Download to read offline








![00Copyright 2018 © Qubole
Stateless Streaming - Ingest in S3
Batch 1
Batch 2
Batch 3
[1-4]
[5-8]
[9-10]
File 1
File 2
File 3
Micro batch consist of new records in each batch](https://image.slidesharecdn.com/structured-streaming-quboleprateekvikram-191110134305/75/Key-considerations-in-productionizing-streaming-applications-12-2048.jpg)
![00Copyright 2018 © Qubole
Micro batch consists of New Input Records & Previous micro-batches’ sum saved in
a state store
Stateful Streaming - Running Sum
Batch 1
Batch 2
Batch 3
State
= 10
[1-4]
[5-8]
[9-10]
State
= 36
State
= 55](https://image.slidesharecdn.com/structured-streaming-quboleprateekvikram-191110134305/75/Key-considerations-in-productionizing-streaming-applications-13-2048.jpg)

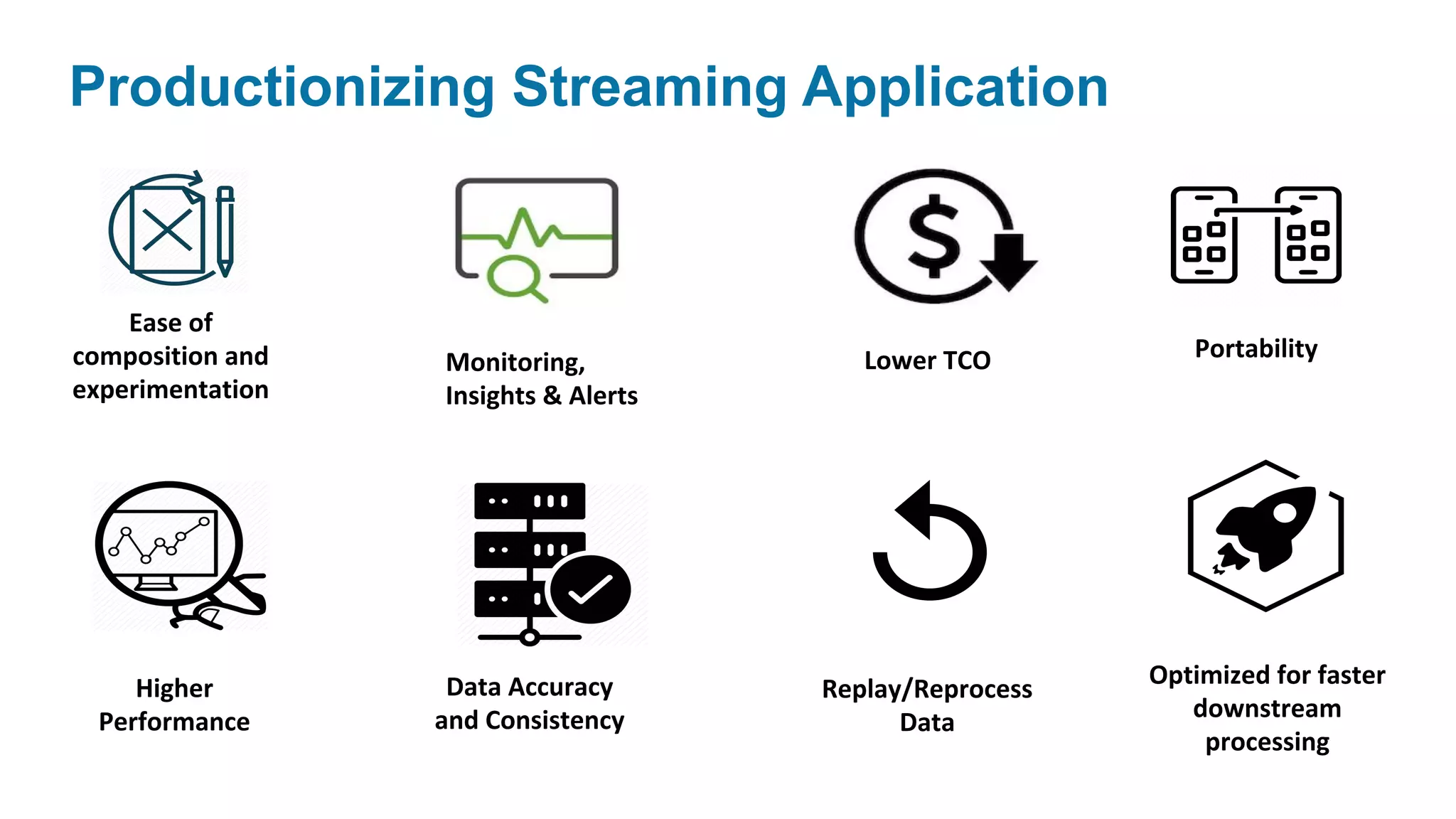


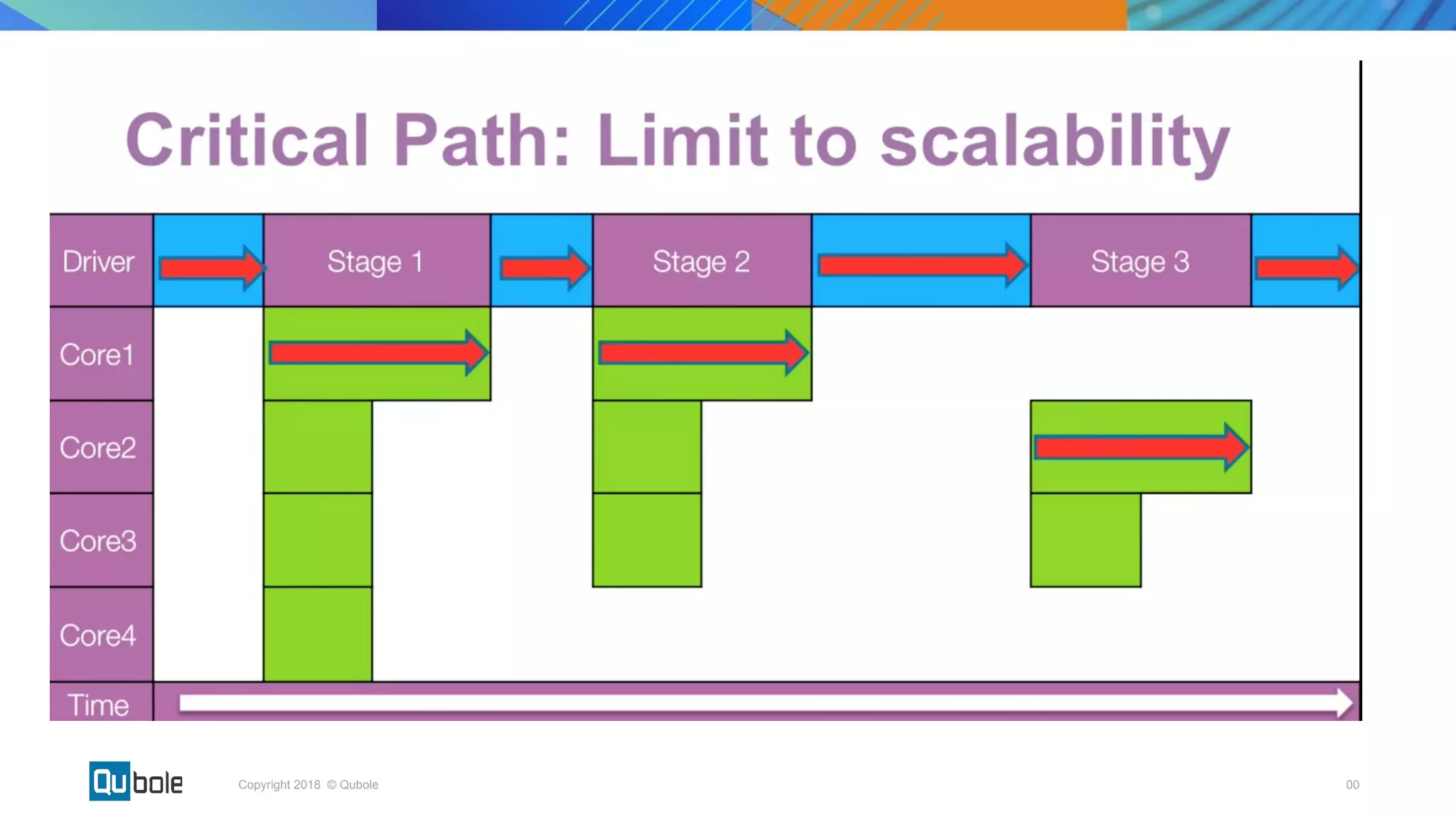


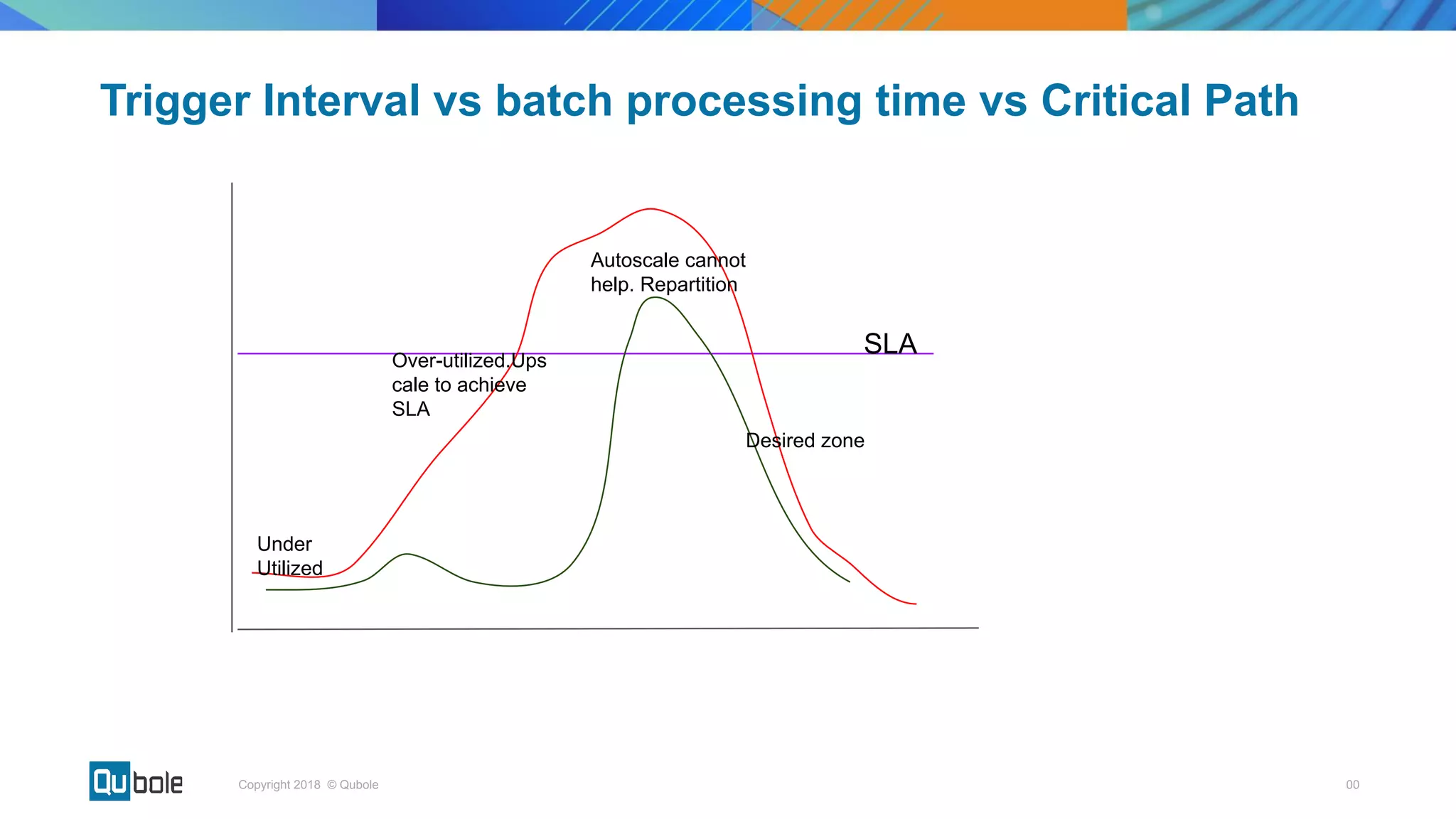

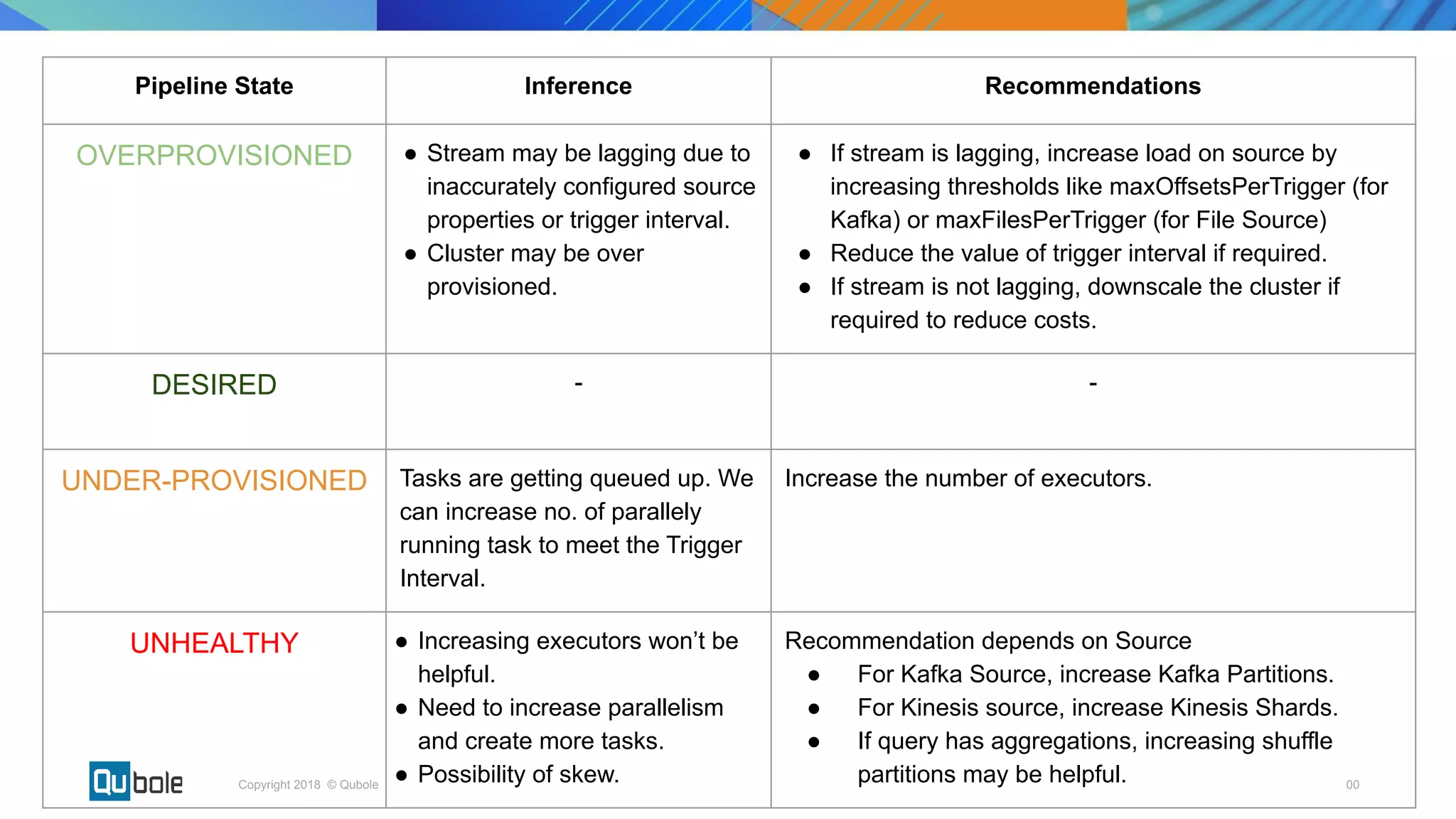


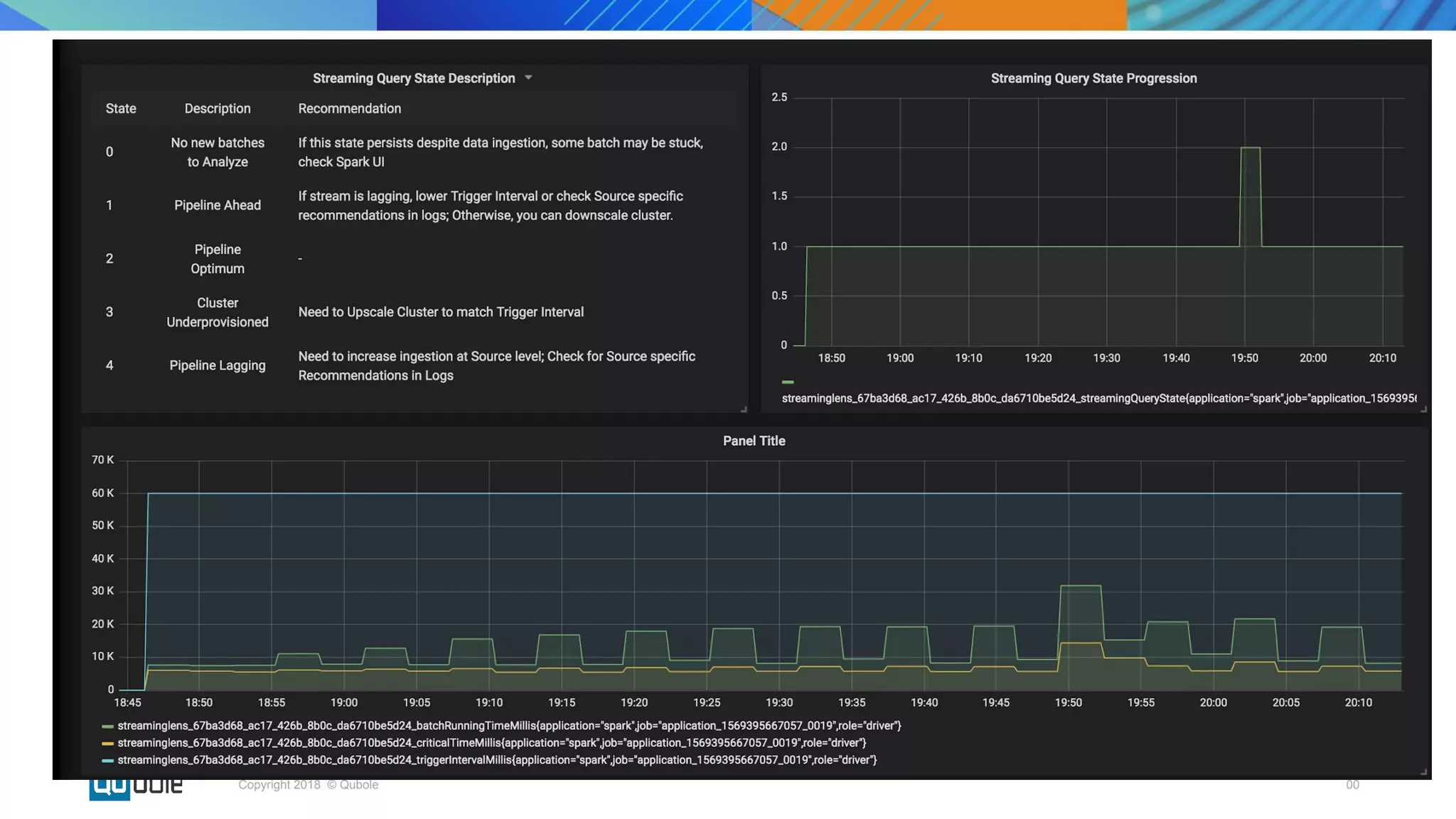


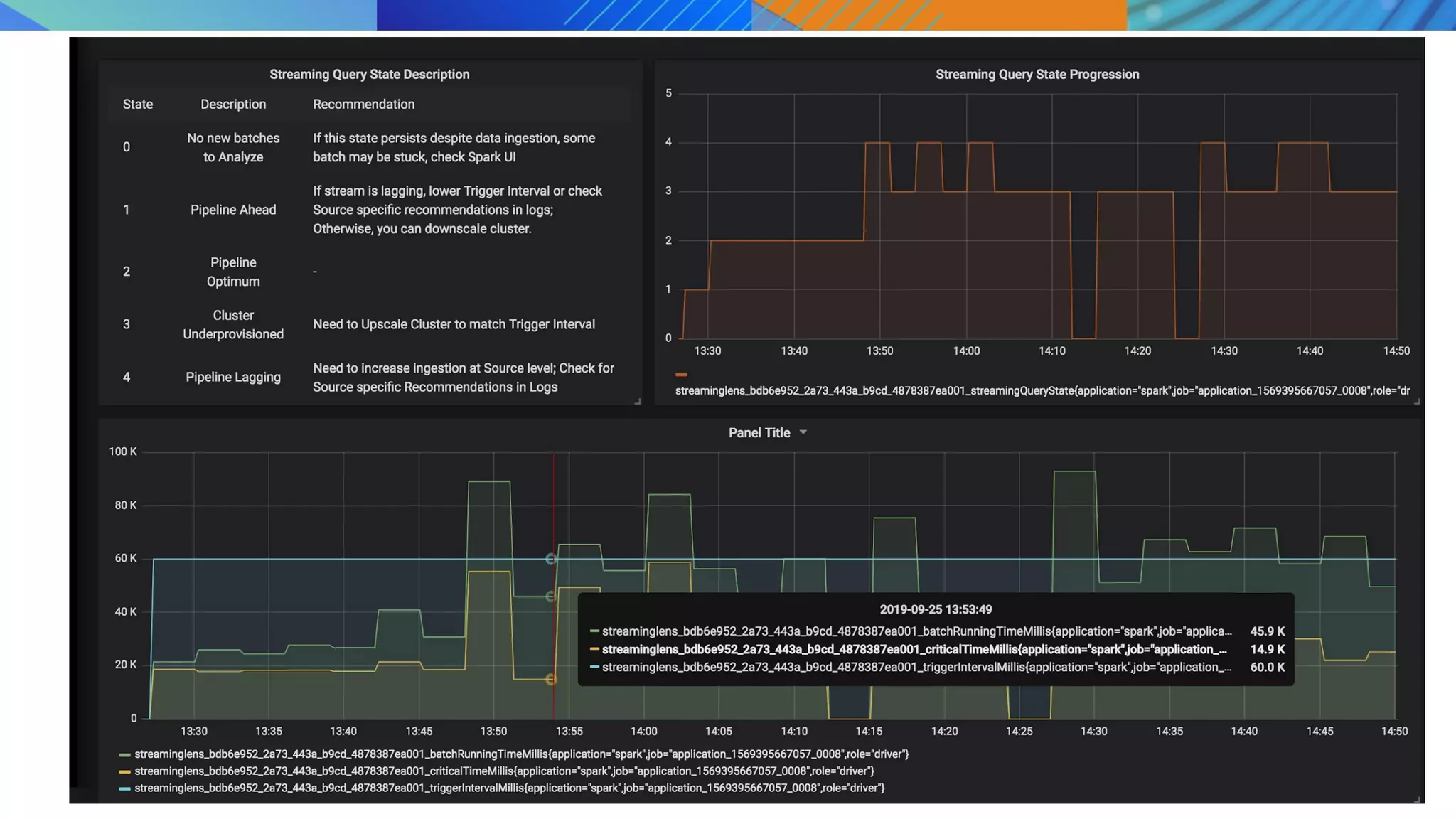


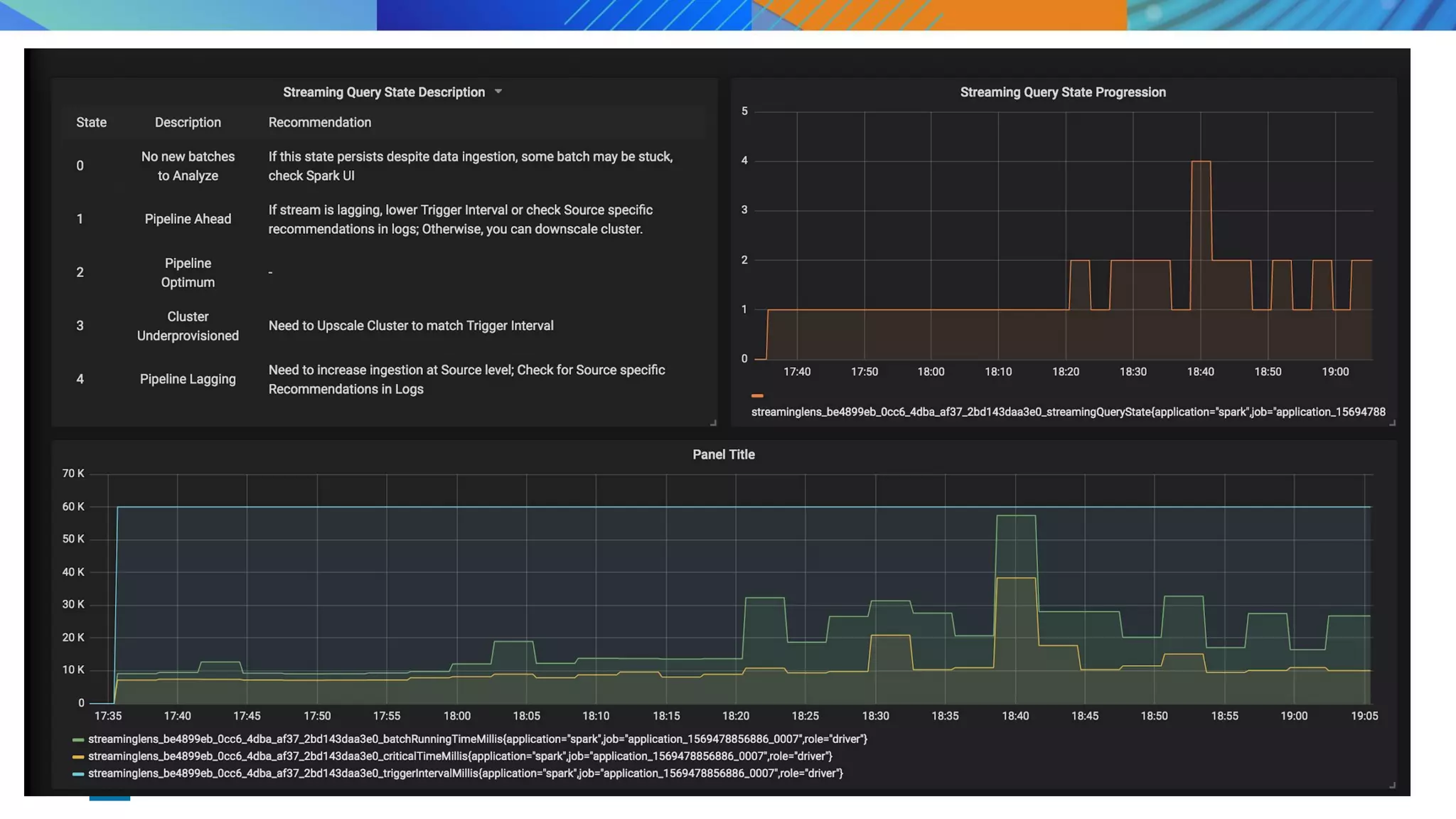




This document discusses key considerations for productionizing streaming applications. It provides an overview of streaming concepts and Spark structured streaming. It discusses how to choose a streaming engine based on factors like latency, throughput, and functionality requirements. Spark structured streaming is recommended due to its low latency, high throughput, and developer-friendly APIs. The document also discusses using Spark Lens to monitor streaming jobs and make recommendations to meet performance goals like trigger intervals. It provides examples of experimenting with different cluster configurations and analyzing the results with Spark Lens.









































































