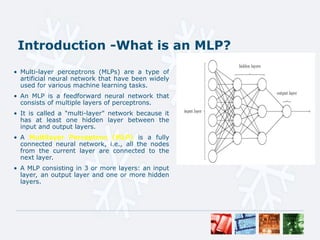
Multi-layer perceptrons (MLPs) are a type of artificial neural network used in machine learning, characterized by their multiple layers including at least one hidden layer. MLPs are trained using the backpropagation learning algorithm, which adjusts weights based on errors from predicted and actual outputs. They are effective classifiers across various domains, such as optical character recognition and image classification tasks like those involving the MNIST dataset.




![Backpropagation Learning Algorithm
4 September 2024
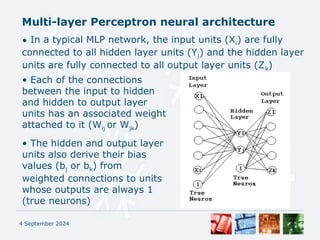
Feed Forward phase:
• Xi = input[i]
• Yj = f( bj + XiWij)
• Zk = f( bk + YjWjk)
Backpropagation of errors:
• k = Zk[1 - Zk](dk - Zk)
• j = Yj[1 - Yj] k Wjk
Weight updating:
• Wjk(t+1) = Wjk(t) + kYj + [Wjk(t) - Wjk(t - 1)]
• bk(t+1) = bk(t) + kYtn + [bk(t) - bk(t - 1)]
• Wij(t+1) = Wij(t) + jXi + [Wij(t) - Wij(t - 1)]
• bj(t+1) = bj(t) + jXtn + [bj(t) - bj(t - 1)]](https://image.slidesharecdn.com/assignment03-ml-240904014212-eec09711/85/assignment-regarding-the-security-of-the-cyber-6-320.jpg)



![Training an MLP on MNIST-Image
Classification
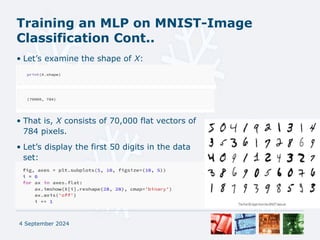
• The data set contains 60,000 training images and 10,000 testing
images of handwritten digits. Each image is 28 × 28 pixels in size,
and is typically represented by a vector of 784 numbers in the range
[0, 255]. The task is to classify these images into one of the ten
digits (0–9).
• We first fetch the MNIST data set using the fetch_openml()
function:
• The as_frame parameter specifies that we want to get the data and
the labels as NumPy arrays instead of DataFrames (the default of
this parameter has changed in Scikit-Learn 0.24 from False to
‘auto’).
4 September 2024](https://image.slidesharecdn.com/assignment03-ml-240904014212-eec09711/85/assignment-regarding-the-security-of-the-cyber-10-320.jpg)
![Training an MLP on MNIST-Image
Classification Cont..
• Let’s check how many samples we have from each digit:
• The data set is fairly balanced between the 10 classes.
• We now scale the inputs to be within the range [0, 1] instead of [0,
255]:
• Feature scaling makes the training of neural networks faster and
prevents them from getting stuck in local optima.
4 September 2024](https://image.slidesharecdn.com/assignment03-ml-240904014212-eec09711/85/assignment-regarding-the-security-of-the-cyber-12-320.jpg)




![Visualizing the MLP Weights
• Although neural networks are generally considered to be “black-box”
models, in simple networks that consist of one or two hidden layers, we
can visualize the learned weights and occasionally gain some insight into
how these networks work internally.
• For example, let’s plot the weights between the input and the hidden
layers of our MLP classifier. The weight matrix has a shape of (784,
300), and is stored in a variable called mlp.coefs_[0]:
• Column i of this matrix represents the weights of the incoming inputs to
hidden neuron i. We can display this column as a 28 × 28 pixel image,
in order to examine which input neurons have a stronger influence on
this neuron’s activation.
4 September 2024](https://image.slidesharecdn.com/assignment03-ml-240904014212-eec09711/85/assignment-regarding-the-security-of-the-cyber-17-320.jpg)

















































