Download as PDF, PPTX



![$ aws ec2 authorize-security-group-ingress --group-id sg-7f3dd918 --protocol tcp --
port 22 --cidr 0.0.0.0/0
$ aws ec2 run-instances --image-id ami-5c2beb3d --count 1 --instance-type
t2.medium --key-name ilho_tokyo --security-group-ids sg-7f3dd918 --subnet-id
subnet-1a7bad43 --associate-public-ip-address
{
"OwnerId": "806506827877",
"ReservationId": "r-a58c5e2a",
"Groups": [],
"Instances": [
{
"Monitoring": {
…..................](https://image.slidesharecdn.com/dataanalyticsandykim-160929020217/85/Gaming-on-AWS-2016-5-320.jpg)



![$ aws redshift create-cluster --cluster-identifier andy-game-dw --db-name mydb --node-type
dc1.large --cluster-type single-node --publicly-accessible --master-username admin --master-
user-password GamingonAWS2016
{
"Cluster": {
"IamRoles": [],
"ClusterVersion": "1.0",
"NodeType": "dc1.large",
"PubliclyAccessible": true,
"Tags": [],
"MasterUsername": "admin",
"ClusterParameterGroups": [
{
"ParameterGroupName": "default.redshift-1.0",
"ParameterApplyStatus": "in-sync"
}
],
"Encrypted": false,
…....................](https://image.slidesharecdn.com/dataanalyticsandykim-160929020217/85/Gaming-on-AWS-2016-11-320.jpg)
![Let’s connect to EC2 instances
$ ssh -i [$mykey].pem ec2-user@xx.xx.xx.xx](https://image.slidesharecdn.com/dataanalyticsandykim-160929020217/85/Gaming-on-AWS-2016-12-320.jpg)
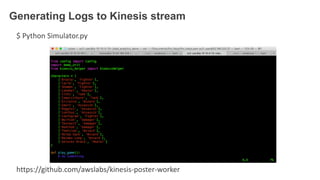
![Prepared python demo scripts
[ec2-user@ip-10-10-0-13 data_analytics_demo]$ ls -1
amazon_kclpy
amazon_kclpy_helper.py
config.json
config.py
config.pyc
consumer.properties
consumer.py
demo_util.py
demo_util.pyc
inserter.py
kcl
kinesis_helper.py
kinesis_helper.pyc
LICENSE
logs
reader.py
run_consumer.sh
simulator.py
summarizer.py](https://image.slidesharecdn.com/dataanalyticsandykim-160929020217/85/Gaming-on-AWS-2016-13-320.jpg)
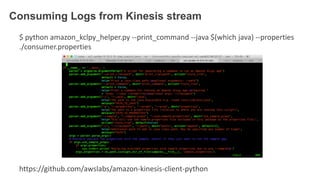

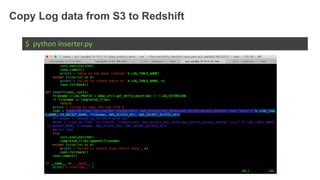
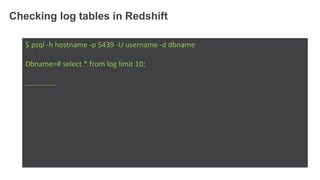
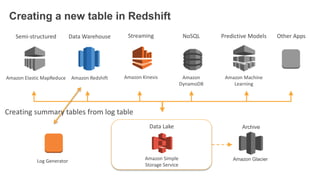
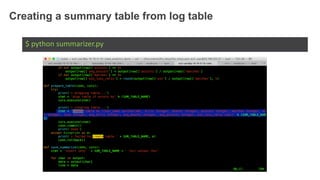
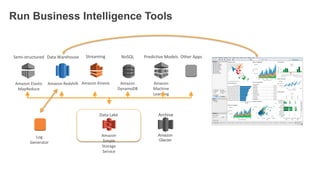

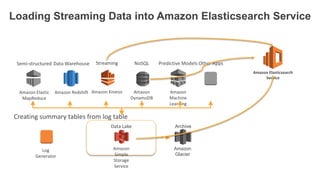

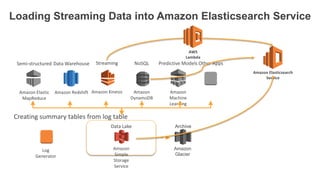

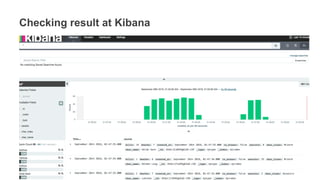

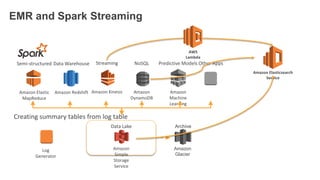
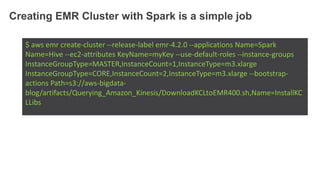

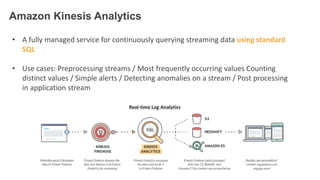
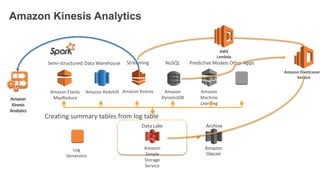



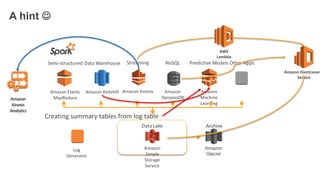


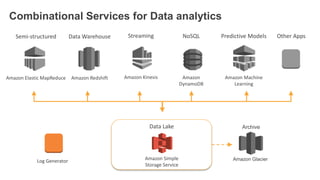
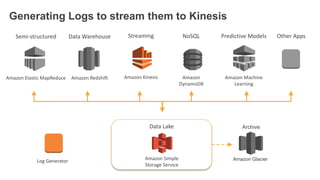
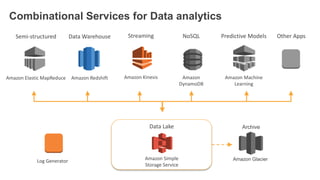
1. The document demonstrates how to use various AWS services like Kinesis, Redshift, Elasticsearch to analyze streaming game log data. 2. It shows setting up an EC2 instance to generate logs, creating a Kinesis stream to ingest the logs, and building Redshift tables to run queries on the logs. 3. The document also explores loading the logs from Kinesis into Elasticsearch for search and linking Kinesis and Redshift with Kinesis Analytics for real-time SQL queries on streams.






































![[よくわかるAmazon Redshift in 大阪]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140221redshiftupdatesv2osaka-140224010309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)























