More Related Content

PDF
Deep learningの概要とドメインモデルの変遷 
PPT

PPTX

PPTX

PPTX

PDF
A deep relevance model for zero shot document filtering 
PPTX

PPTX
Similar to Deep Learning development flow

PDF

PPTX
2018/3/23 Introduction to Deep Learning by Neural Network Console 
PPTX
2018/6/26 deep learning Neural Network Console hands-on 
PPTX
「機械学習とは?」から始める Deep learning実践入門 
PPTX

PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」) 
PDF
深層学習の新しい応用と、 それを支える計算機の進化 - Preferred Networks CEO 西川徹 (SEMICON Japan 2022 Ke... 
PPTX
20190316_Let's try low power-consumption ai with sony's spresense hands-on 
PPTX
2017-05-30_deepleaning-and-chainer 
PDF
MANABIYA Machine Learning Hands-On 
PPTX
2018/07/26 Game change by Deep Learning and tips to make a leap 
PDF

PDF
20160913 gpu deep-learningcomminity-morpho_20160912-公開用rev2 
PDF
DAシンポジウム2019招待講演「深層学習モデルの高速なTraining/InferenceのためのHW/SW技術」 金子紘也hare 
PPTX
令和元年度 実践セミナー - Deep Learning 概論 - 
PPTX
DLモデル開発中の雑務が嫌で支援プラットフォームを作った話 
PDF
TAI_GDEP_Webinar_1a_27Oct2020 
PPTX

PDF

PDF
More from ryuz88

PPTX

PPTX

PDF
Fast and Light-weight Binarized Neural Network Implemented in an FPGA using L... 
PPTX
LUT-Network Revision2 -English version- 
PPTX
LUT-Network ~本物のリアルタイムコンピューティングを目指して~ 
PPTX
LUT-Network その後の話(2022/05/07) 
PPTX
LUT-Network ~Edge環境でリアルタイムAIの可能性を探る~ 
PDF

PPTX
Deep Learning development flow
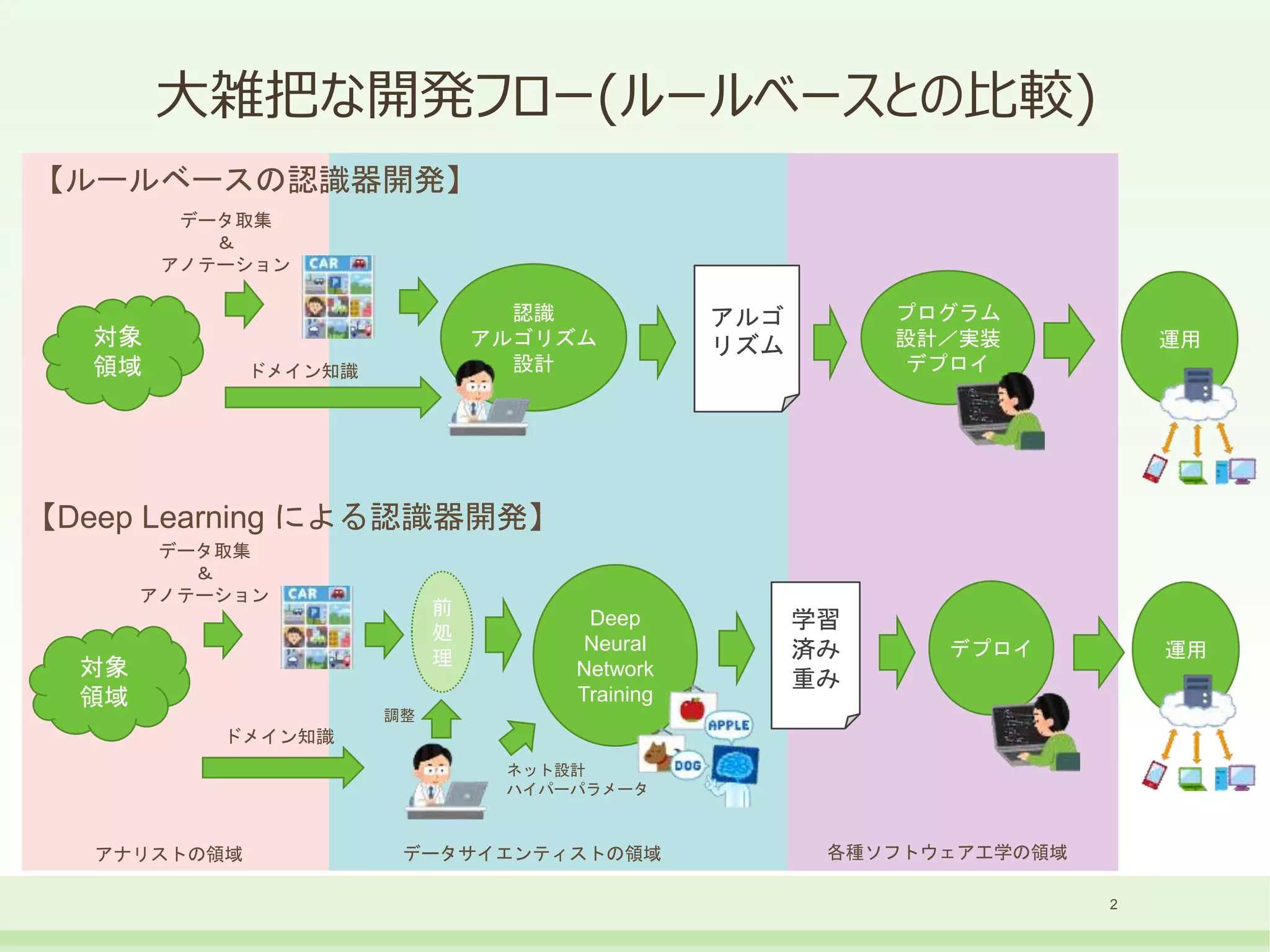
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
まとめ
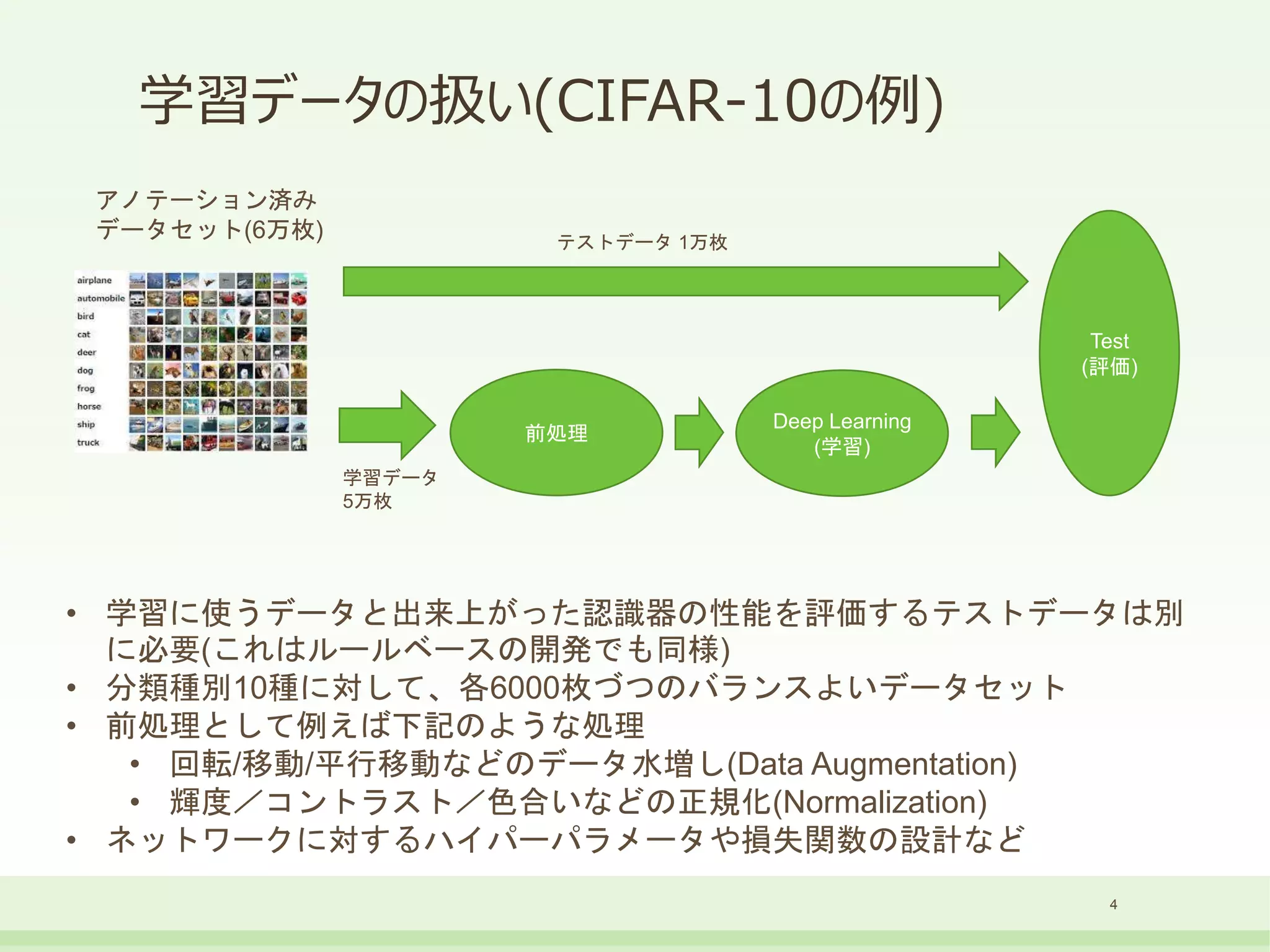
• ニューラルネットは入力した学習データの情報のみで学習する
• 与えられたデータから補間できる範囲でしか機能しない
•偏ったデータでは偏った学習しかしない
• 人間が無意識に「当たり前」と思う部分は一切反映されない。データのみで決まる
• 学習によりどのようなAIに育てたいかは対象ドメインの人間しか知りえない
• データサイエンティストはしばし対象ドメインの専門家ではない
• 対象ドメインの人間の機械学習への理解と協力が必須
• データサイエンティストとは別に、業務分析などを専門とするアナリストの領域も重要
• 学習データセットに人間の知見を入れる事も必要
• データの前処理/前加工によって、人間の持つ知見でデータを拡張する
• 最終的に欲しい結果の重要性や優先度を損失関数などに反映する
6