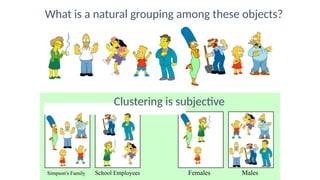
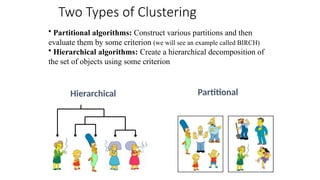
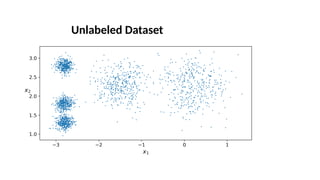
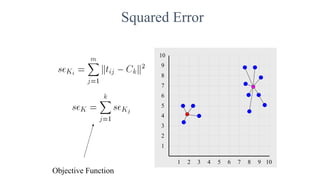
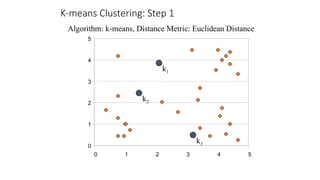
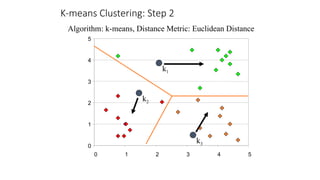
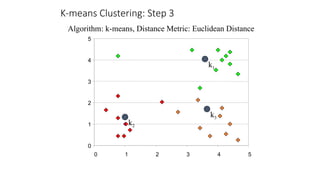
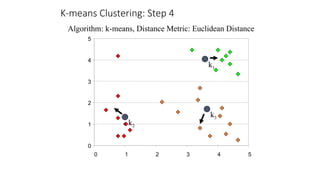
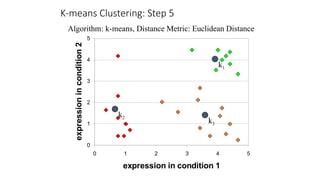
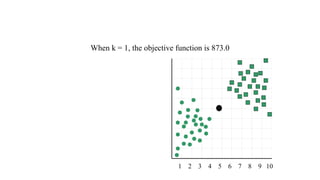
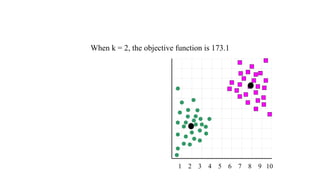
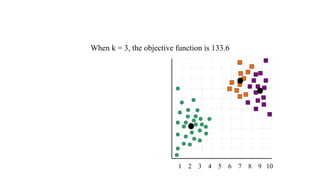
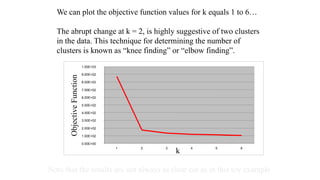
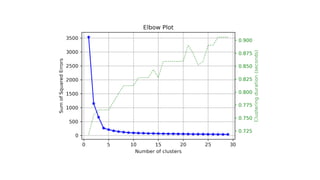
The document focuses on clustering, an unsupervised learning technique used for grouping data objects based on similarity to find natural groupings without predefined class labels. It details various clustering types, specifically k-means and hierarchical algorithms, along with the process of applying k-means, its strengths, weaknesses, and methods for determining the appropriate number of clusters. The presentation emphasizes practical applications and understanding of clustering concepts, reinforced by examples and graphical representations.






![After clustering (Decision Boundaries)
[Also called Voronoi diagram or Voronoi
tesselation]](https://image.slidesharecdn.com/lecture9-clustering-241130190810-bef123b9/85/Lecture-9-Clustering-ML-algorithms-Clustering-KNN-DBScan-pptx-10-320.jpg)













![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)









![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)




























