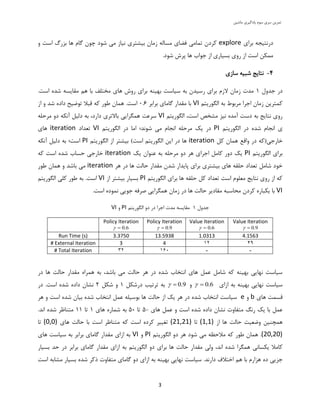
سشی توشیيهاضیي یادگیشیسَم
5
b) Actions selected at each statea) State-value function for final optimal policy
Policy Iteration
e) Actions selected at each stated) State-value function for final optimal policy
Value Iteration
Results of applying Gamma=0.6
شکل2
6.
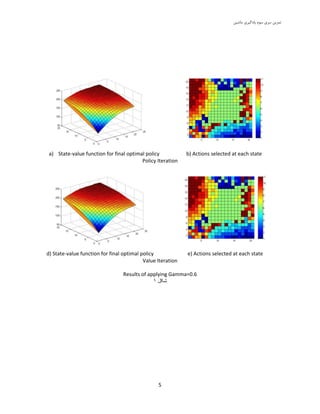
سشی توشیيهاضیي یادگیشیسَم
6
b) Actions selected at each stateb) State-value function for final optimal policy
Policy Iteration
e) Actions selected at each stated) State-value function for final optimal policy
Value Iteration
Results of applying Gamma=0.9
شکل3