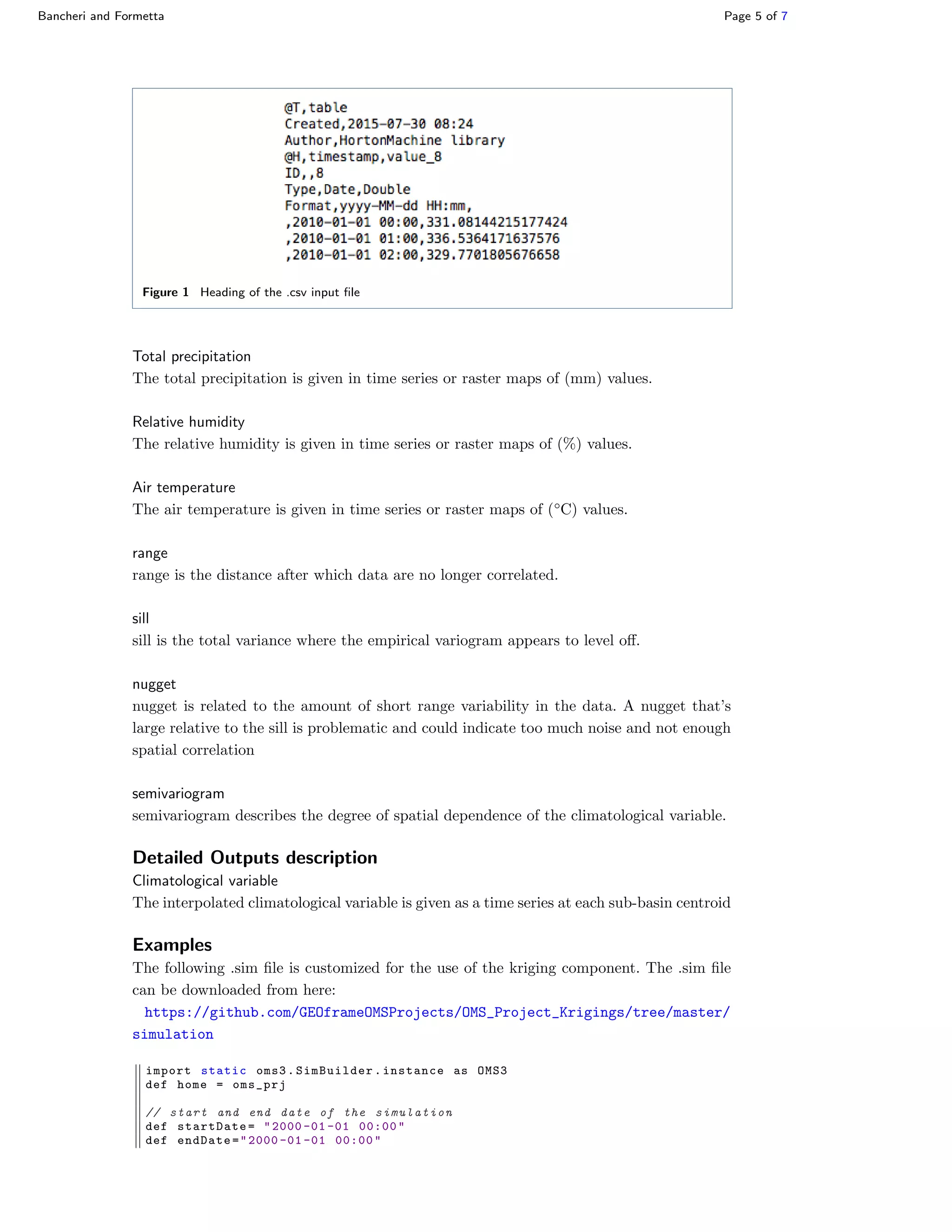
This document describes a Kriging component for spatial interpolation of climatological variables in the OMS modeling framework. Kriging is a geostatistical technique that interpolates values based on measured data and the spatial autocorrelation between data points. The component implements ordinary and detrended Kriging algorithms using 10 semivariogram models. It can interpolate both raster and point data and outputs the interpolated climatological variable values. Links are provided for downloading the component code, data, and OMS project files needed to run the interpolation.


![Bancheri and Formetta Page 3 of 7
Component Description
Kriging is a group of geostatistical techniques used to interpolate the value of random
fields based on spatial autocorrelation of measured data (1, Chapter 6.2). The measure-
ments value z(xα) and the unknown value z(x), where x is the location, given according
to a certain cartographic projection, are considered as particular realizations of random
variables Z(xα) and Z(x) (Goovaerts, 1997; Isaaks and Srivastava, 1989). The estimation
of the unknown value zλ
(x), where the true unknown value is Zλ
(x), is obtained as a
linear combination of the N values at surrounding points, Goovaerts (1999):
Zλ
(x) − m(x) =
N
α=1
λ(xα)[Z(uα) − m(xα)] (1)
where m(x) and m(xα) are the expected values of the random variables Z(x) and Z(xα).
λ(xα) is the weight assigned to datum z(xα). Weights are chosen to satisfy the conditions
of minimizing the error of variance of the estimator σ2
λ, that is:
argmin
λ
σ2
λ ≡ argmin
λ
VarZλ
(x) − Z(x) (2)
under the constrain that the estimate is unbiased, i.e.
EZλ
(x) − Z(x) = 0 (3)
The latter condition, implies that:
N
α=1
λα(xα) = 1 (4)
As shown in various textbooks, e.g. Kitanidis (1997), the above conditions bring to a linear
system whose unknown is the tuple of weights, and the system matrix depends on the
semivariograms among the couples of the known sites. When it is made the assumption
of isotropy of the spatial statistics of the quantity analyzed, the semivariogram is given
by Cressie and Cassie (1993):
γ(h) :=
1
2Nh
Nh
i=1
(Z(x) − Z(x)i)2
(5)
where the distance (x, xi) ≡ h, Nh denotes the set of pairs of observations at local x and
at location xi at distance h apart from x. In order to be extended to any distance, ex-
perimental semivariogram need to be fitted to a theoretical semivariogram model. These
theoretical semivariograms contain parameters (called nugget, sill and range) to be fitted
against the existing data, before introducing in the Kriging linear system, whose solu-
tion returns the weights in eq.(1). Three main variants of Kriging can be distinguished,
(Goovaerts, 1997):
• Simple Kriging (SK),which considers the mean, m(x), to be known and constant
throughout the study area;
• Ordinary Kriging (OK) ,which account for local fluctuations of the mean, limiting
the stationarity to the local neighborhood. In this case, the mean in unknown.](https://image.slidesharecdn.com/jgrass-newage-kriging-171115113035/75/Jgrass-NewAge-Kriging-component-3-2048.jpg)