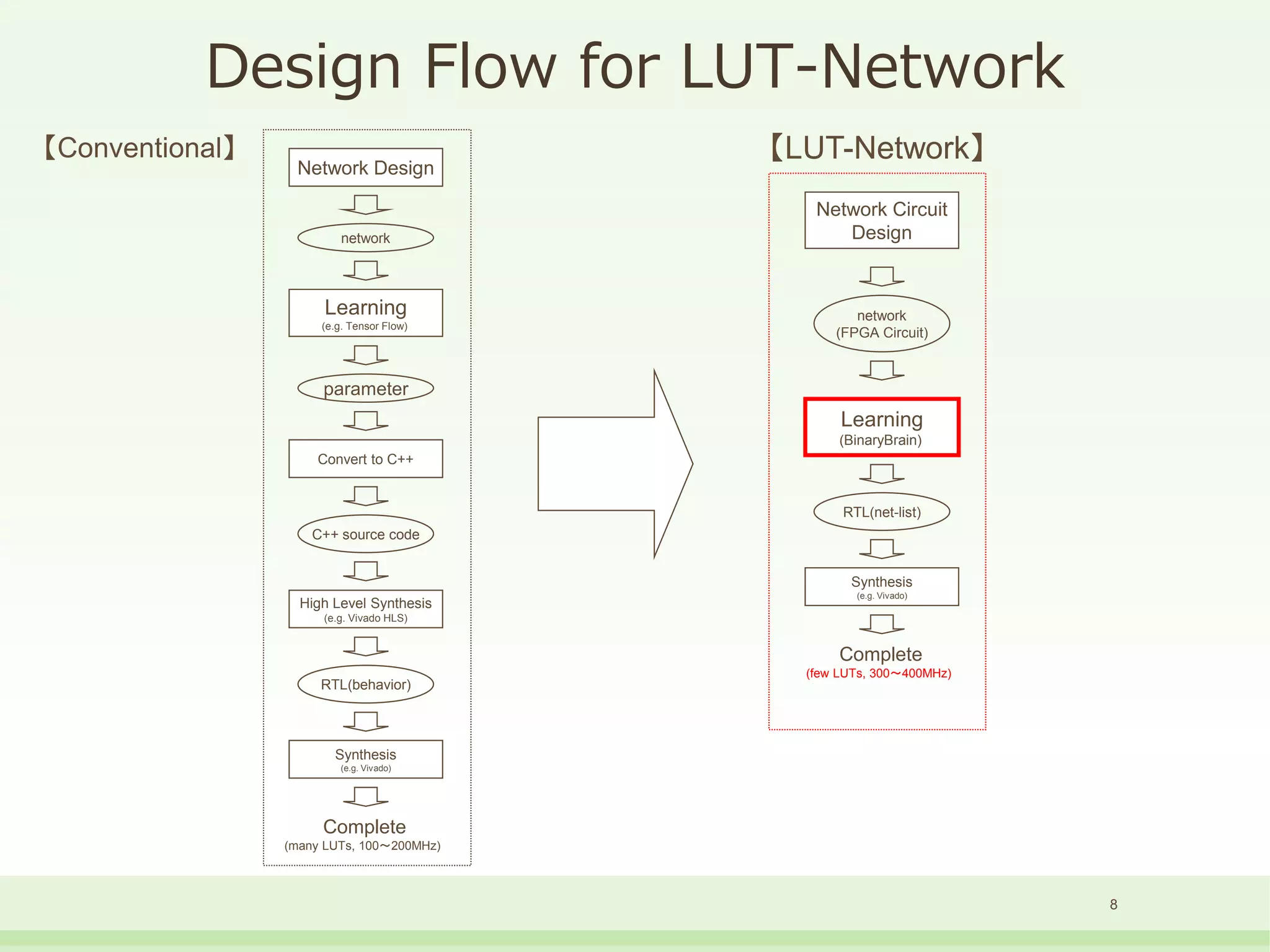
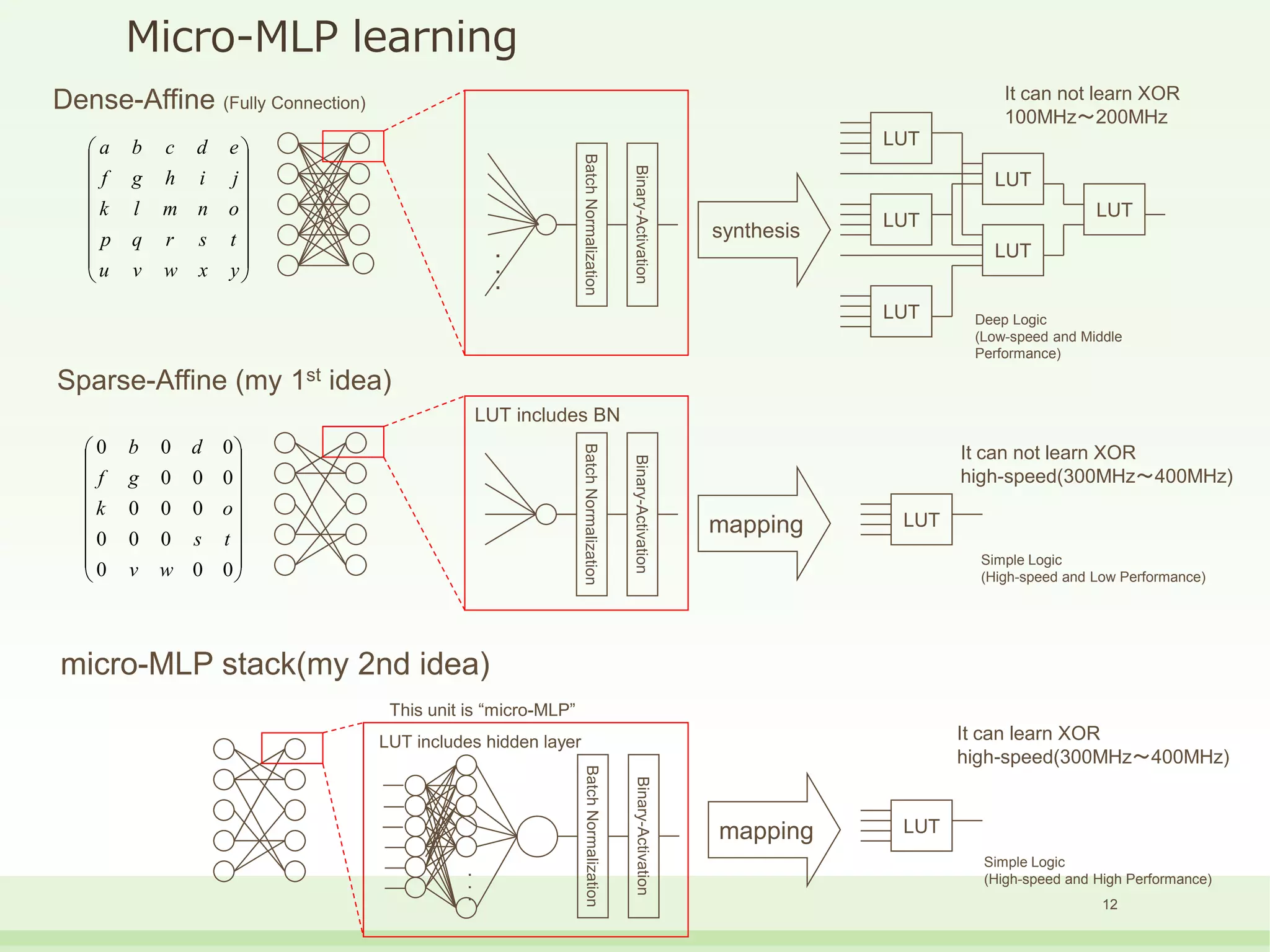
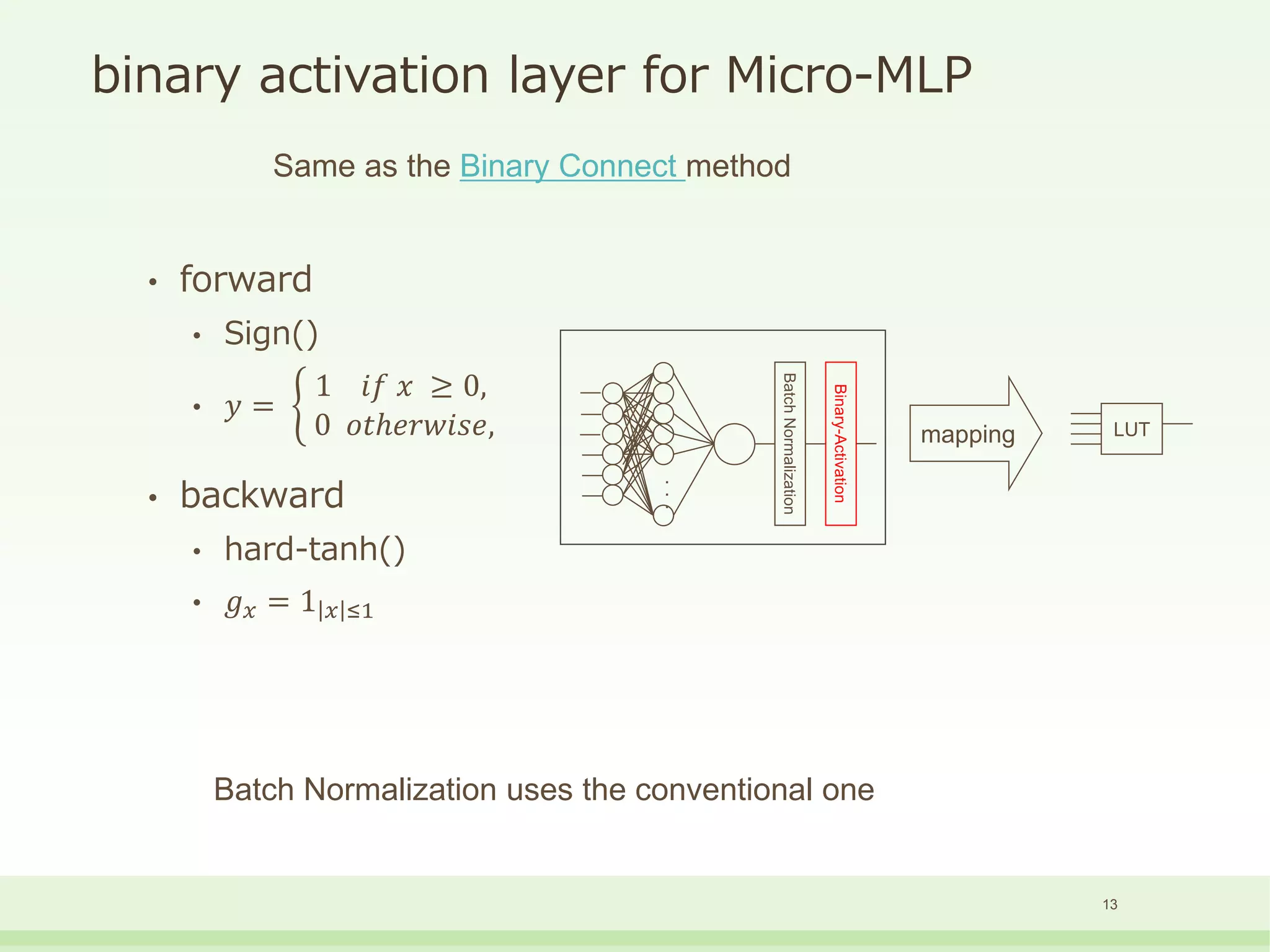
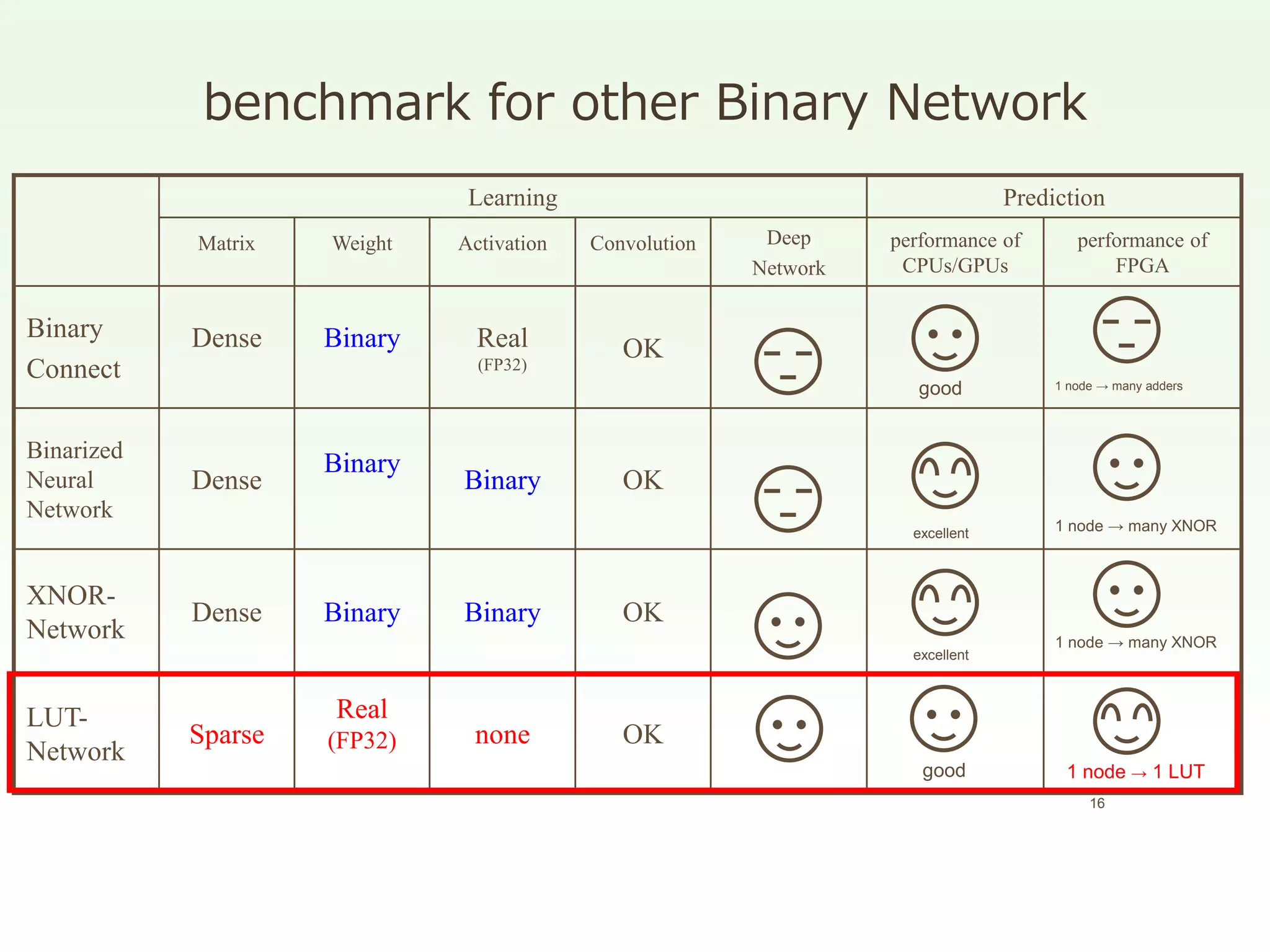
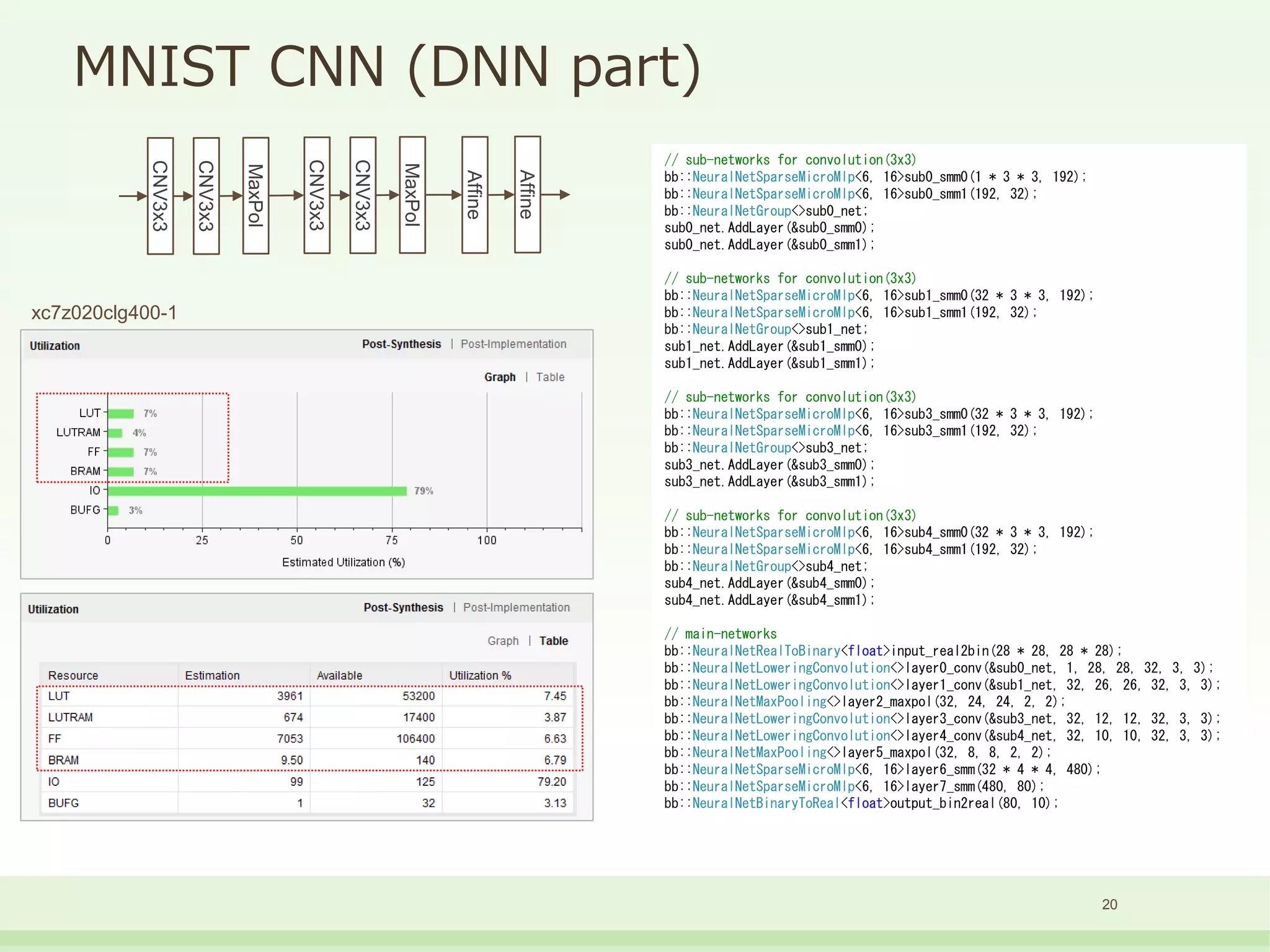
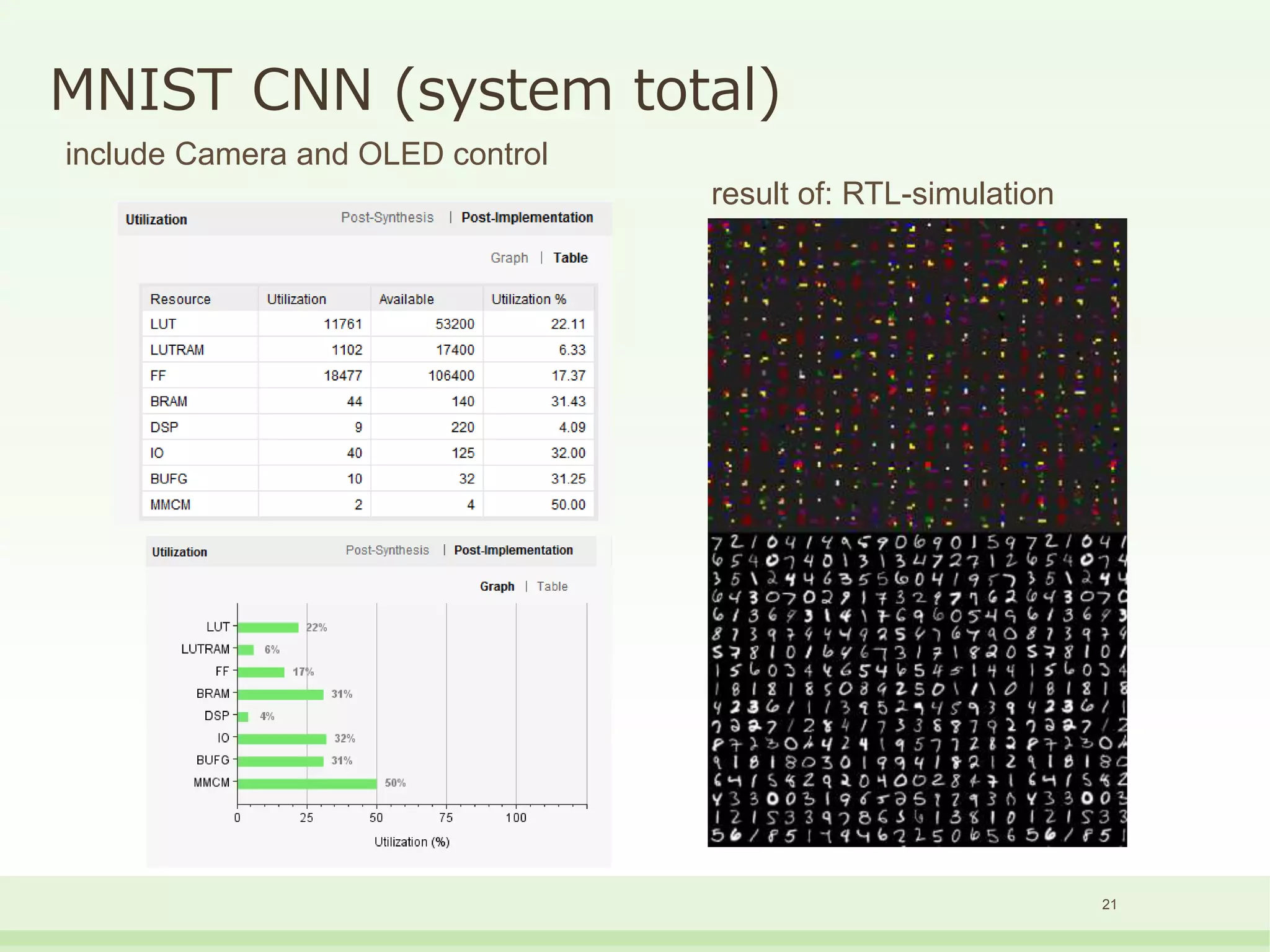
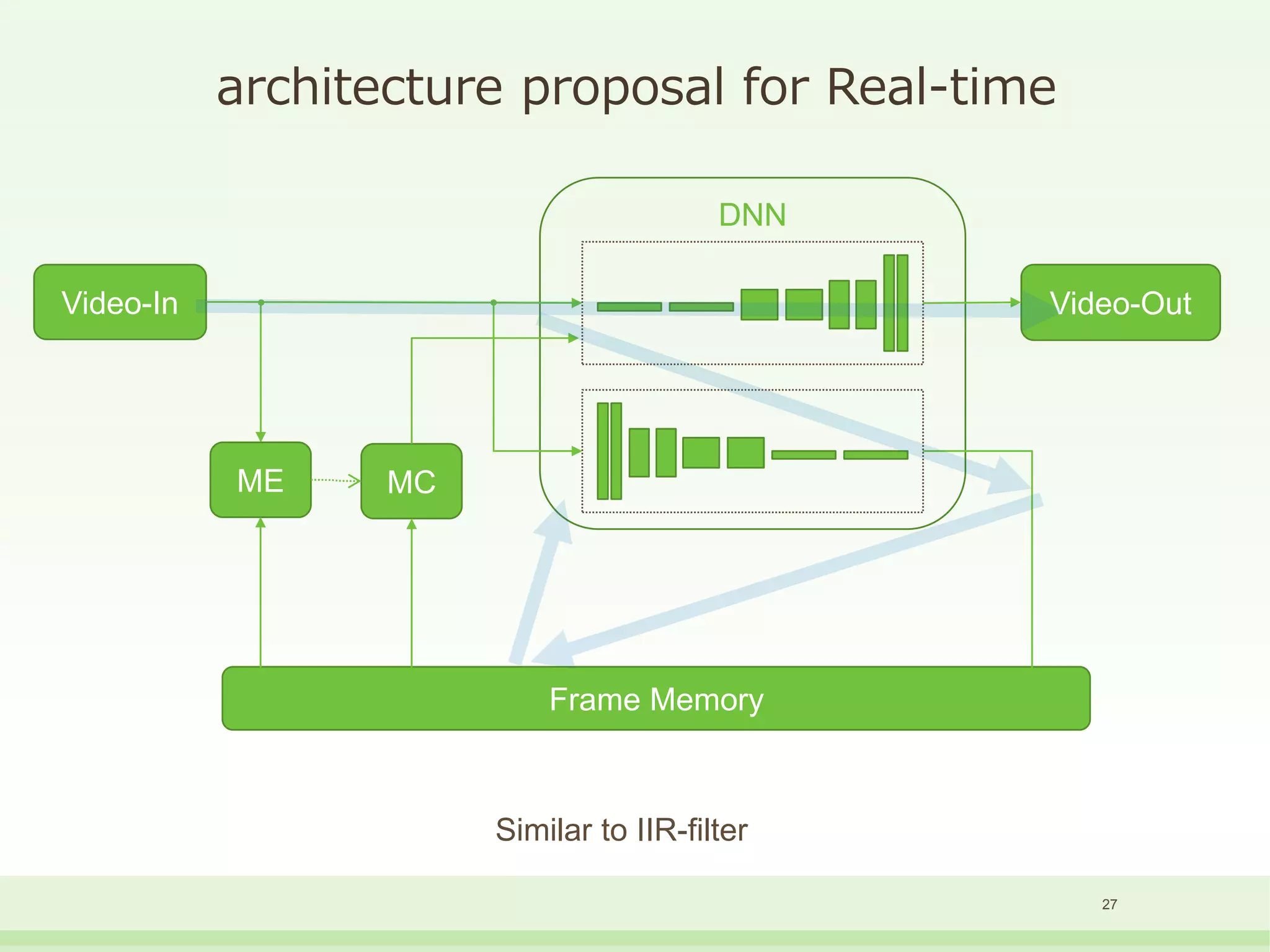
The document discusses the development and performance of the LUT-Network, a framework for real-time computing, focusing on binary learning models and architectures optimized for FPGA. It outlines the evolution of the BinaryBrain models, innovative techniques for training the networks, and their advantages in classification and regression tasks with minimal latency. The performance benchmarks highlight the speed and efficiency of the LUT-Network in various applications, including real-time recognition tasks.






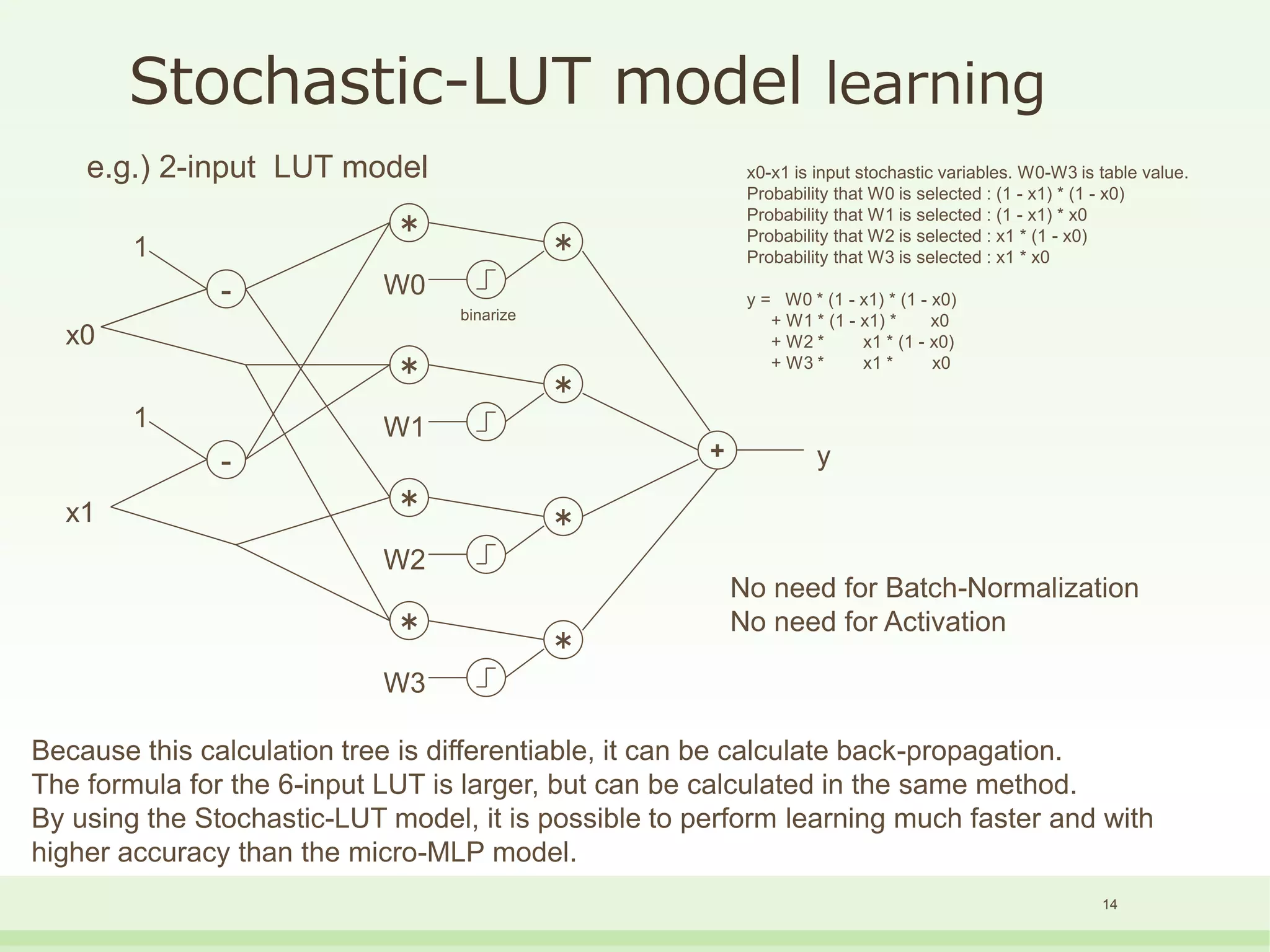
![Stochastic-LUT model
15
input[n-1:0]
output
Table with probability values as n-dimensional continuum](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-15-2048.jpg)
![Demonstration 1
[MNIST MLP 1000fps])
DNN
(LUT-Net)
MIPI-CSI
RX
Raspberry Pi
Camera V2
(Sony IMX219)
SERDE
S
TX
PS
(Linux)
SERDES
RX
FIN1216
DMA
OLED
UG-9664HDDAG01
DDR3
SDRA
M
I2C
MIPI-CSI
Original Board
PCX-Window
1000fps
640x132
1000fps
control
PL (Jelly)
BinaryBrain
Ether
RTL
offline learning (PC)
ZYBO Z7-20
debug view
17
YouTube movie: https://www.youtube.com/watch?v=NJa77PZlQMI](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-17-2048.jpg)

![DNN
(LUT-Net)
MIPI-CSI
RX
Raspberry Pi
Camera V2
(Sony IMX219)
SERDE
S
TX
PS
(Linux)
SERDES
RX
FIN1216
DMA
OLED
UG-9664HDDAG01
DDR3
SDRA
M
I2C
MIPI-CSI
Original Board
PCX-Window
1000fps
640x132
1000fps
control
PL (Jelly)
BinaryBrain
Ether
RTL
offline learning (PC)
ZYBO Z7-20
debug view
OSD
(frame-mem)
19
Demonstration 2
[MNIST CNN 1000fp]
YouTube movie : https://www.youtube.com/watch?v=aYuYrYxztBU](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-19-2048.jpg)
![MNIST CNN Learning log [micro-MLP]
fitting start : MnistCnnBin
initial test_accuracy : 0.1518
[save] MnistCnnBin_net_1.json
[load] MnistCnnBin_net.json
fitting start : MnistCnnBin
[initial] test_accuracy : 0.6778 train_accuracy : 0.6694
695.31s epoch[ 2] test_accuracy : 0.7661 train_accuracy : 0.7473
1464.13s epoch[ 3] test_accuracy : 0.8042 train_accuracy : 0.7914
2206.67s epoch[ 4] test_accuracy : 0.8445 train_accuracy : 0.8213
2913.12s epoch[ 5] test_accuracy : 0.8511 train_accuracy : 0.8460
3621.61s epoch[ 6] test_accuracy : 0.8755 train_accuracy : 0.8616
4325.83s epoch[ 7] test_accuracy : 0.8713 train_accuracy : 0.8730
5022.86s epoch[ 8] test_accuracy : 0.9086 train_accuracy : 0.8863
5724.22s epoch[ 9] test_accuracy : 0.9126 train_accuracy : 0.8930
6436.04s epoch[ 10] test_accuracy : 0.9213 train_accuracy : 0.8986
7128.01s epoch[ 11] test_accuracy : 0.9115 train_accuracy : 0.9034
7814.35s epoch[ 12] test_accuracy : 0.9078 train_accuracy : 0.9061
8531.97s epoch[ 13] test_accuracy : 0.9089 train_accuracy : 0.9082
9229.73s epoch[ 14] test_accuracy : 0.9276 train_accuracy : 0.9098
9950.20s epoch[ 15] test_accuracy : 0.9161 train_accuracy : 0.9105
10663.83s epoch[ 16] test_accuracy : 0.9243 train_accuracy : 0.9146
11337.86s epoch[ 17] test_accuracy : 0.9280 train_accuracy : 0.9121
fitting end
22micro MLP-model on BinaryBrain version2](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-22-2048.jpg)
![MNIST CNN Learning log[Stochastic-LUT]
fitting start : MnistStochasticLut6Cnn
72.35s epoch[ 1] test accuracy : 0.9508 train accuracy : 0.9529
153.70s epoch[ 2] test accuracy : 0.9581 train accuracy : 0.9638
235.33s epoch[ 3] test accuracy : 0.9615 train accuracy : 0.9676
316.71s epoch[ 4] test accuracy : 0.9647 train accuracy : 0.9701
398.33s epoch[ 5] test accuracy : 0.9642 train accuracy : 0.9718
479.71s epoch[ 6] test accuracy : 0.9676 train accuracy : 0.9731
・
・
・
2111.04s epoch[ 26] test accuracy : 0.9699 train accuracy : 0.9786
2192.82s epoch[ 27] test accuracy : 0.9701 train accuracy : 0.9788
2274.26s epoch[ 28] test accuracy : 0.9699 train accuracy : 0.9789
2355.97s epoch[ 29] test accuracy : 0.9699 train accuracy : 0.9789
2437.39s epoch[ 30] test accuracy : 0.9696 train accuracy : 0.9791
2519.13s epoch[ 31] test accuracy : 0.9698 train accuracy : 0.9793
2600.71s epoch[ 32] test accuracy : 0.9695 train accuracy : 0.9792
fitting end
parameter copy to LUT-Network
lut_accuracy : 0.9641
export : verilog/MnistStochasticLut6Cnn.v
23
Stochastic-LUT model on BinaryBrain version3](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-23-2048.jpg)
![Linear Regression [Stochastic-LUT]
(diabetes data from scikit-learn)
fitting start : DiabetesRegressionStochasticLut6
[initial] test MSE : 0.0571 train MSE : 0.0581
0.97s epoch[ 1] test MSE : 0.0307 train MSE : 0.0344
1.42s epoch[ 2] test MSE : 0.0209 train MSE : 0.0284
1.87s epoch[ 3] test MSE : 0.0162 train MSE : 0.0270
2.32s epoch[ 4] test MSE : 0.0160 train MSE : 0.0261
・
・
・
27.11s epoch[ 59] test MSE : 0.0146 train MSE : 0.0245
27.55s epoch[ 60] test MSE : 0.0195 train MSE : 0.0256
27.99s epoch[ 61] test MSE : 0.0145 train MSE : 0.0231
28.43s epoch[ 62] test MSE : 0.0133 train MSE : 0.0232
28.87s epoch[ 63] test MSE : 0.0940 train MSE : 0.0903
29.30s epoch[ 64] test MSE : 0.0146 train MSE : 0.0233
fitting end
parameter copy to LUT-Network
LUT-Network accuracy : 0.0340518
export : DiabetesRegressionBinaryLut.v
24Stochastic-LUT model on BinaryBrain version3](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-24-2048.jpg)
![Learning prediction
operator
CPU
1Core
operator
CPU 1Core
(1 weight calculate instructions)
FPGA
(XILIN 7-Series)
ASIC
multi-cycle pipeline multi-cycle pipeline
Affine
(Float)
Multiplier
+ adder
0.25
cycle
Multiplier
+ adder
0.125 cycle
(8 parallel [FMA])
[MUL] DSP:2
LUT:133
[ADD] LUT:413
左×node数 gate : over 10k gate : over 10M
Affine
(INT16)
Multiplier
+ adder
0.125
cycle
Multiplier
+ adder
0.0625 cycle
(16 parallel)
[MAC] DSP:1 左×node数 gate : 0.5k~1k gate : over 1M
Binary
Connect
Multiplier
+ adder
0.25
cycle
adder
+adder
0.125 cycle
(8 parallel)
[MAC] DSP:1 左×node数 gate : 100~200 左×node数
BNN/
XNOR-Net
Multiplier
+ adder
0.25
cycle
XNOR
+popcnt
0.0039+0.0156 cycle
(256 parallel)
LUT:6~12
LUT:400~10000
(接続数次第)
gate : 20~60 左×node数
6-LUT-Net
Multiplier
+ adder
23.8
cycle
LUT
1.16 cycle
(6 input load
+ 1 table load) / 6
(256 parallel)
LUT : 1
(over spec)
LUT : 1
(fit)
gate : 10~30
(over spec)
gate : 10~30
2-LUT-Net
Multiplier
+ adder
1.37
cycle
logic-gate
1.5 cycle
(2 input load
+ 1 table load) / 2
LUT : 1
(over spec)
LUT : 1
(over spec)
gate : 1
(over spec)
gate : 1
(fit)
Resource estimate
25](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-25-2048.jpg)



![My Profile
• Open source programmer (hobbyist)
• Born in 1976, I’m living in Fukuoka-city, Japan
• 1998~ publish HOS (Real-Time OS [uITRON])
• https://ja.osdn.net/projects/hos/
(ARM,H8,SH,MIPS,x86,Z80,AM,V850,MicroBlaze, etc.)
• 2008~ publish Jell (Soft-core CPU for FPGA)
• https://github.com/ryuz/jelly
• http://ryuz.my.coocan.jp/jelly/toppage.html
• 2018~ publish LUT-Network
• https://github.com/ryuz/BinaryBrain
• Real-Time AR-glasses project(current my hobby)
• Real-Time glasses (camera [IMX219] & OLED 1000fps)
https://www.youtube.com/watch?v=wGRhw9bbiik
• Real-Time GPU (no frame buffer architecture)
https://www.youtube.com/watch?v=vl-lhSOOlSk
• Real-Time DNN (LUT-Network)
https://www.youtube.com/watch?v=aYuYrYxztBU
30](https://image.slidesharecdn.com/lut-networkenglish201904-190409103146/75/LUT-Network-Revision2-English-version-30-2048.jpg)
























































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)


