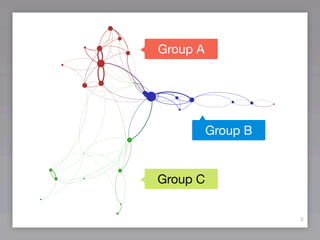
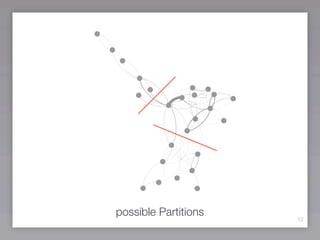
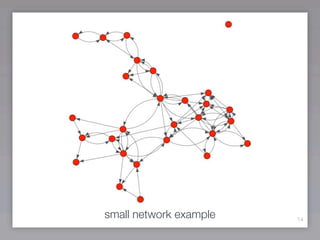
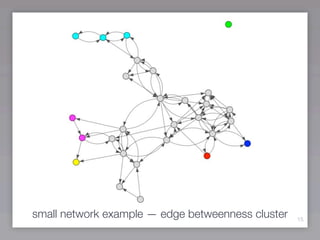
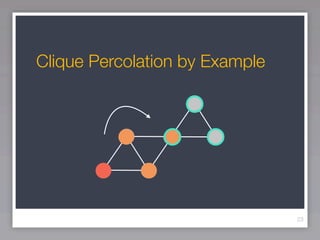
This document discusses community detection methods for identifying groups within networks. It begins with an overview of community detection and its relevance. It then discusses the basic idea behind community detection algorithms, which aim to identify communities as groups of nodes that are more densely connected internally than externally. The document outlines some notable algorithms like edge betweenness and clique percolation. It also covers limitations regarding technical aspects like runtime and memory needs, and methodological issues around evaluation and comparison of algorithm results.