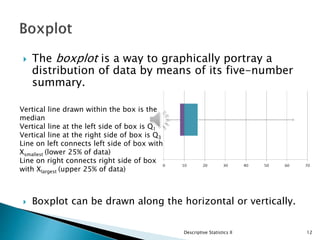
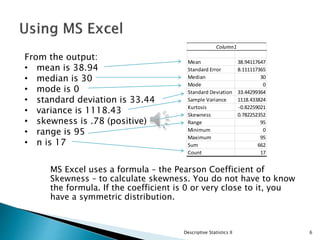
This document provides an overview of descriptive statistics, focusing on the concepts of data shape, skewness, and methods for calculating and visualizing these properties using tools like MS Excel. It details how to compute z-scores, create frequency distributions, and analyze graphical representations such as boxplots and histograms. Additionally, it discusses the importance of understanding data distribution, skewness, and relationship analysis through correlation and regression.








![ No matter what you are measuring, a Z-score of
more than +5 or less than – 5 would indicate a
very, very unusual score.
For standardized data, if it is normally distributed,
95% of the data will be between ±2 standard
deviations about the mean.
If the data follows a normal distribution,
◦ 95% of the data will be between -1.96 and +1.96.
◦ 99.7% of the data will fall between -3 and +3.
◦ 99.99% of the data will fall between -4 and +4.
Worst case scenario: 75% of the data are between 2
standard deviations about the mean.
[Chebychev.]
Descriptive Statistics II 10](https://image.slidesharecdn.com/descriptivesiilecture-220703222717-8681d8eb/85/Lecture-2-Descriptive-statistics-pptx-10-320.jpg)