This document discusses debugging data pipelines at Ola and summarizes:
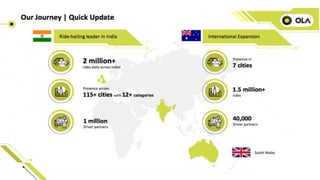
1) Ola runs 25k queries daily across 2.5TB of data ingested daily and maintained in 3k tables using Presto across MySQL, PostgreSQL, Kafka, MongoDB, HBase and other data sources.
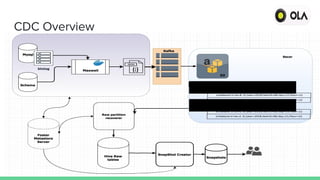
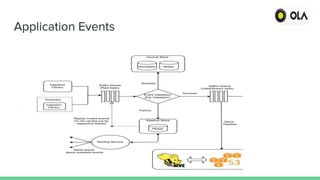
2) Presto provides a single unified view of data sources and reduces turnaround times for business analysts, but initially had issues querying Kafka topics.
3) The solution was to have Presto hit the Kafka broker for the topic list each time and leverage message timestamps, reducing query times significantly.