How Can IDo?
• My machine already studied MNIST
• However, I want to make the machine solve the below
problem
• I should teach the machine to classify “+” and “=“. How??
Learning without Forgetting
•Recording responses yo on each new task image from the
original network for outputs on the old tasks(defined by θs
and θo)
• Nodes for each new class are added to the output layer with
randomly initialized weights θn(# of new classes x # of nodes
in the last shared layer)
• Training the network to minimize loss for all tasks and
regularization R using stochastic gradient descent
• First, freezing θs and θo and train θn to convergence. Then,
jointly training all weights until convergence
Toy Example
• CIFAR-10dataset
60,000개 32x32x3 image
50,000 for training, 10,000 for testing
10개 class
22.
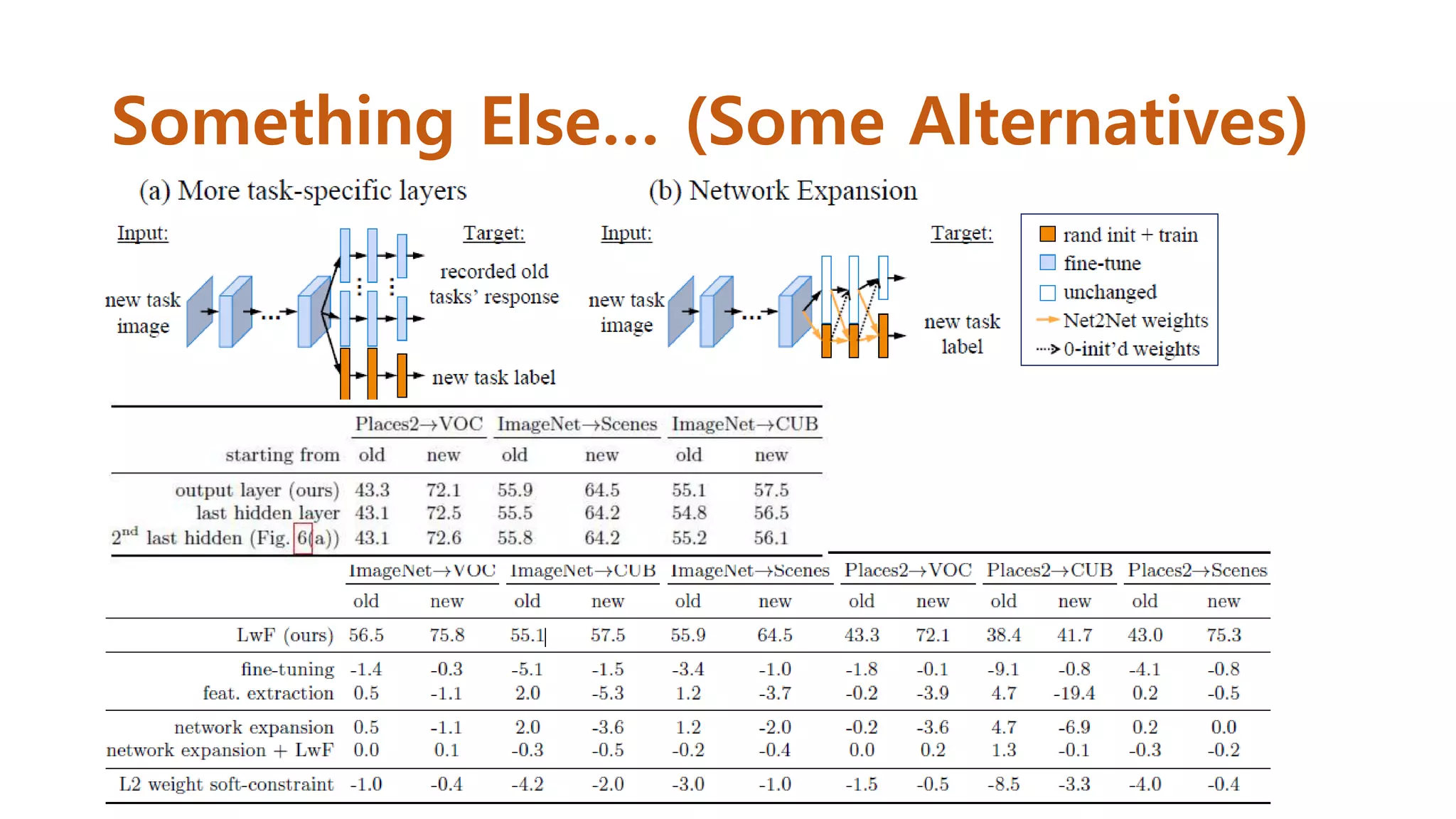
Experiment #1
• 학습데이터를 40,000(group 1), 10,000(group 2)로 구성
• Group 1로 network 학습(test는 group 2)
• 학습된 weights를 initial weights로 하여 group 2를 다시 학습
23.
Why?
• 새로운 dataset의size가 너무 작아서 새로운 dataset에 적응하
면서 generalization의 능력을 잃어버리는 게 아닐까???
24.
Experiment #2
• 학습데이터를 30,000(group 1), 30,000(group 2)로 구성
• Group 1로 network 학습(test는 group 2)
• 학습된 weights를 initial weights로 하여 group 2를 다시 학습
25.
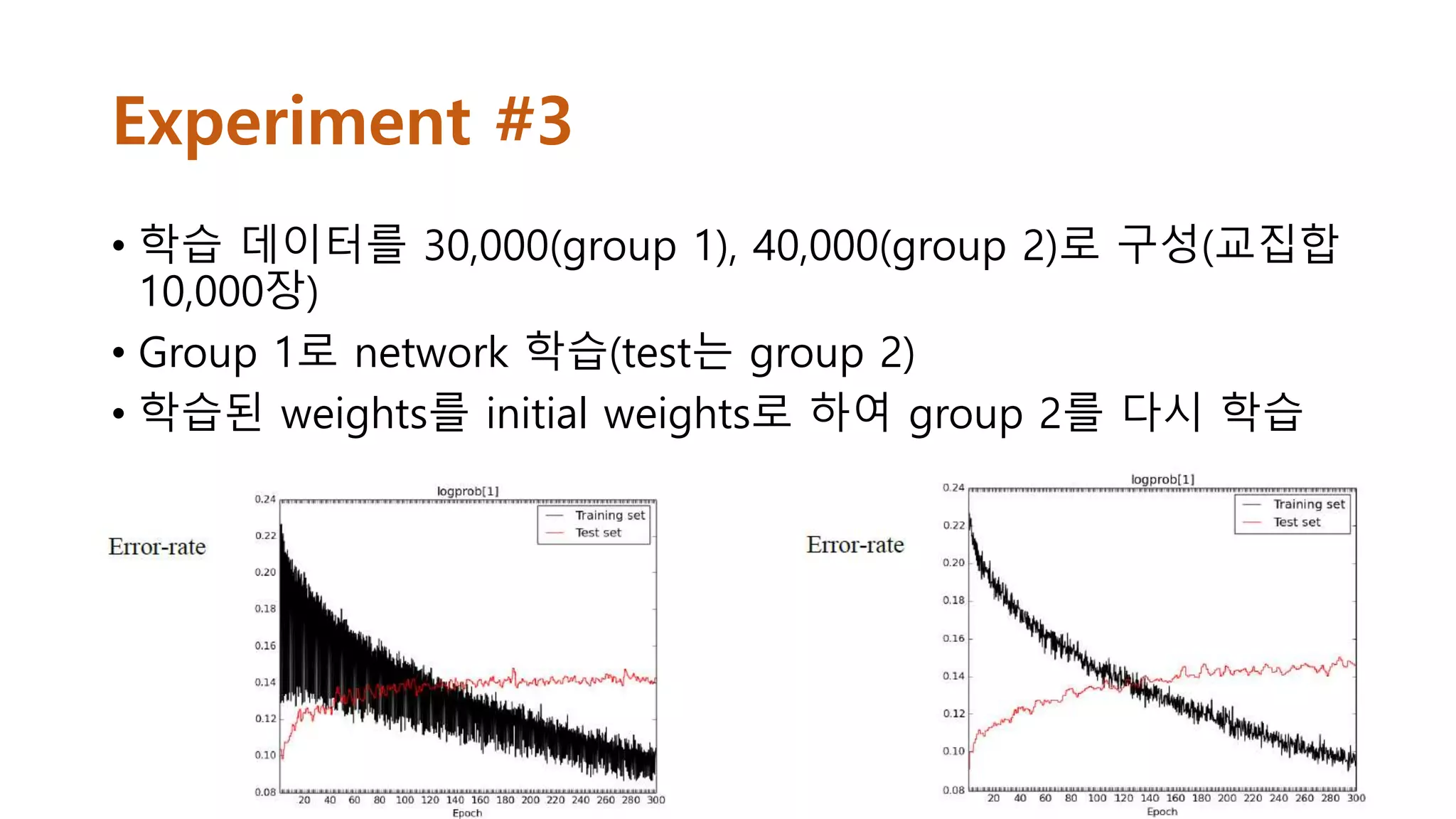
Experiment #3
• 학습데이터를 30,000(group 1), 40,000(group 2)로 구성(교집합
10,000장)
• Group 1로 network 학습(test는 group 2)
• 학습된 weights를 initial weights로 하여 group 2를 다시 학습
26.
Observation & Goal
•Observation
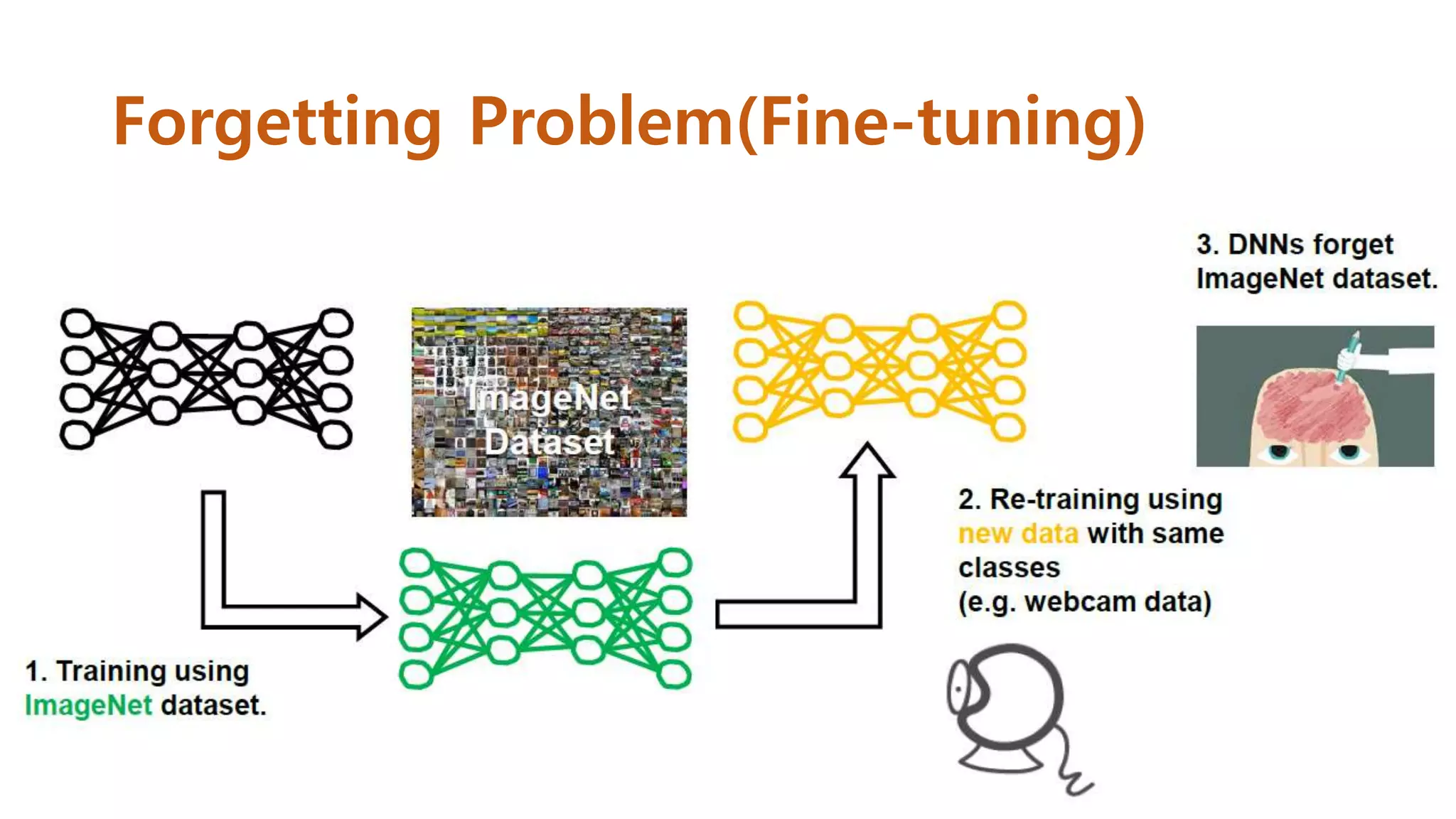
Fine-tuning은 새로운 dataset으로 학습 시, 기존의 dataset에 대한 성
능이 저하되는 문제가 있음
기존 data와 새로운 data가 많이 다르지 않고, 양이 많다면 성능이 덜
저하됨
기존 data 중 일부를 이용할 수 있다면 좀 더 성능 저하를 막을 수 있음.
• Goal
이전 dataset을 다시 학습하지 않고, 새로운 dataset으로 fine-tuning
후에도 기존의 dataset에 대해 인식률 저하가 일어나지 않는 기법 개발
Less Forgetting Learning
•새로운 내용을 학습하더라도 기존에 학습한 것을 덜 잊어버리
도록 하는 learning 기법
Source data : 기존 환경의 data
Target data : 새로운 환경의 data
Source network : 기존 환경에 대해 학습한 network
Target network : 새 환경에 대해 학습할 network
29.
New Learning Schemefor Forgetting
Less
• Property 1
Target data를 학습하고 난 후에도 decision boundary가 변하지 않아
야 함
• Property 2
Target network에서 추출된 source data의 high level feature들이 같은
class의 source feature들과 feature space에서 비슷한 위치에 분포하여
야 함
• Source data에 접근할 수 없음
30.
New Learning Scheme
•Property 1 구현 – Softmax layer의 weights를 freezing
• Property 2 구현 – 두 가지 loss functio을 정의
Softmax loss
Euclidean loss
• Input layer에 target data가 입력됨
31.
Algorithm Details
Ni andNb in the algorithm denote the number of iterations
and the size of mini-batch.
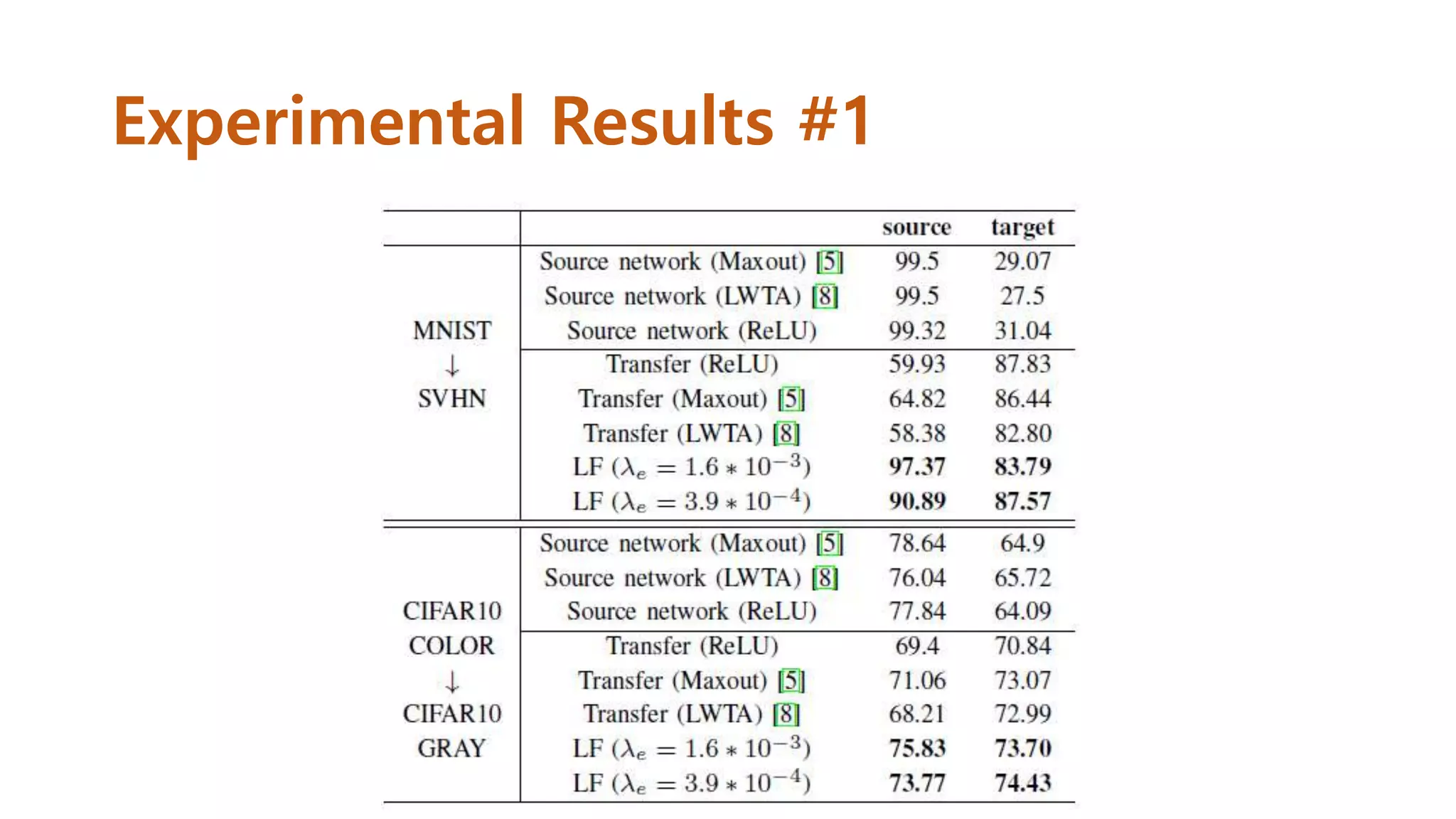
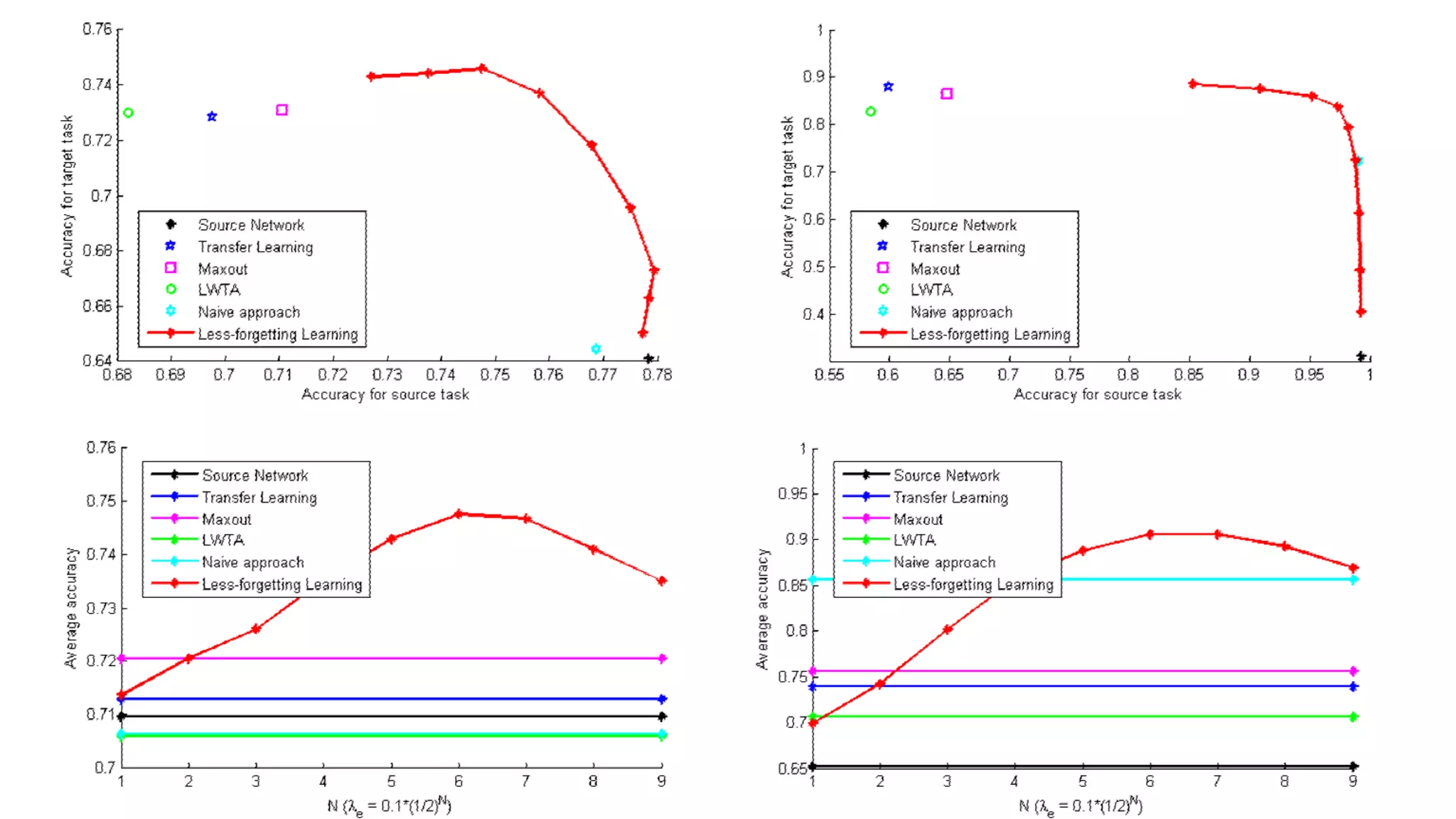
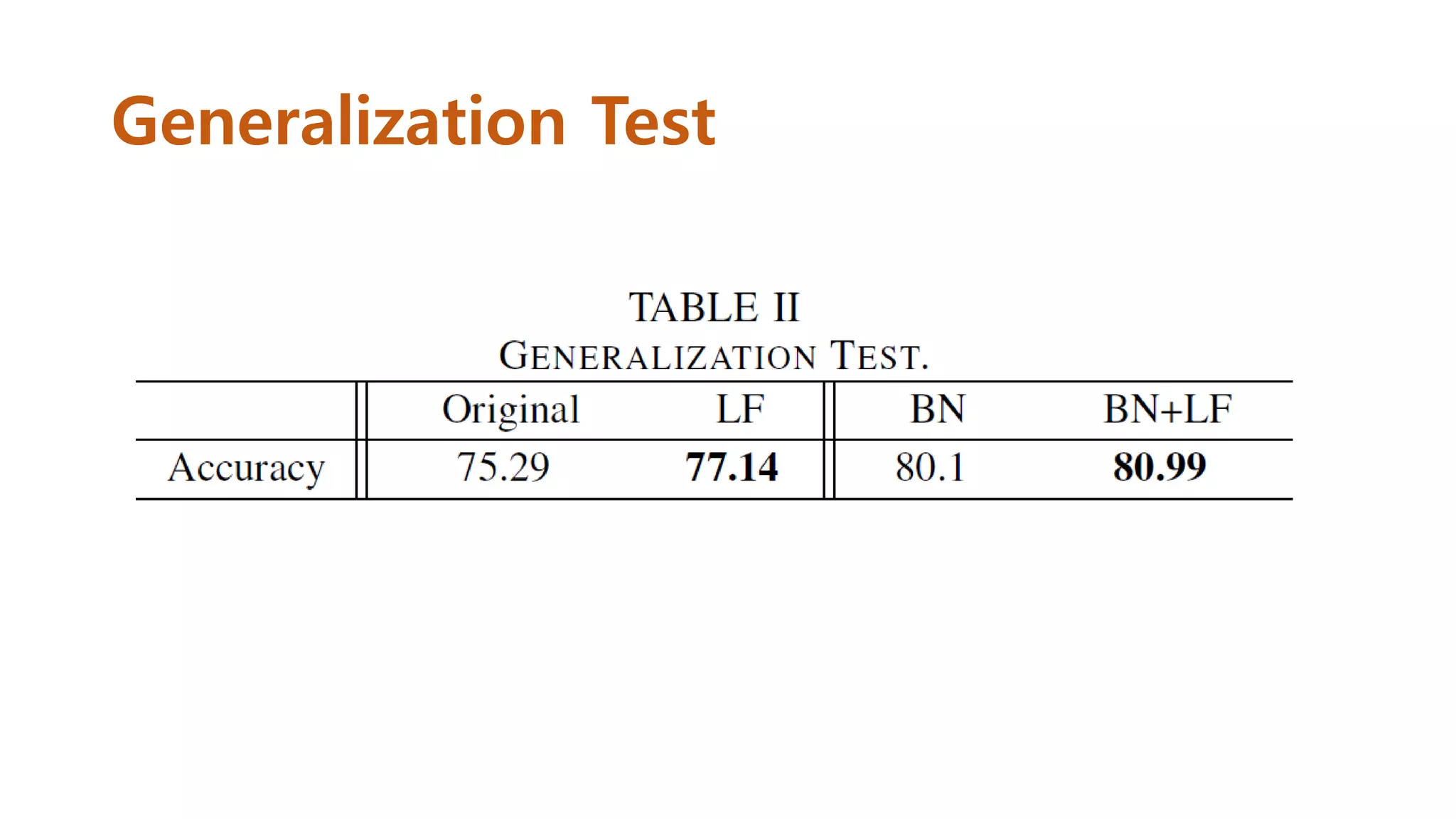
Experimental Results #1
•총 60,000장의 영상 중 50,000장은 training, 10,000장은 test
• Training data는 다시 40,000장과 10,000장으로 나눈 후 10,000
장에 대해서는 grayscale 영상으로 변환
• Test set 10,000장을 gray scale로 변환하여 두 종류의 test set을
제작
• Channel이 다른 data를 같은 network에서 test하기 위해 gray
scale의 channel을 임의로 3으로 늘려서 실험
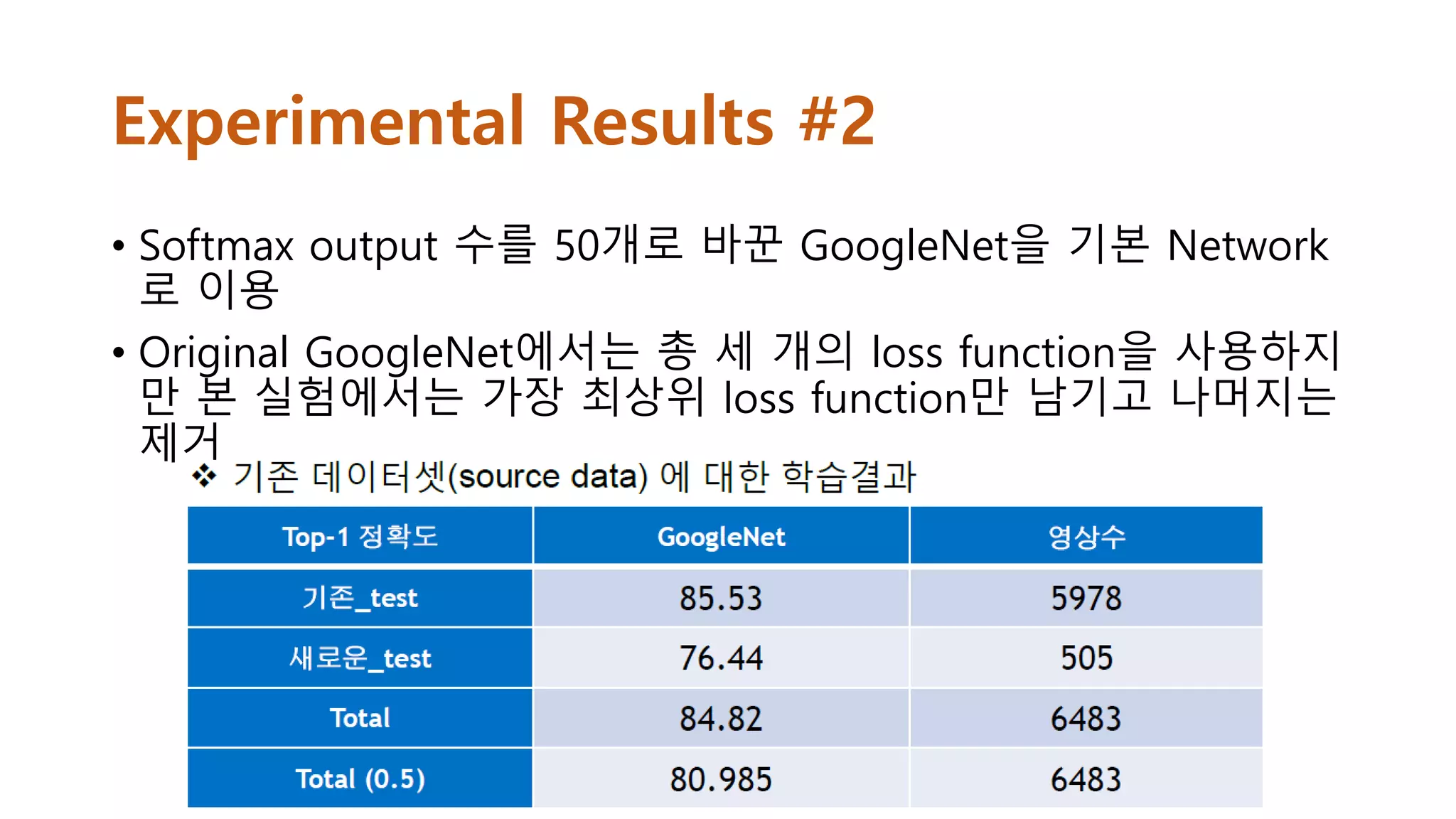
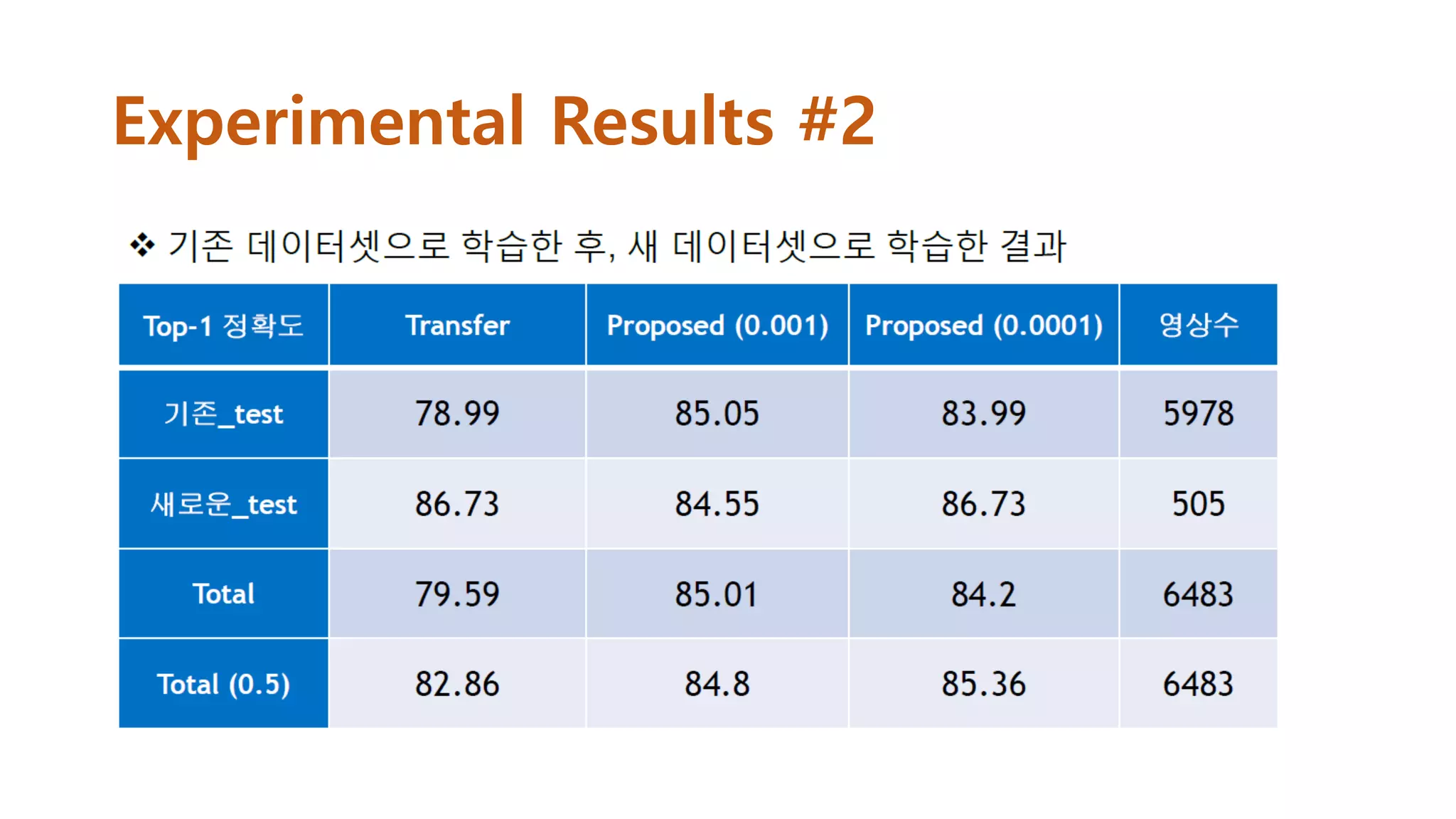
Experimental Results #2
•Softmax output 수를 50개로 바꾼 GoogleNet을 기본 Network
로 이용
• Original GoogleNet에서는 총 세 개의 loss function을 사용하지
만 본 실험에서는 가장 최상위 loss function만 남기고 나머지는
제거
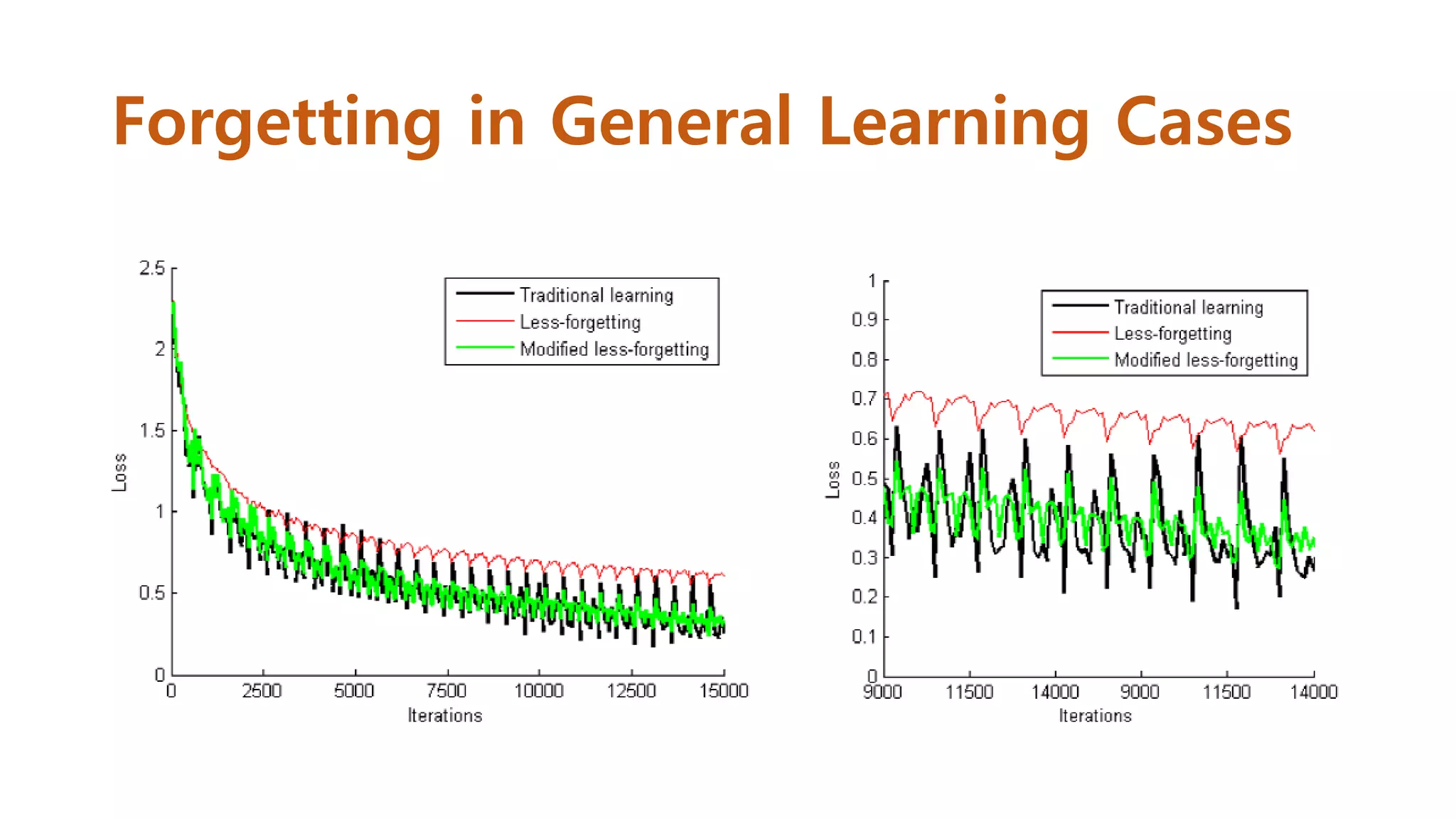
Less-forgetting for GeneralLearning
Cases(Algorithm)
• If the value of Ns is large,
the network does not
adapt a new data well.
Further, the parameter of
Nf plays a role similar to
Ns. As a result, our
algorithm has an ability to
forget less the
information learned
previously. We set the
value of Ns is smaller than
Nf , and we set Ns = 100
and Nf = 1000 for all the
experiments.




































![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)






























