Motivation
NeuralNetwork의 Architecture Design은 결과 향상에 매우 중요
Vanilla CNN: [[Conv + ReLU] x N + MaxPool] x M + [FC + ReLU] x K
Properties of Architecture Design
Hard to Understand
How (O), Why (X)
No Math
But Important
2/15
3.
Introduction
ArchitectureDesign Strategies
Hand-Designed Architectures
Neural Architecture Search
Architecture Authors Publication Cite
ResNet He et al. CVPR 2016 46987
Wide Residual Networks Zagoruyko et al. BMVC 2016 2020
ResNeXt Xie et al. CVPR 2017 2192
SENet Hu et al. TPAMI 2019 2998
DenseNet Huang et al. CVPR 2017 8973
NAS Zoph et al. ICLR 2016 1508
ENAS Pham et al. ICML 2018 584
RandWire Xie et al. ICCV 2019 74
3/15
4.
ResNet (Heet al., CVPR 2016)
Vanilla CNN에서 일정 수준 이상 Deep할 때 성능 저하 확인
Deeper Network는 [Identity Layers + Shallow Network]로 구성 가능
Shallow Network는 Deeper Network의 Subspace
20 Conv Layers
𝑓20(𝑥)
36 Identity Layers
𝐼(𝑥)
[56 Conv Layers could be]
4/15
5.
ResNet (Heet al., CVPR 2016)
일부 Layer에서 Identity Layer가 Optimal할 가능성 고려
Identity Mapping이 나오기 쉬운 Operation을 Design
이때 Conv를 Identity Mapping으로 만드는 것보다, Residual을 Zero로 만드는 것이 유리
Skip Connection을 갖는 Residual Block을 제안
5/15
6.
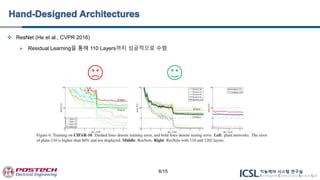
ResNet (Heet al., CVPR 2016)
Residual Learning을 통해 110 Layers까지 성공적으로 수렴
6/15
7.
Wide ResidualNetworks (Zagoruyko et al., BMVC 2016)
Wide Residual Networks: ResNet을 𝑘배 Wide한 구조로 변형한 모델
(Deeper Architecture) ≈ (Wider Architecture)
GPU 병렬처리 특성상 같은 조건(Accuracy)에서 Deep보다 Wide에서 연산이 빠름이 보고됨
7/15
8.
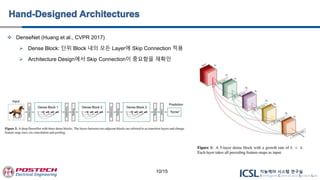
ResNeXt (Xieet al., CVPR 2017)
Branch 구조 제안
Depth나 Width를 높이는 것보다 Branch 수(Cardinality)를 높이는 Architecture가 효율적임을 보고
8/15
9.
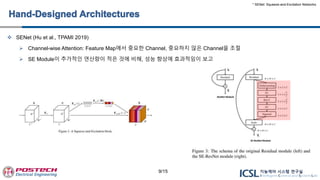
SENet (Huet al., TPAMI 2019)
Channel-wise Attention: Feature Map에서 중요한 Channel, 중요하지 않은 Channel을 조절
SE Module이 추가적인 연산량이 적은 것에 비해, 성능 향상에 효과적임이 보고
* SENet: Squeeze-and-Excitation Networks
9/15
10.
DenseNet (Huanget al., CVPR 2017)
Dense Block: 단위 Block 내의 모든 Layer에 Skip Connection 적용
Architecture Design에서 Skip Connection이 중요함을 재확인
10/15
11.
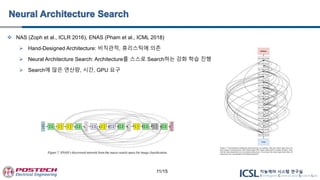
NAS (Zophet al., ICLR 2016), ENAS (Pham et al., ICML 2018)
Hand-Designed Architecture: 비직관적, 휴리스틱에 의존
Neural Architecture Search: Architecture를 스스로 Search하는 강화 학습 진행
Search에 많은 연산량, 시간, GPU 요구
11/15
12.
RandWire (Xieet al., ICCV 2019)
다양한 Wiring이 성능 향상에 중요
보다 자유도가 높은 Wiring을 Random Graph를 통해 구성하여 Architecture 설정
유사한 조건(FLOPs, # Param)에서 ResNet/ResNeXt보다 높은 성능 보고
* FLOPs: FLoating point Operations Per Second, 초당 부동소수점 연산
12/15
13.
Architecture DesignStrategies
Various Skip Connections
Large Neural Network: Depth, Width, and Cardinality
Complex Architecture
Neural Architecture Search
Performance Comparison
13/15
14.
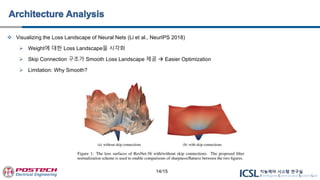
Visualizing theLoss Landscape of Neural Nets (Li et al., NeurIPS 2018)
Weight에 대한 Loss Landscape을 시각화
Skip Connection 구조가 Smooth Loss Landscape 제공 Easier Optimization
Limitation: Why Smooth?
14/15
15.
Deep DoubleDescent (Nakkiran et al., ICLR 2020)
Neural Network가 Large할 수록 성능이 좋아질 수도, 아닐 수도 있다.
Training Time, Dataset Size 등의 조건에 따라 다른 성질 확인
CNN, ResNet 등 다양한 실험에서 해당 현상 확인
15/15


![ Motivation
Neural Network의 Architecture Design은 결과 향상에 매우 중요
Vanilla CNN: [[Conv + ReLU] x N + MaxPool] x M + [FC + ReLU] x K
Properties of Architecture Design
Hard to Understand
How (O), Why (X)
No Math
But Important
2/15](https://image.slidesharecdn.com/bjarchitectureslideshare-200605122134/85/Architecture-Design-Strategies-2-320.jpg)
![ ResNet (He et al., CVPR 2016)
Vanilla CNN에서 일정 수준 이상 Deep할 때 성능 저하 확인
Deeper Network는 [Identity Layers + Shallow Network]로 구성 가능
Shallow Network는 Deeper Network의 Subspace
20 Conv Layers
𝑓20(𝑥)
36 Identity Layers
𝐼(𝑥)
[56 Conv Layers could be]
4/15](https://image.slidesharecdn.com/bjarchitectureslideshare-200605122134/85/Architecture-Design-Strategies-4-320.jpg)










![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 5 - Others](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture5others-210215060452-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=640&height=640&fit=bounds)
![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)


![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 4 - ResNet](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture4resnet-210214112234-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] PR-026: Notes for CVPR Machine Learning Sessions](https://cdn.slidesharecdn.com/ss_thumbnails/pr-026notesforcvprmachinelearningsessions-170731034245-thumbnail.jpg?width=640&height=640&fit=bounds)









