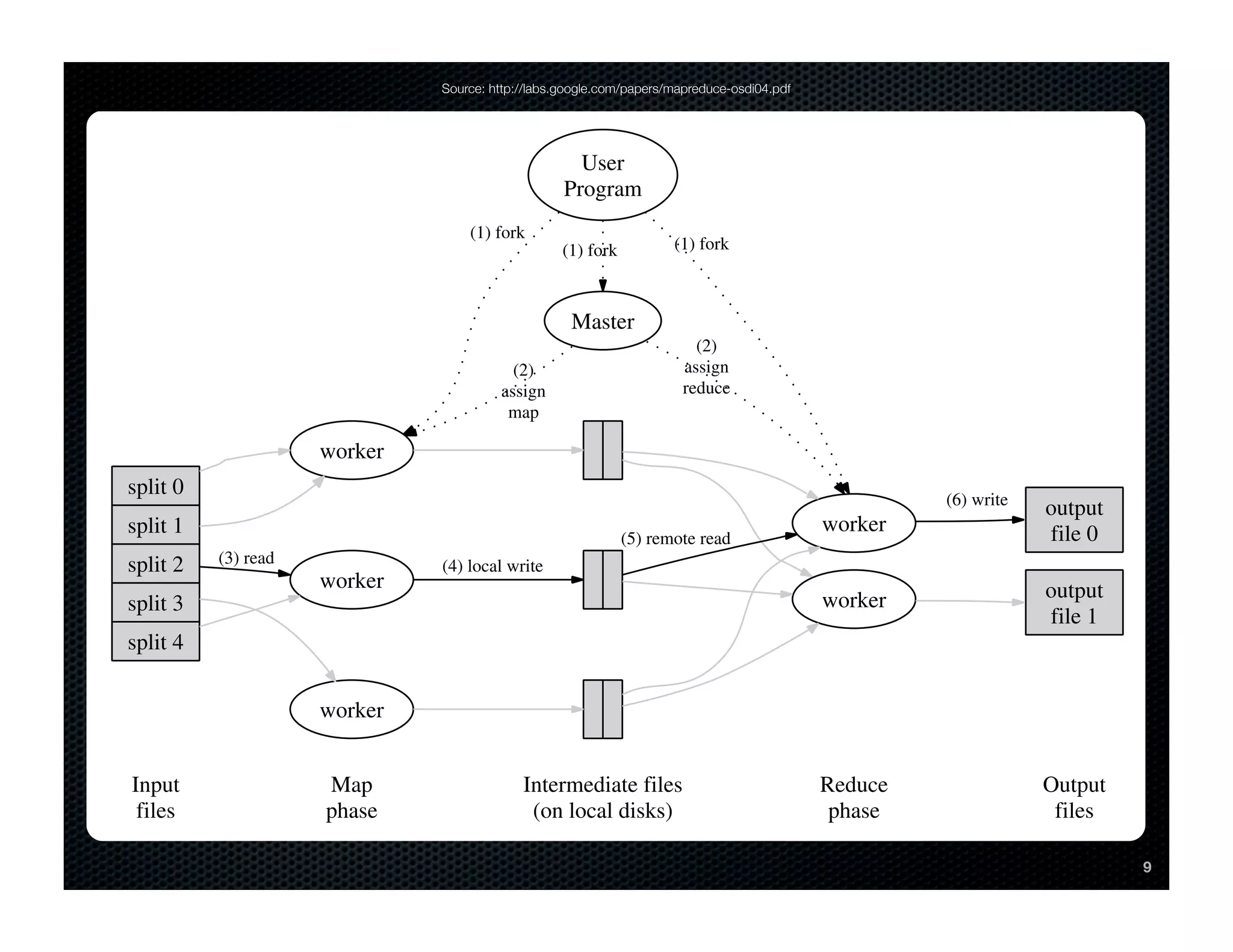
This document provides an introduction to MapReduce and Disco, an open source implementation of MapReduce in Erlang and Python. It explains the motivation for MapReduce frameworks like Google's in addressing the need to process massive amounts of data across large clusters reliably. The core concepts of MapReduce are described, including how the input is split and mapped in parallel, intermediate key-value pairs are grouped and reduced, and the final output is produced. An example word counting algorithm demonstrates how a problem can be solved using MapReduce.