Download as PDF, PPTX


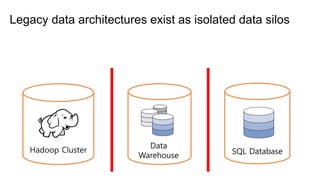

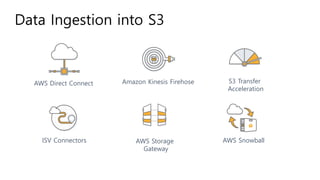
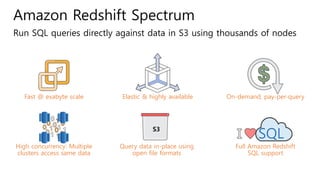












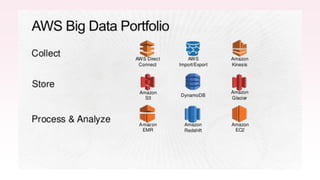
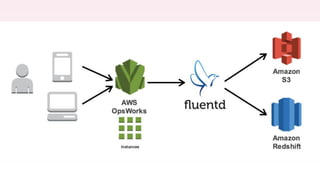
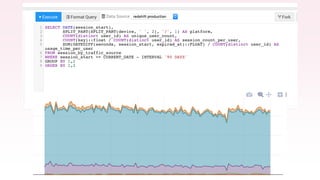


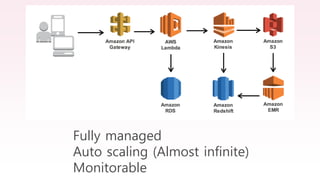
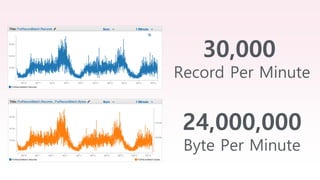
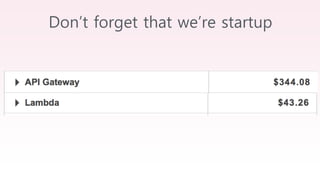

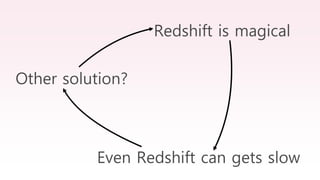

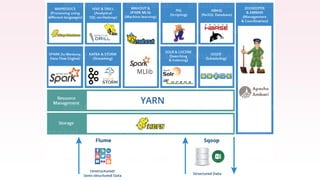
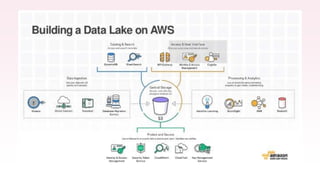
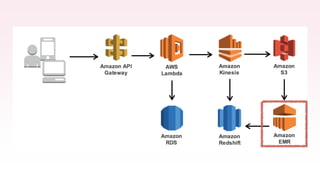
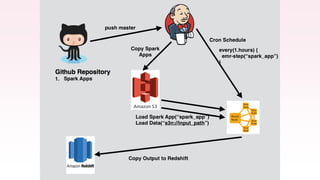


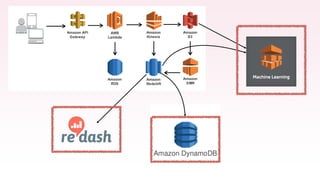








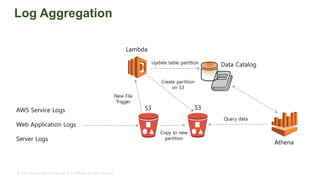
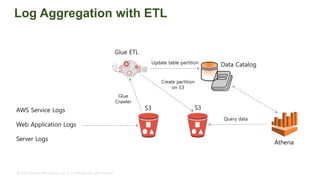
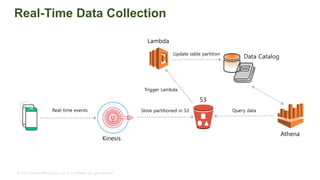
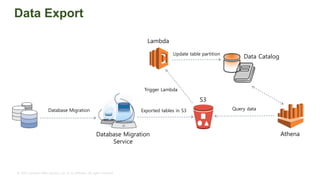
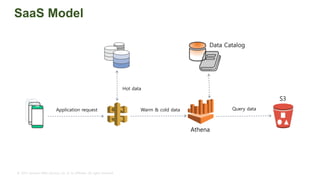
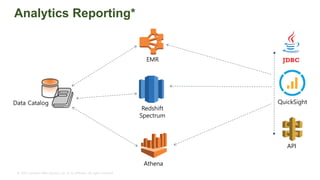



The document provides an overview of AWS big data and analytics services, focusing on tools like Amazon Athena, Amazon EMR, and Amazon Redshift, which can facilitate data ingestion, storage, querying, and analysis. It discusses features such as serverless architecture, scalability, cost management, and supports for different data formats and structures. The document emphasizes the importance of managing big data efficiently while ensuring security and compliance.



































![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)























