







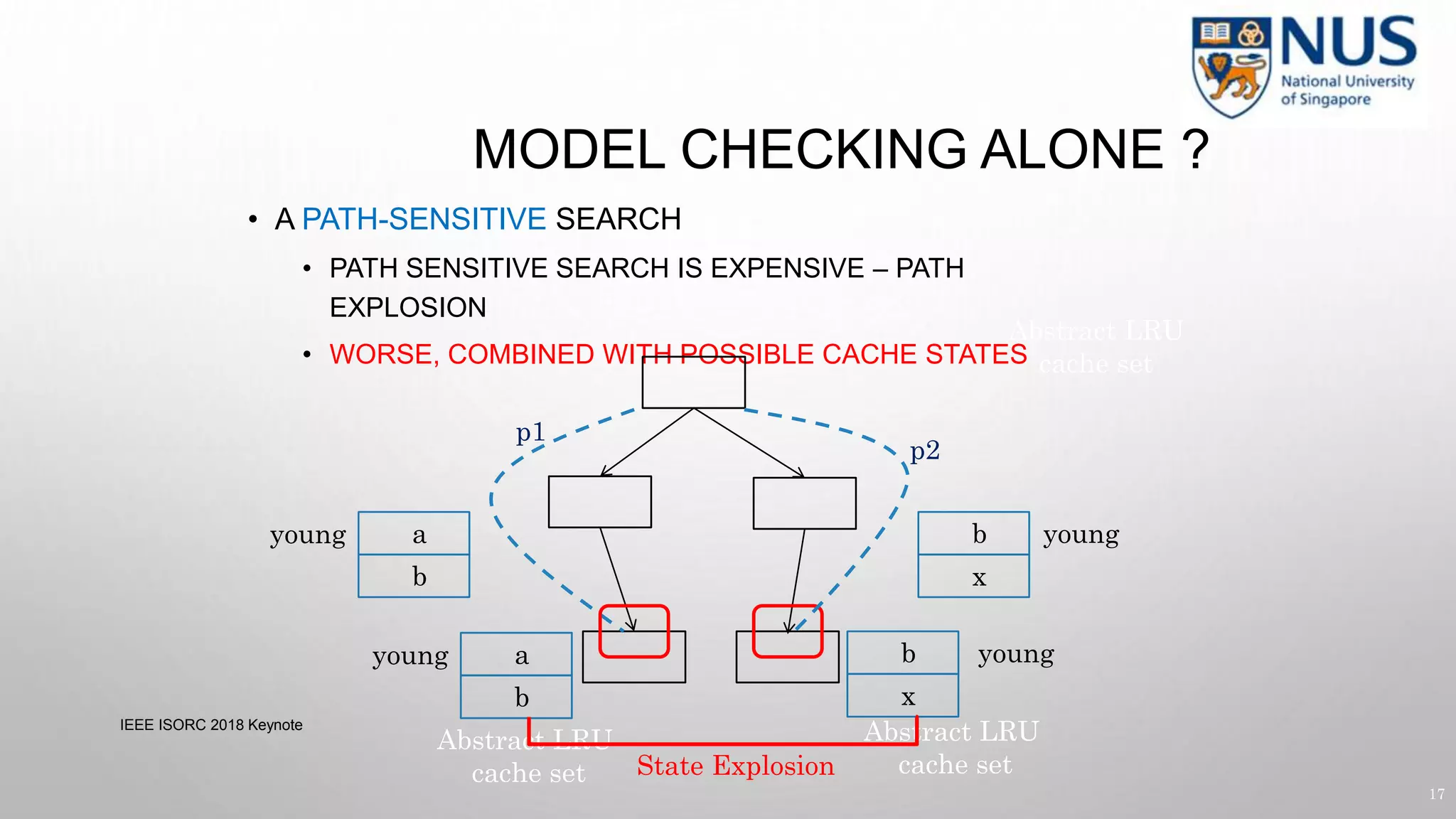




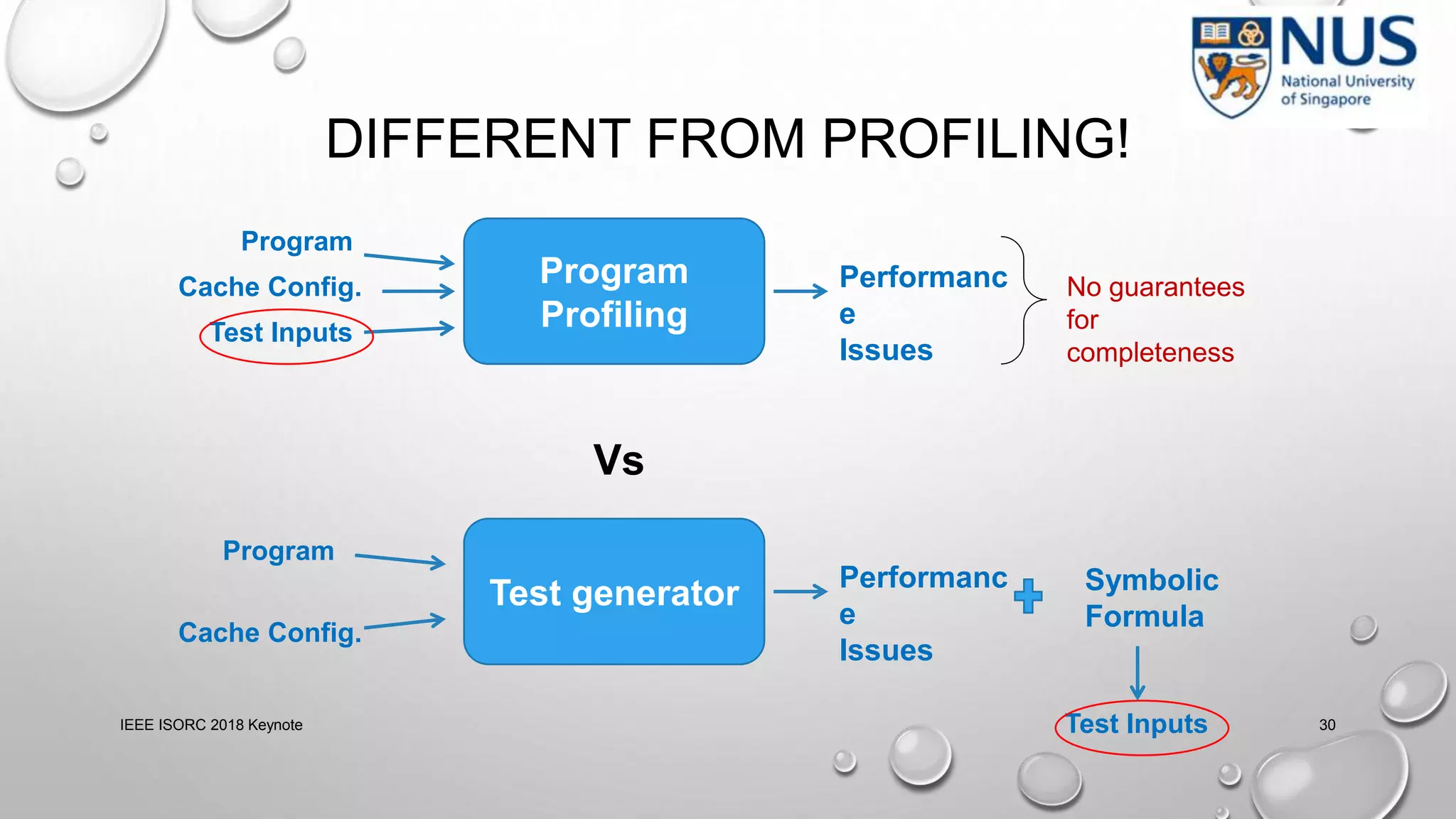
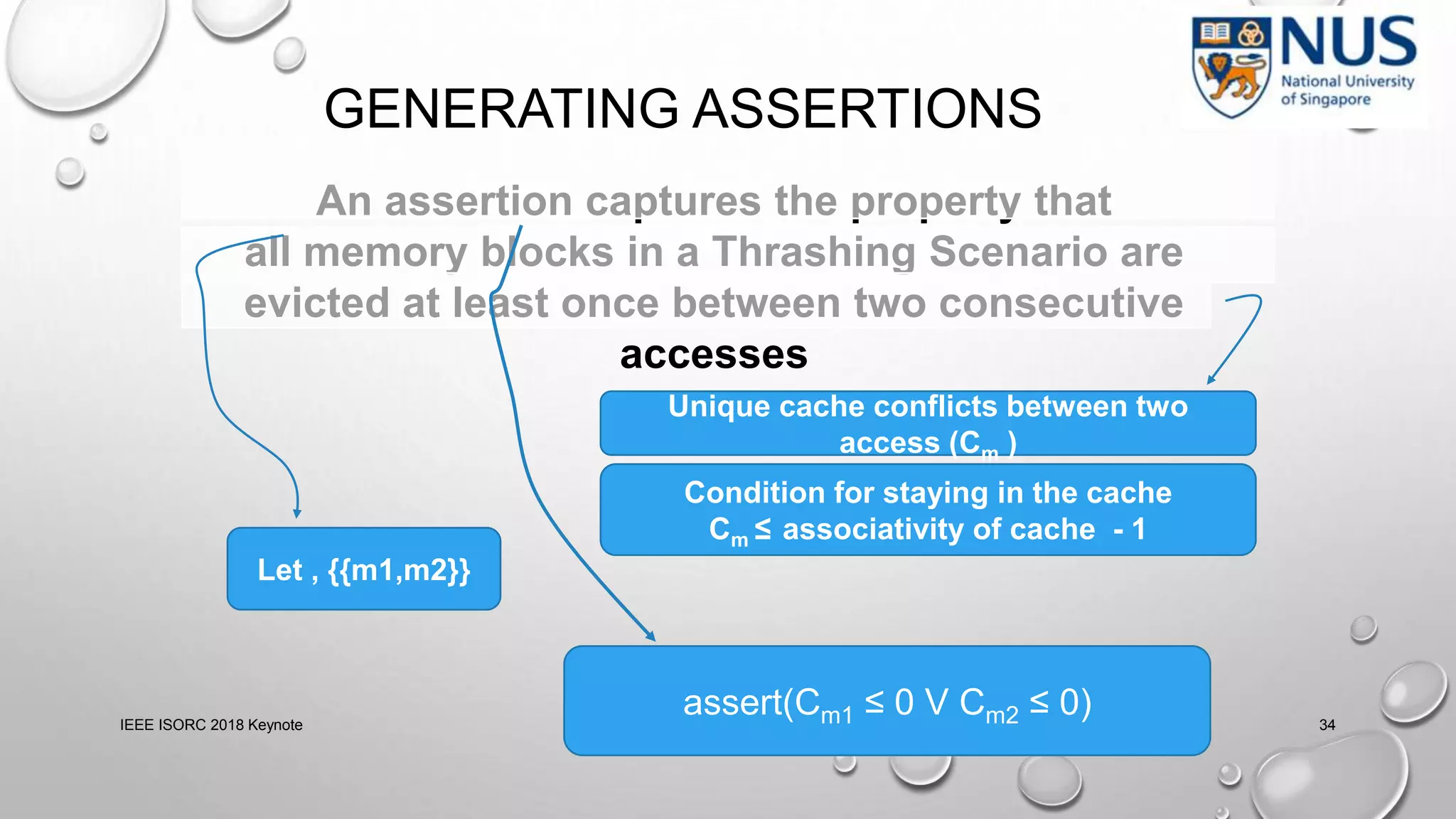






![CACHE SIDE CHANNELS
load a[key]
load a[1]
load a[2]
Cache
Key = 0
load a[2]
a[0]
a[1]
a[2]
classified input (key) — key can be 0 or 1
MISS
Side-channel Leaks
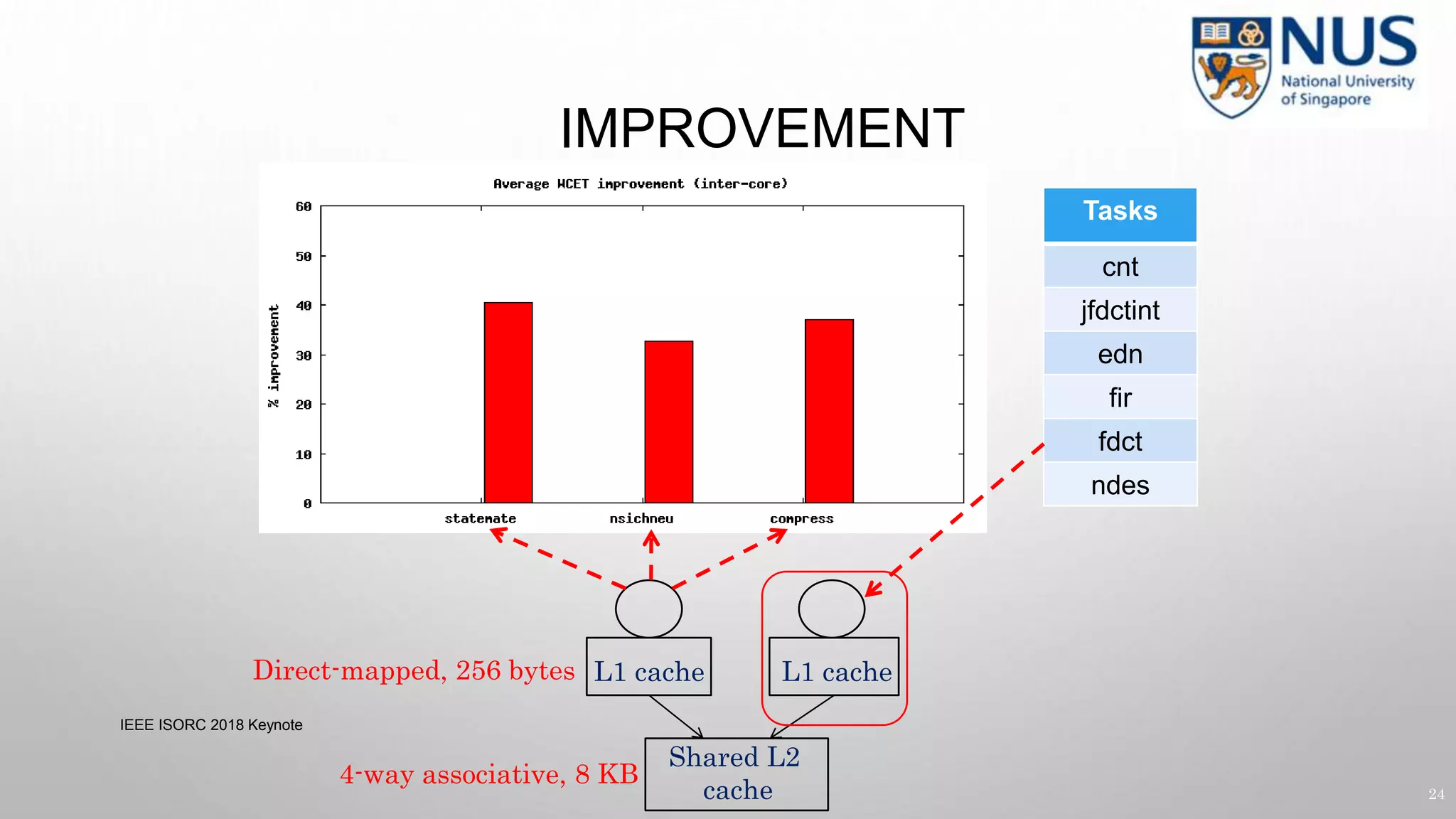
45
IEEE ISORC 2018 Keynote 45](https://image.slidesharecdn.com/isorc18-keynote-181213084004/75/Isorc18-keynote-44-2048.jpg)
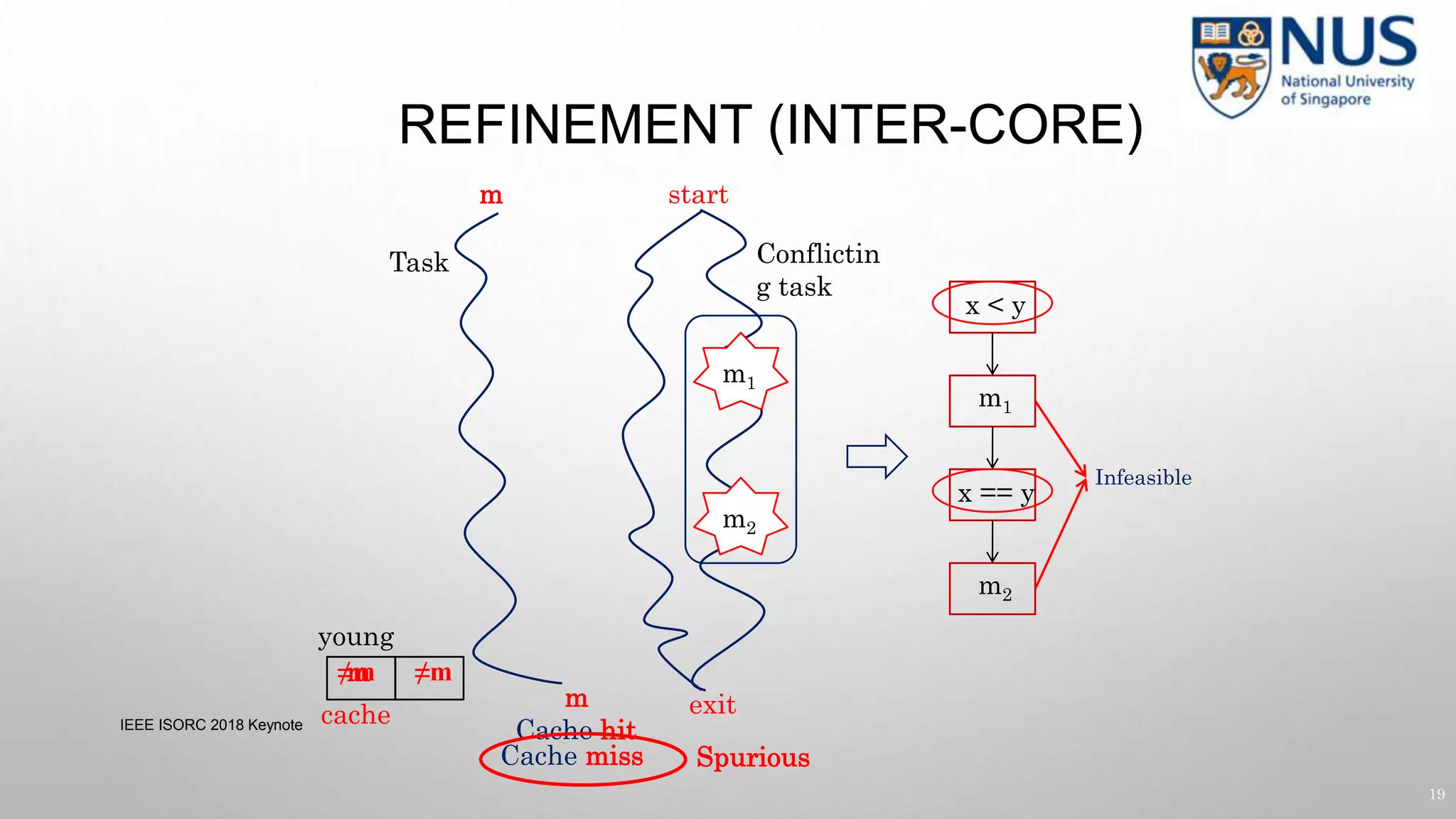
![CACHE SIDE CHANNELS
load a[key]
load a[1]
load a[2]
Cache
Key = 1
load a[2]
a[1]
a[2]
classified input (key) — key can be 0 or 1
HIT
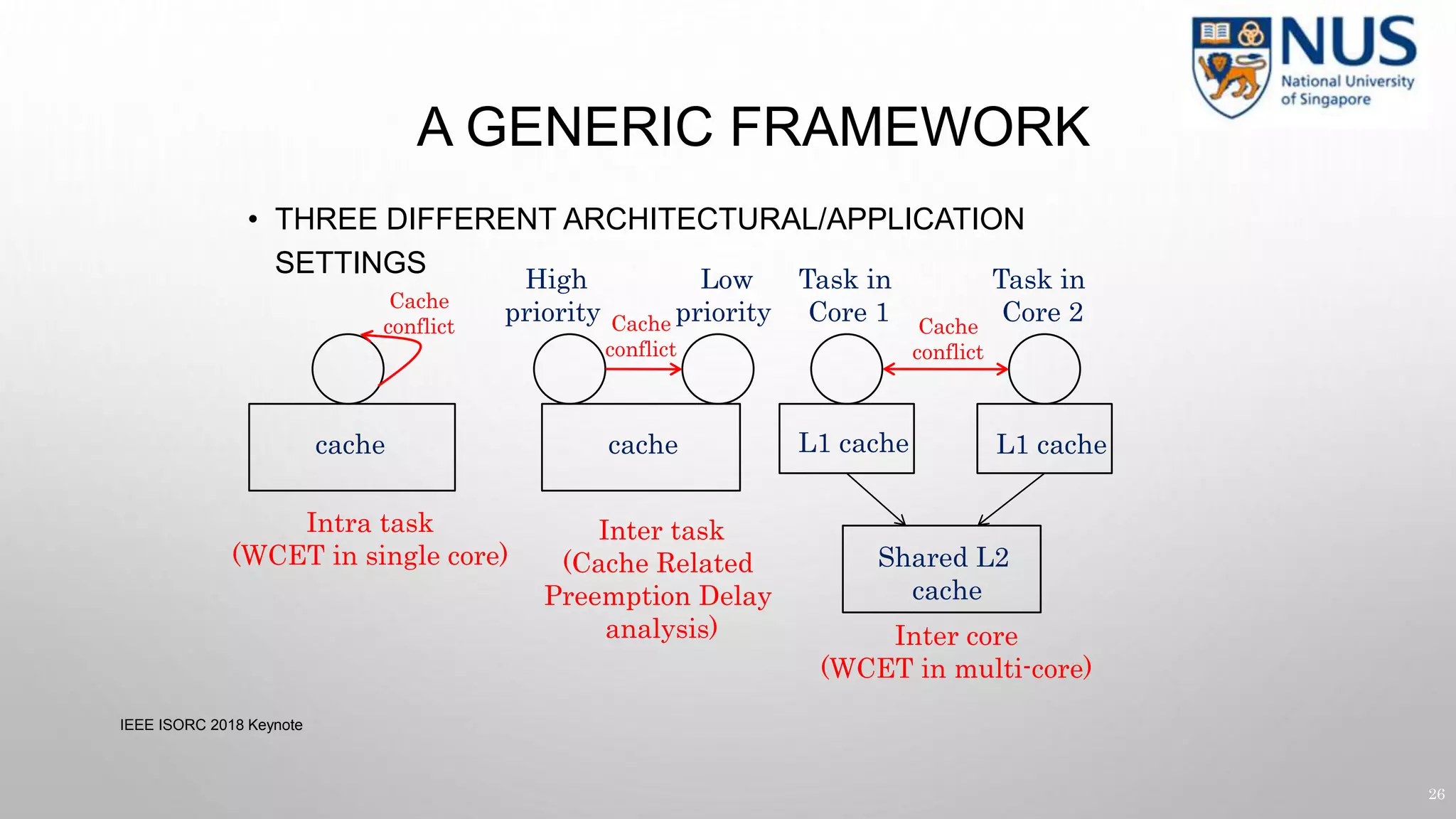
Side-channel Leaks
46
IEEE ISORC 2018 Keynote 46](https://image.slidesharecdn.com/isorc18-keynote-181213084004/75/Isorc18-keynote-45-2048.jpg)
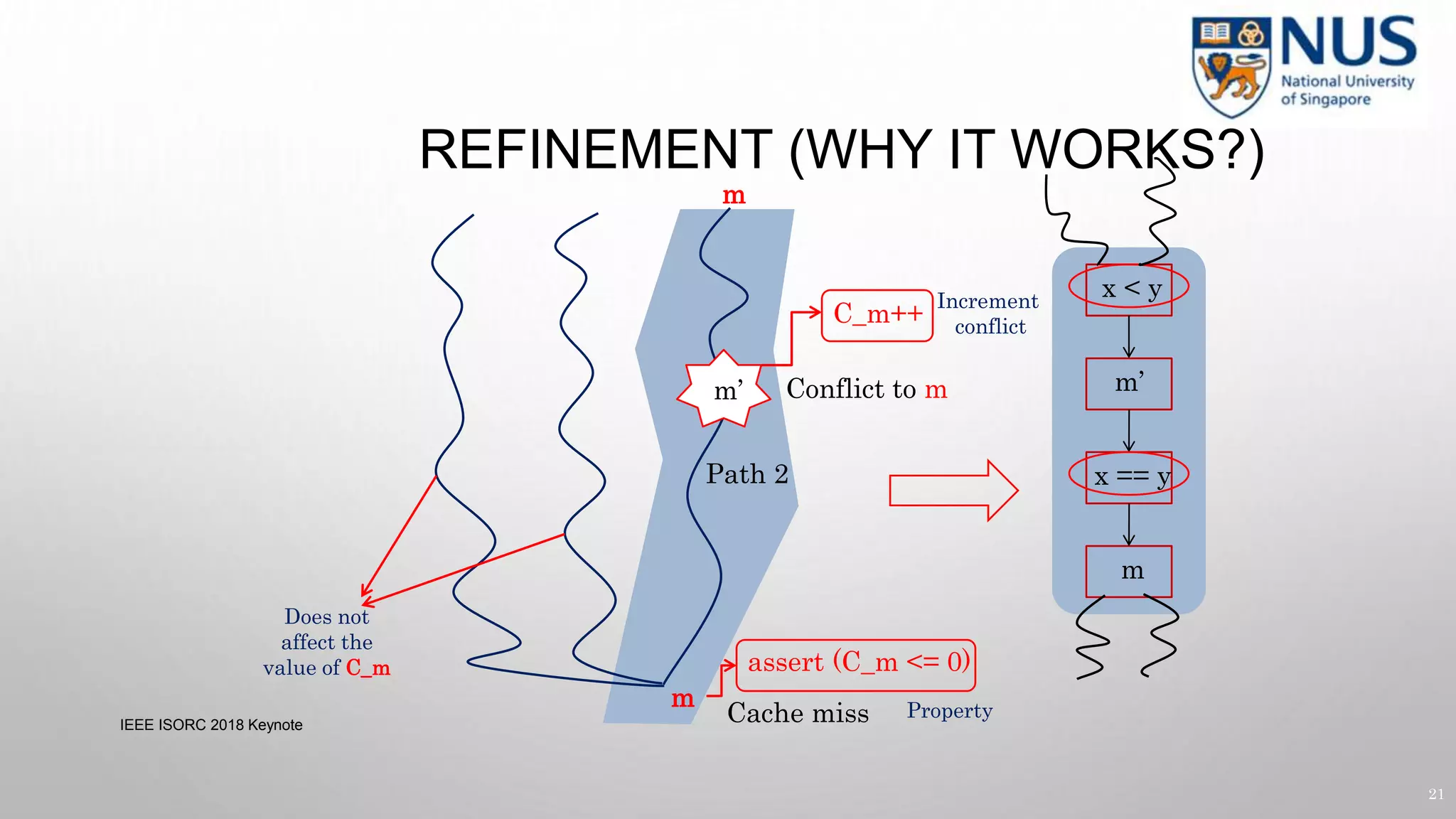
![CACHE SIDE CHANNELS
classified input (key) — key can be 0 or 1
Key = 1
HIT
load a[key]
load a[1]
load a[2]
Key = 0
MISS
🐞leak leak
load a[2]
load a[key]
load a[1]
load a[2]
load a[2]
IEEE ISORC 2018 Keynote 47](https://image.slidesharecdn.com/isorc18-keynote-181213084004/75/Isorc18-keynote-46-2048.jpg)
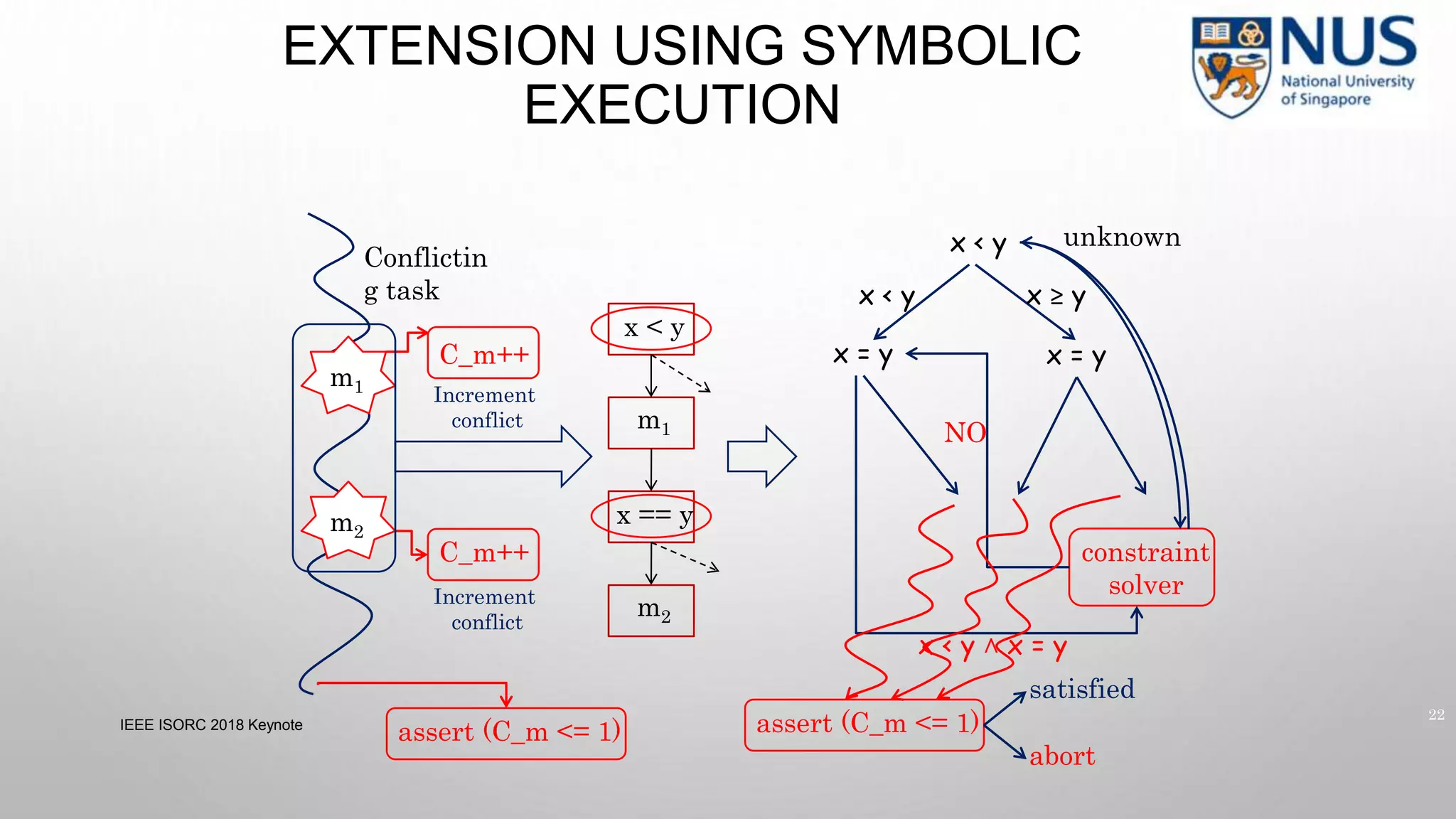
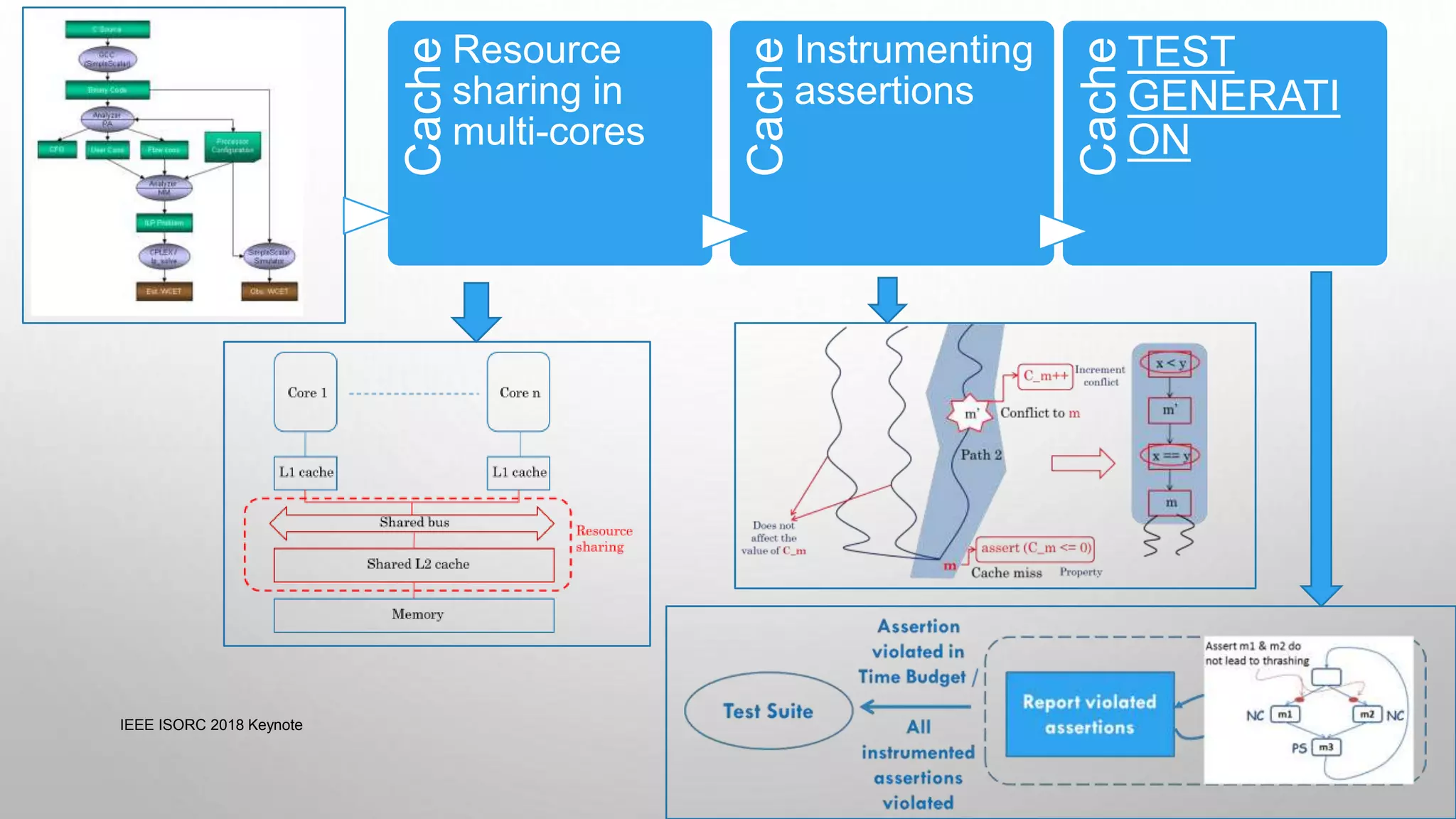
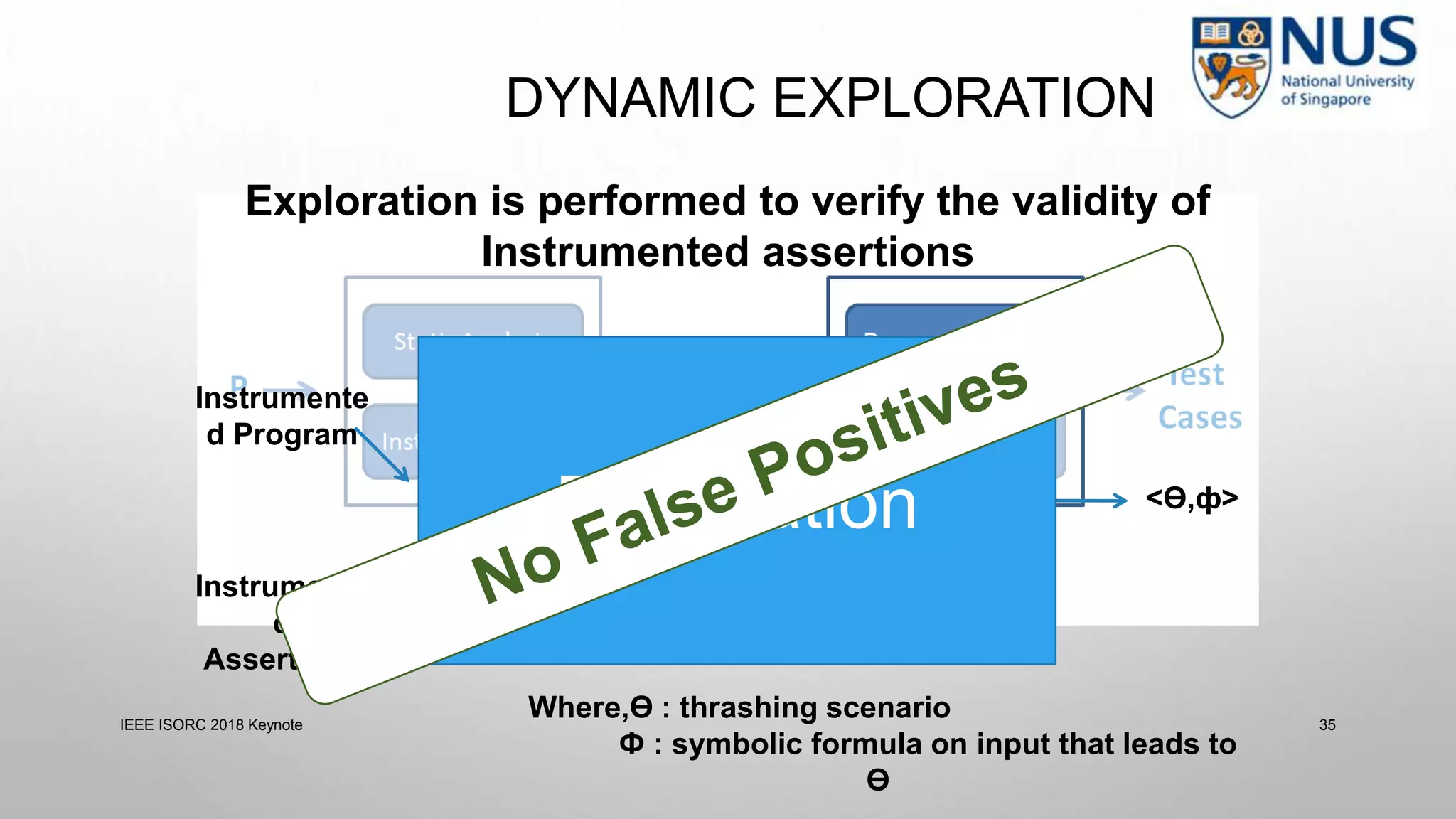
![ANALYZING CACHE SIDE CHANNELS
• Symbolically track memory address
• Expose non-functional behavior (cache misses) as functionality
• Get inputs which show specific cache miss scenarios
load a[key]
load a[1]
load a[2]
a[key] ⋀ (key = 0 ⌵ key = 1)
a[1]
a[2]
load a[2] a[2]
classified input (key) — key can be 0 or 1
48
👿IEEE ISORC 2018 Keynote 48](https://image.slidesharecdn.com/isorc18-keynote-181213084004/75/Isorc18-keynote-47-2048.jpg)
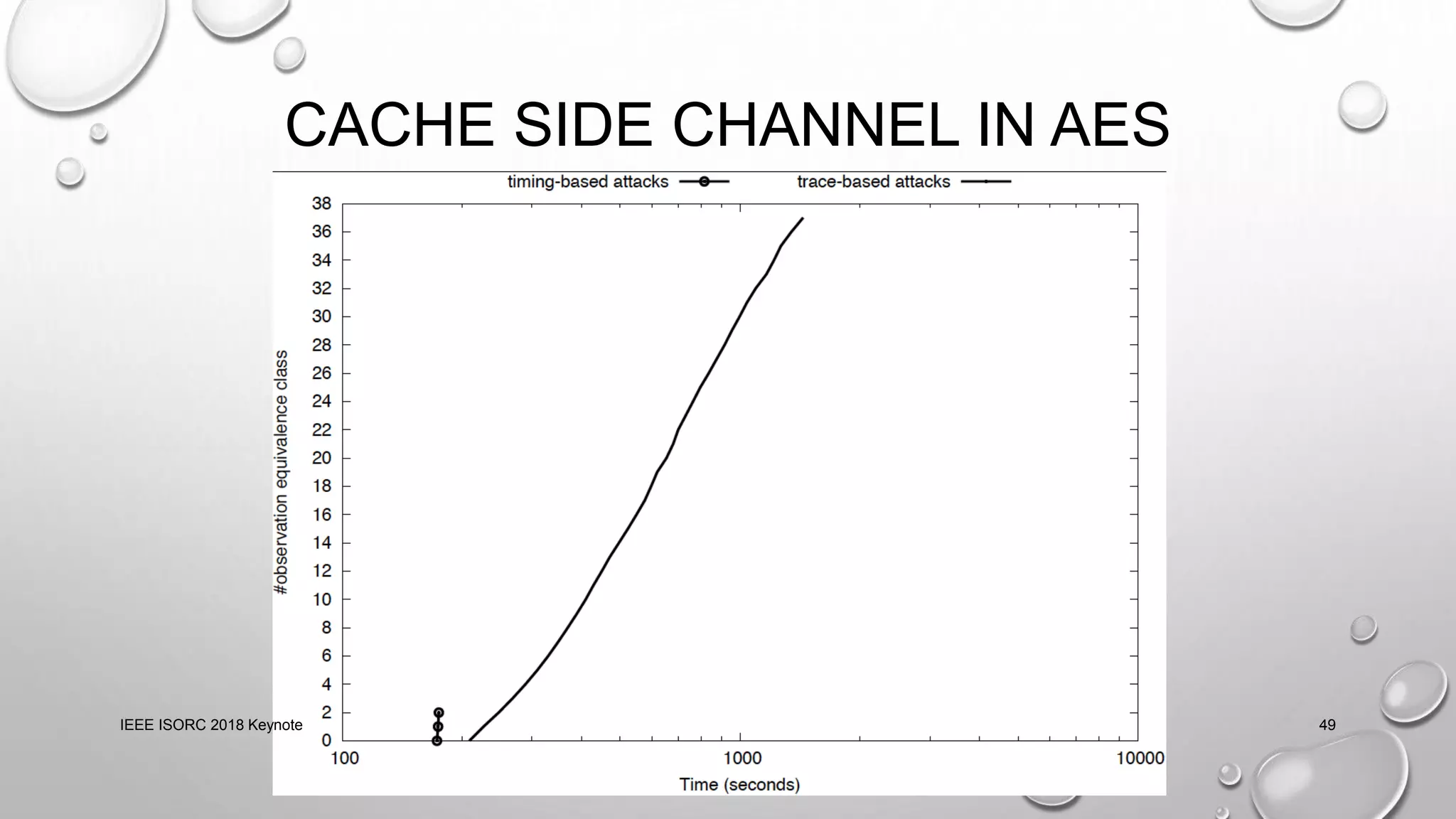
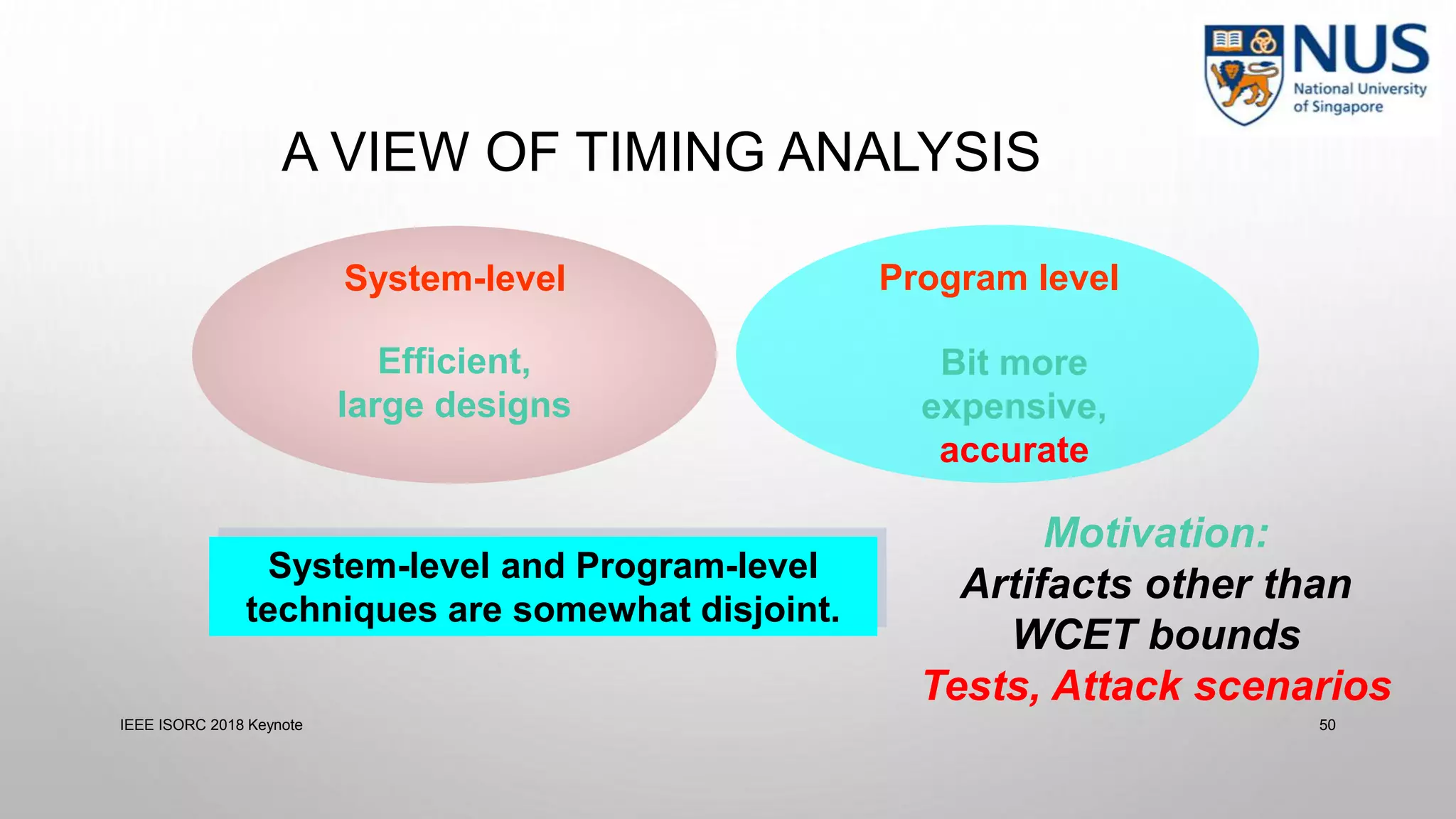
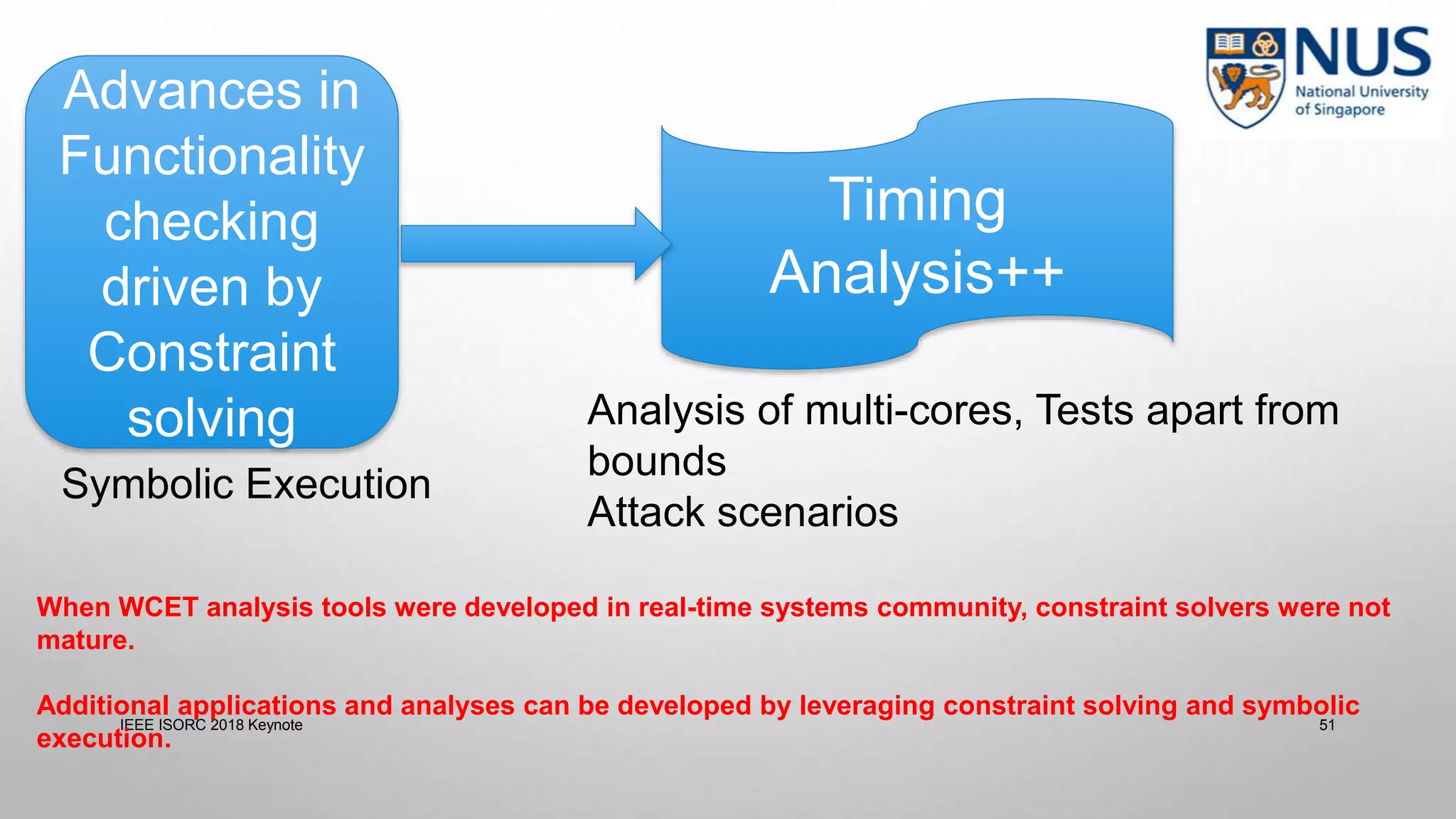

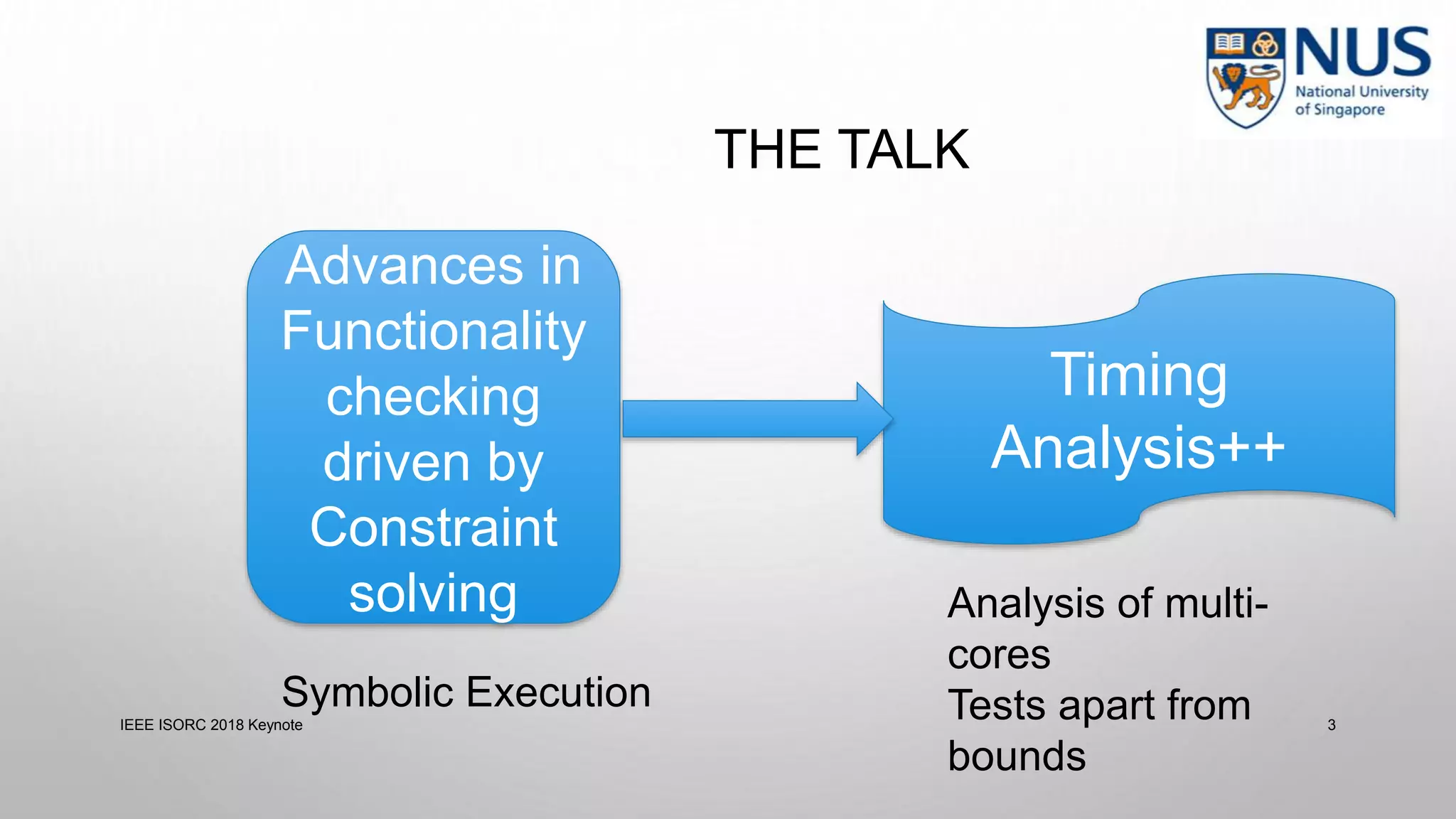
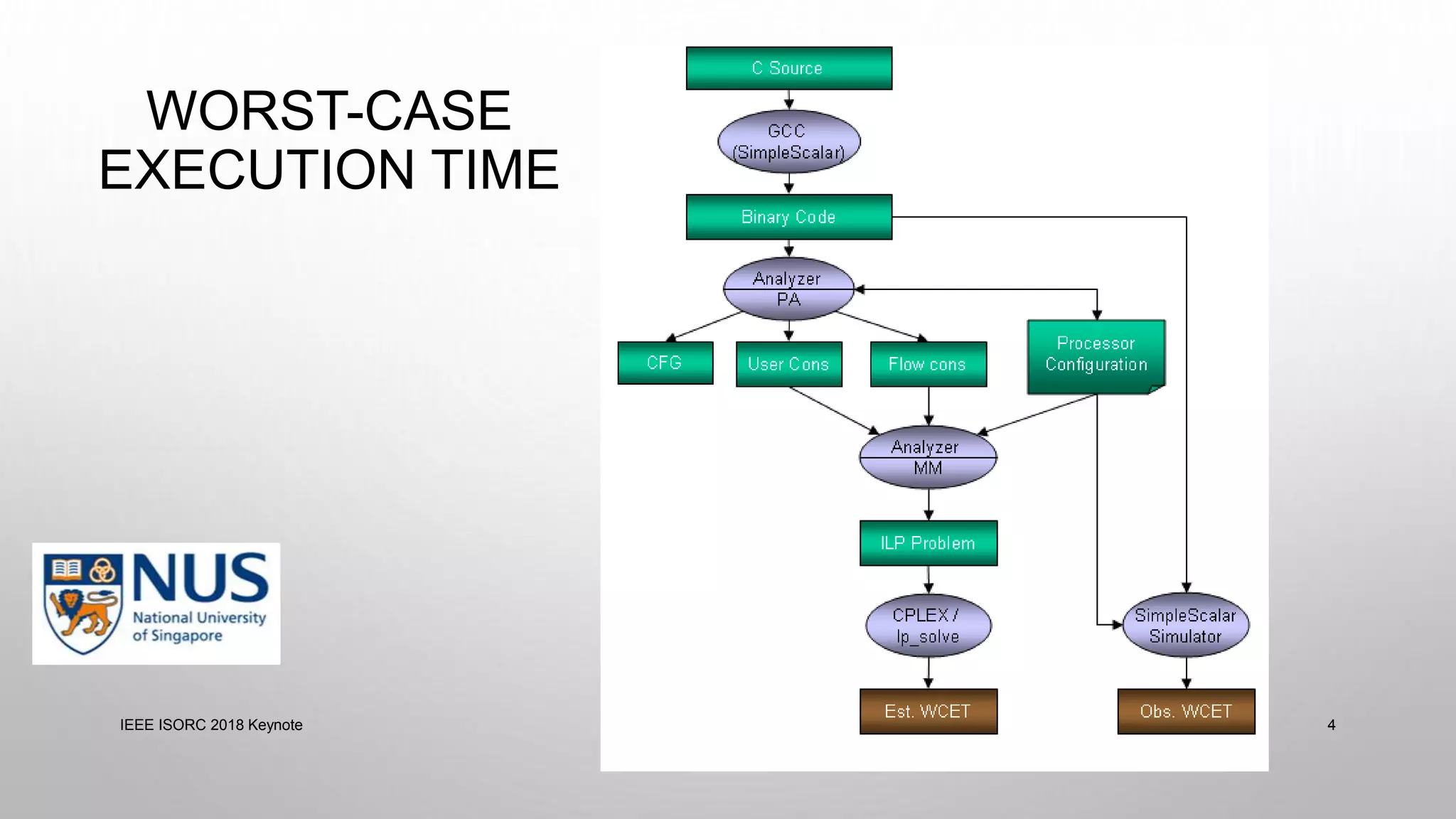
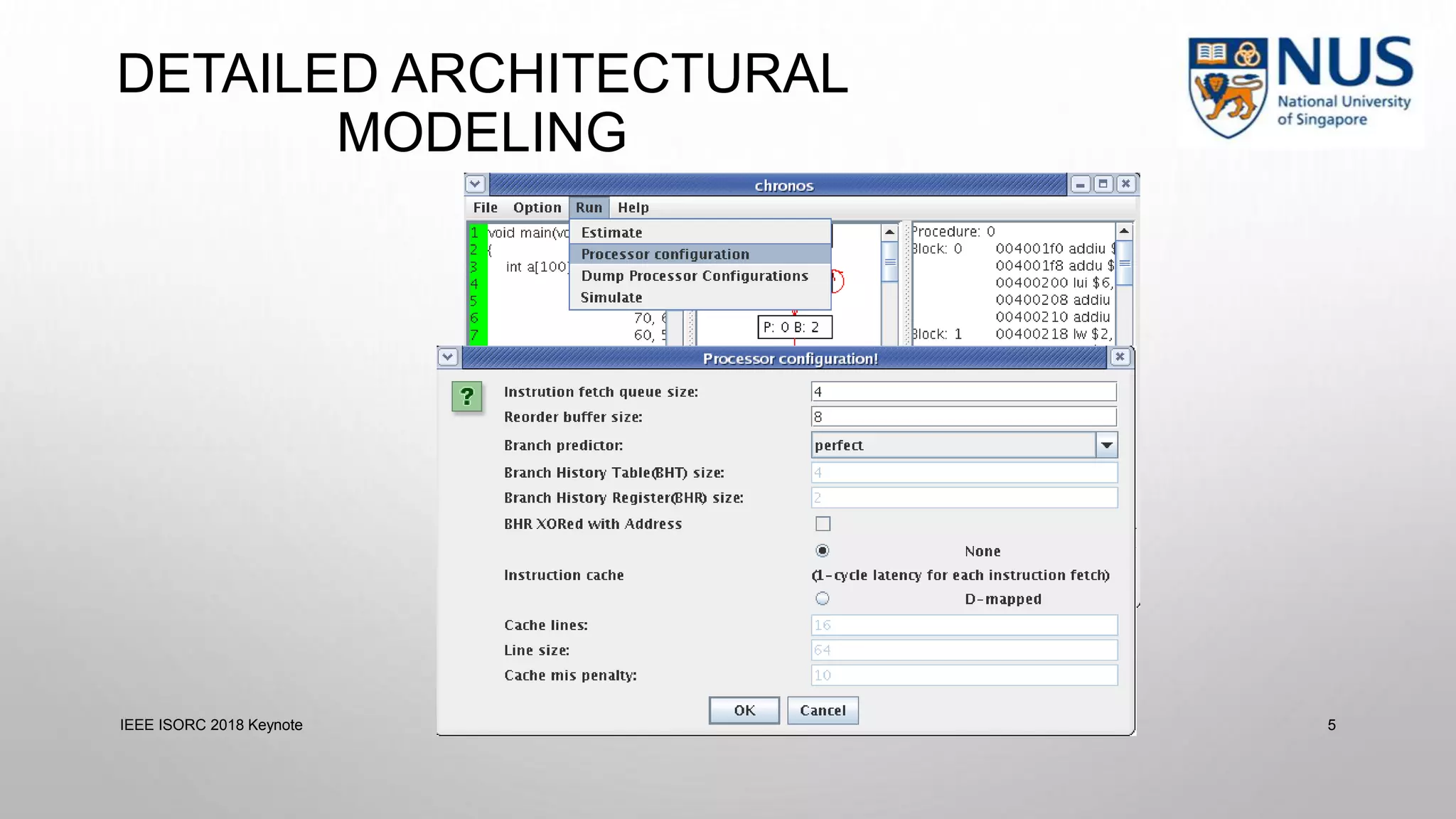
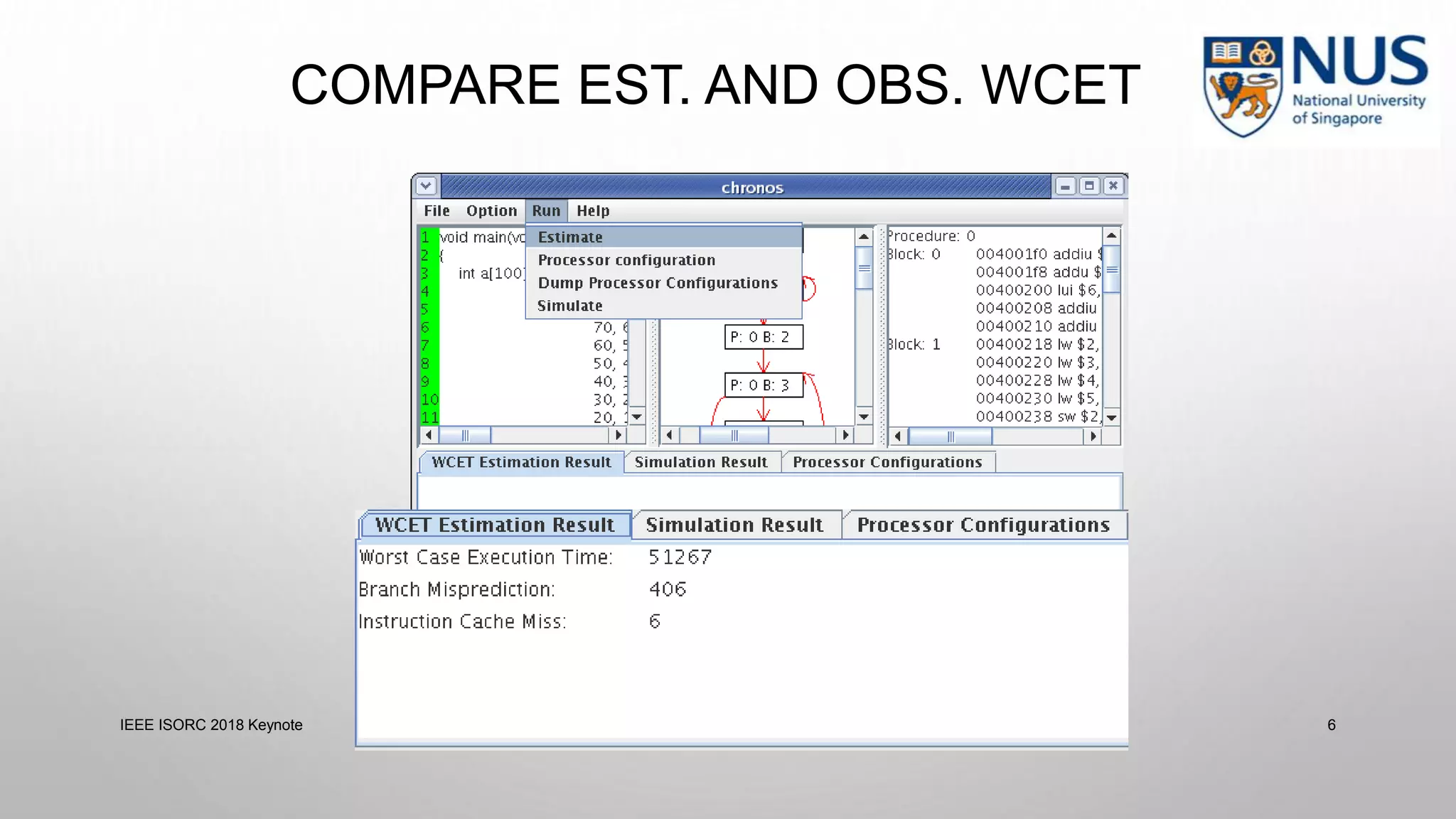
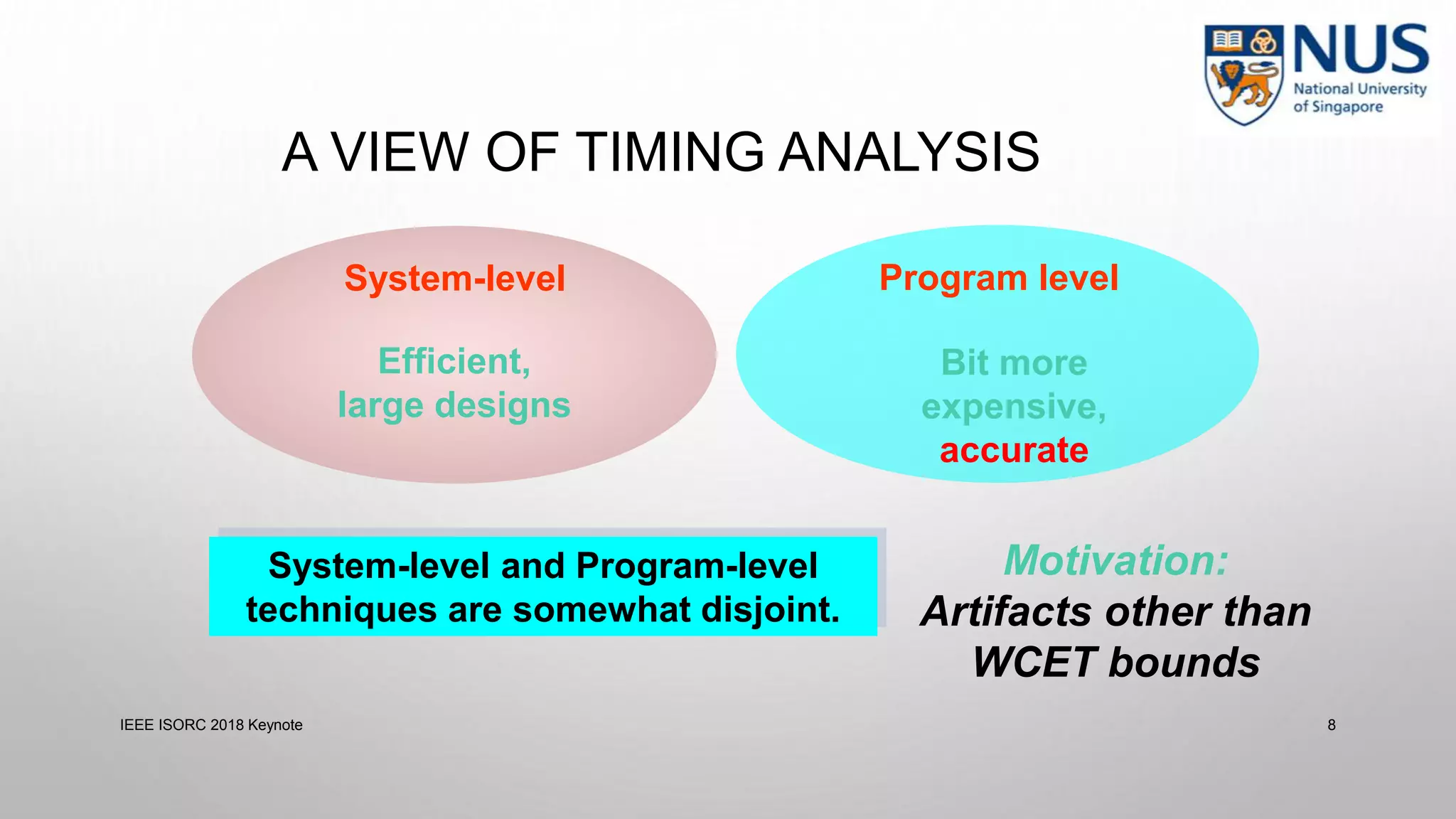
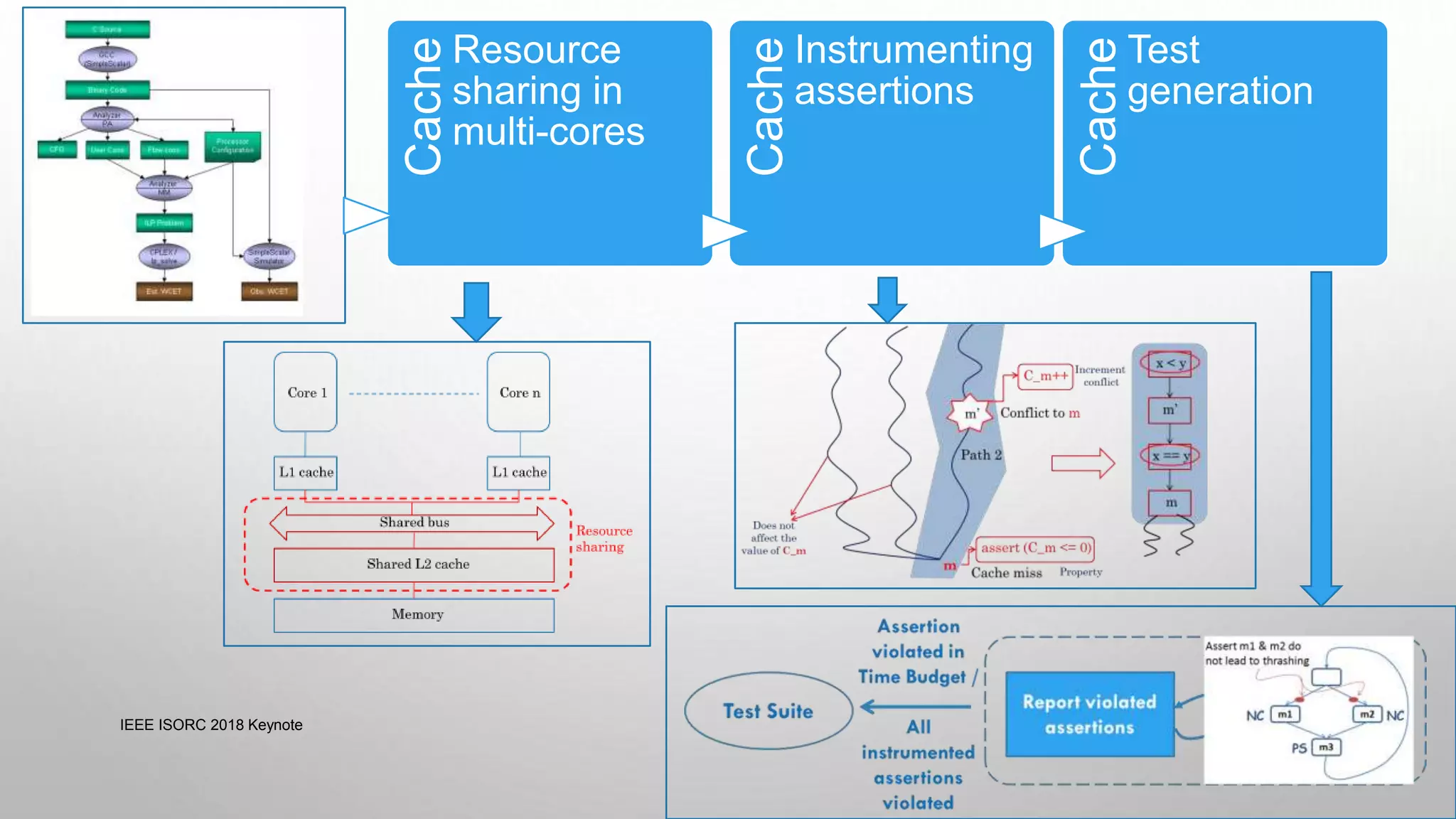
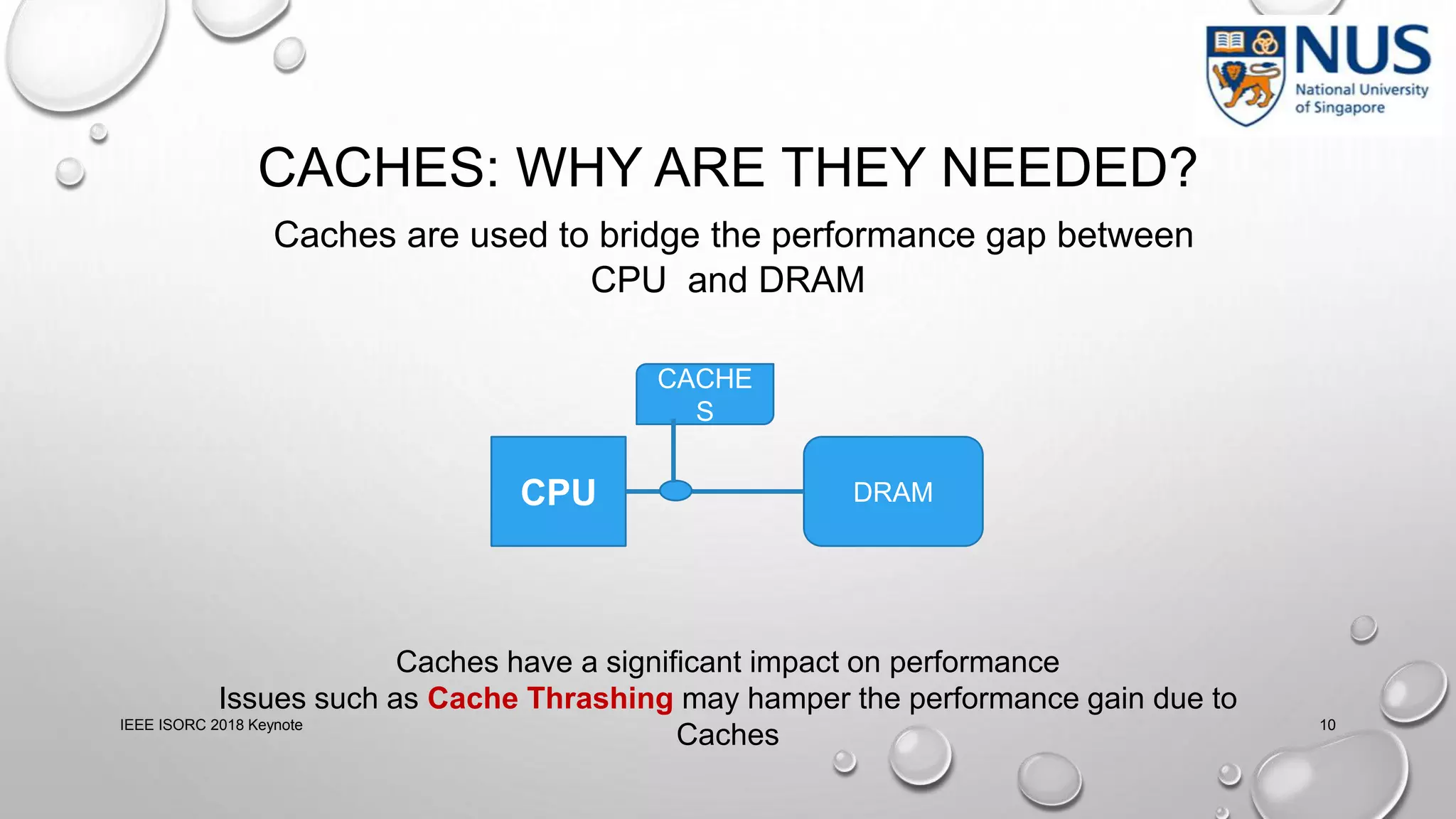
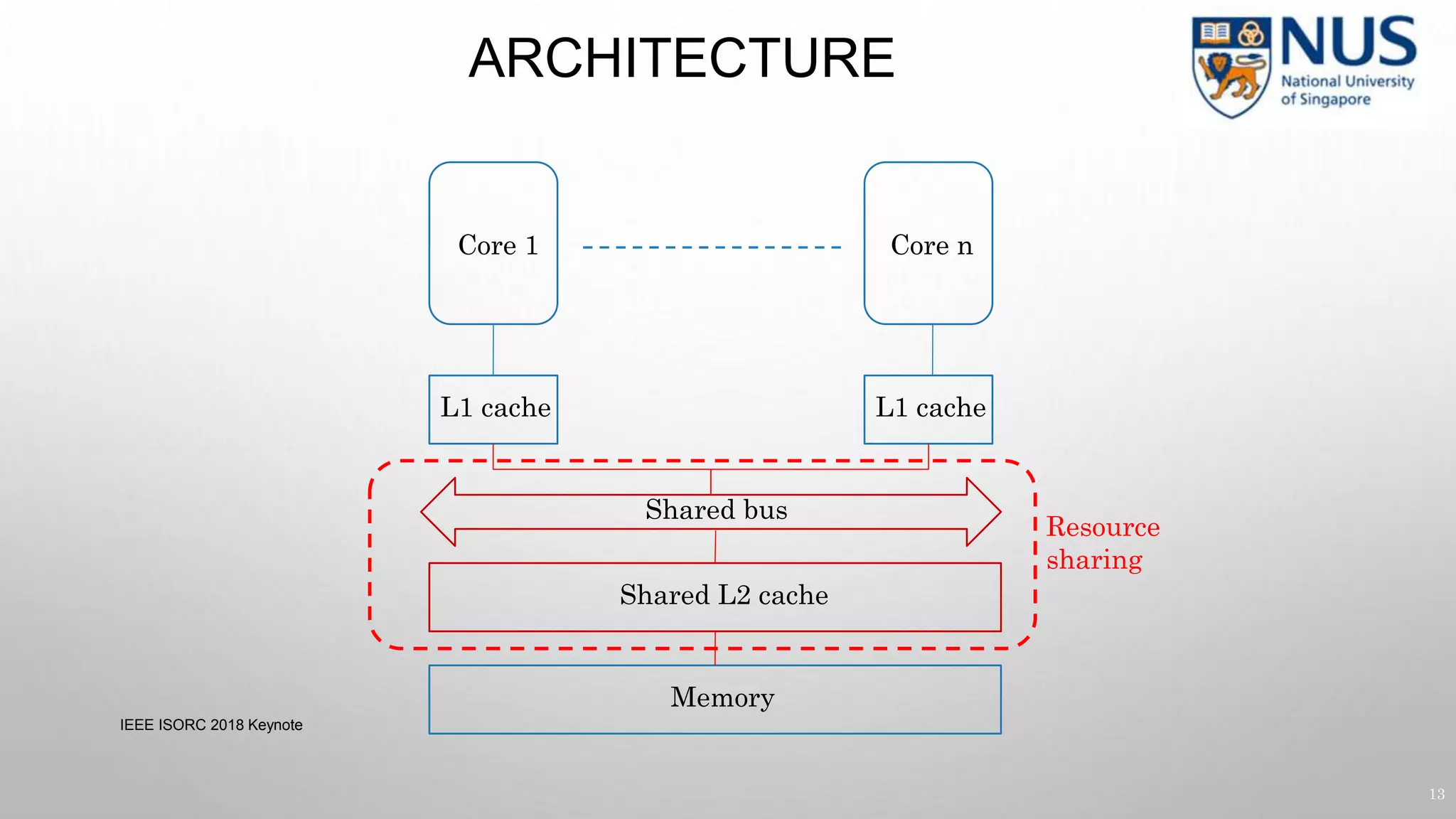
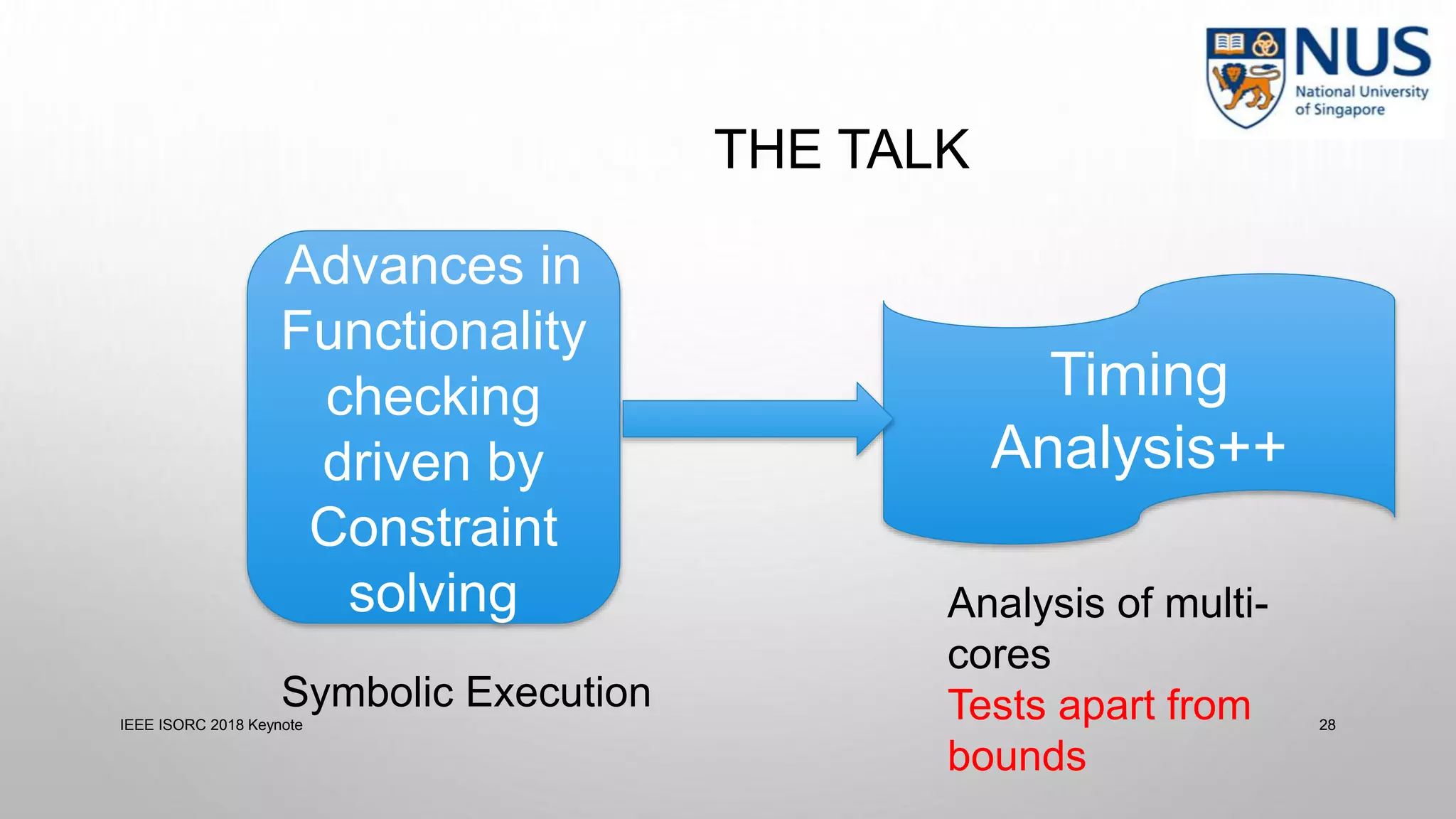
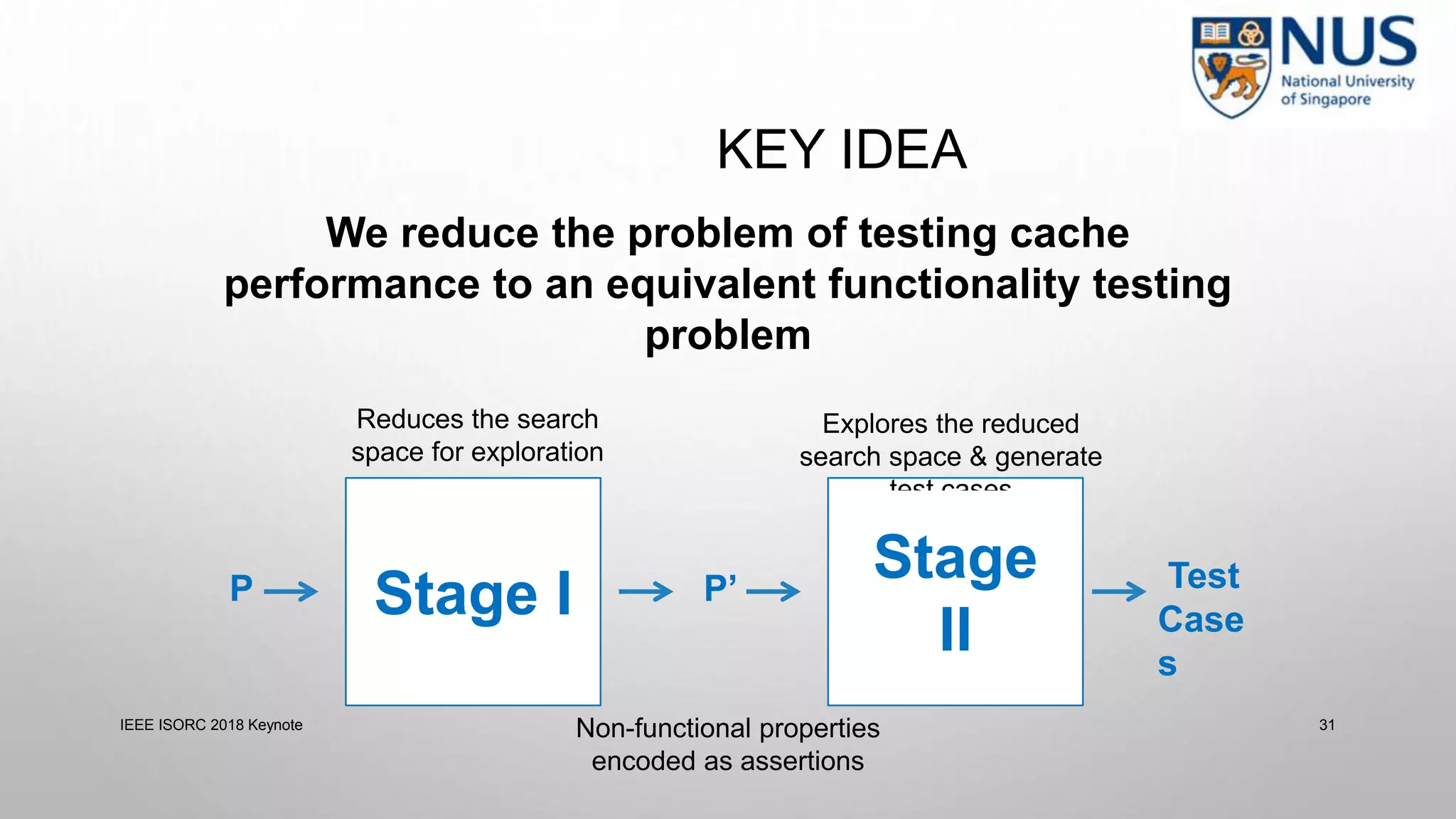
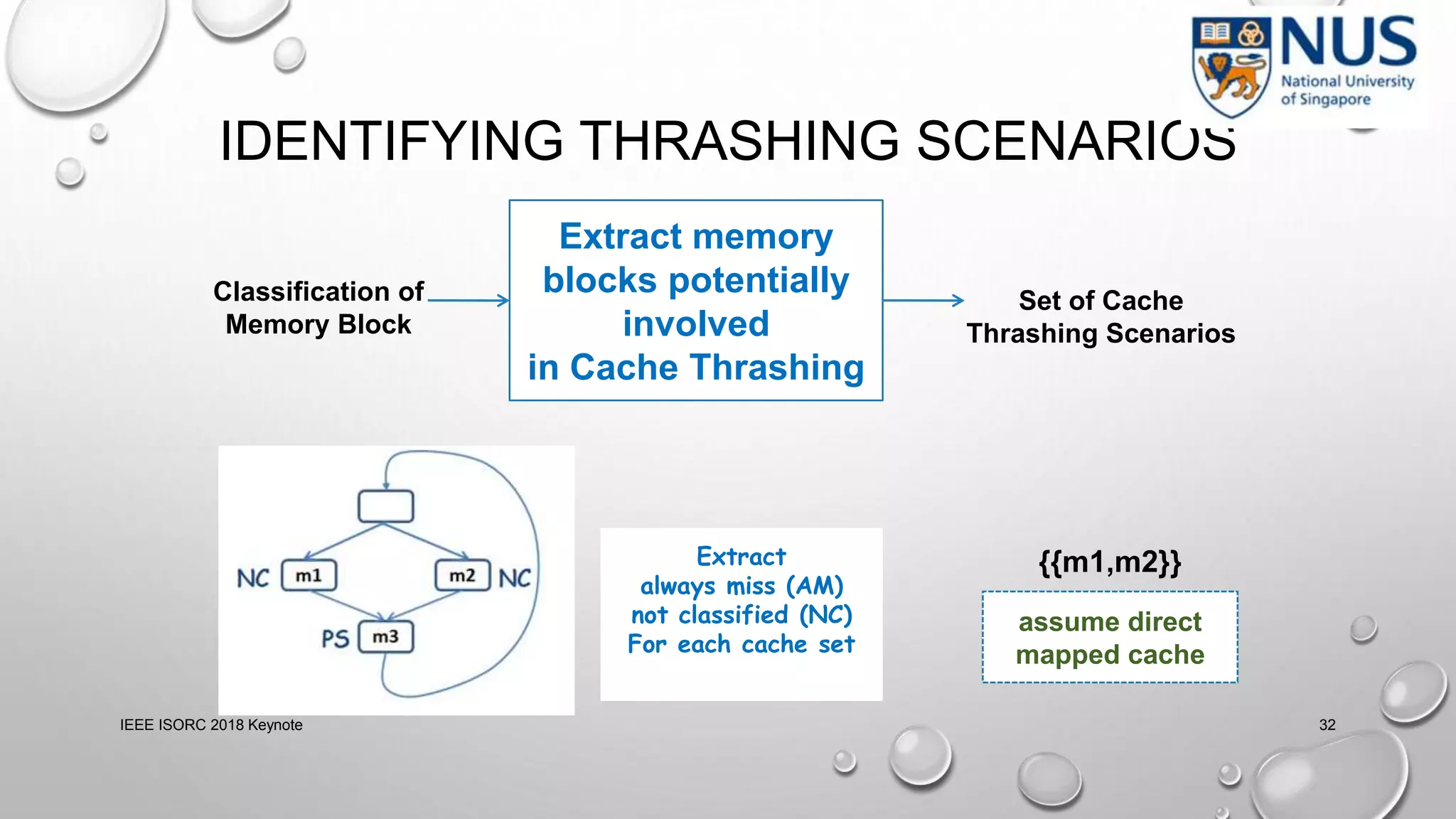
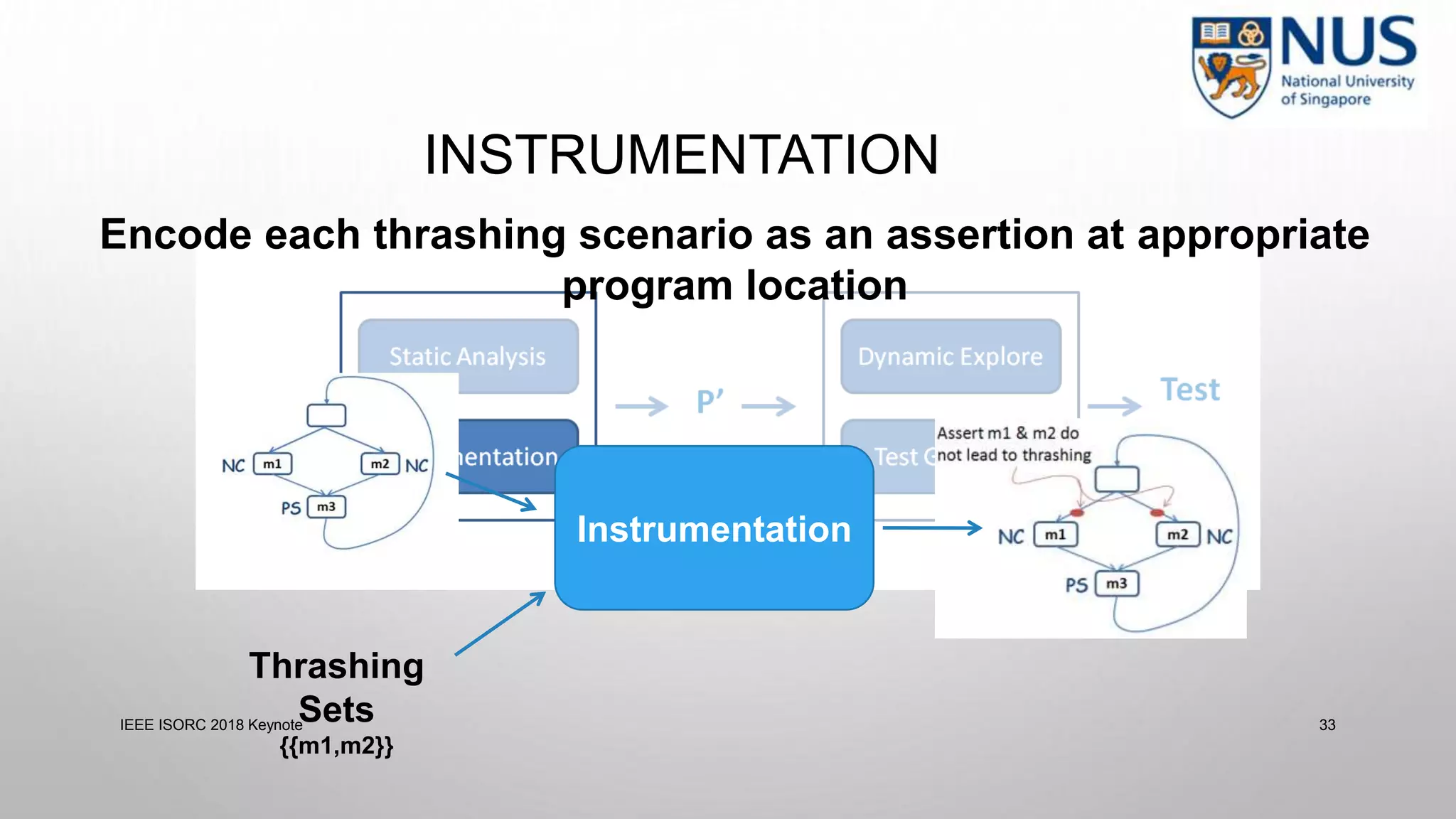
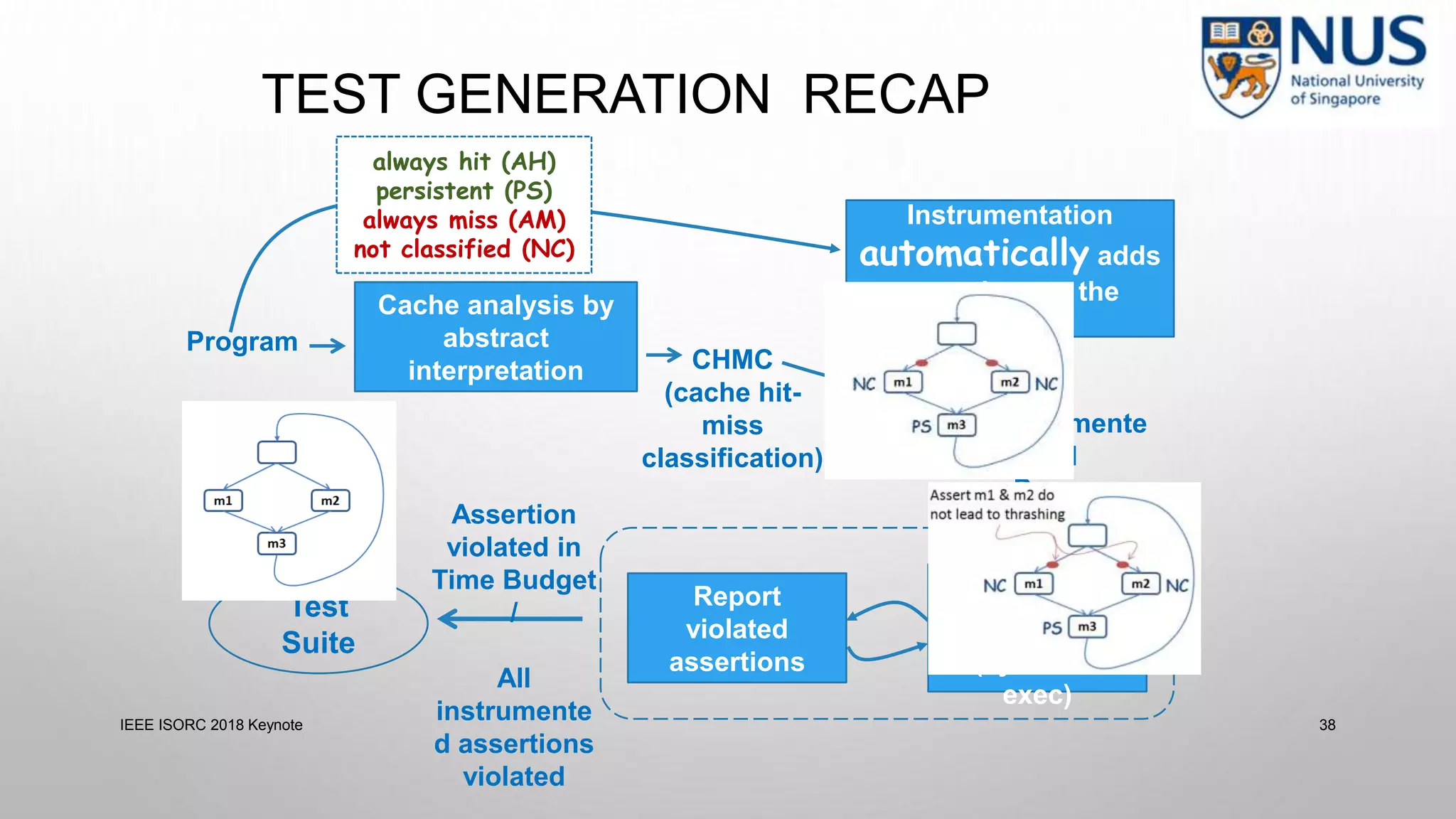
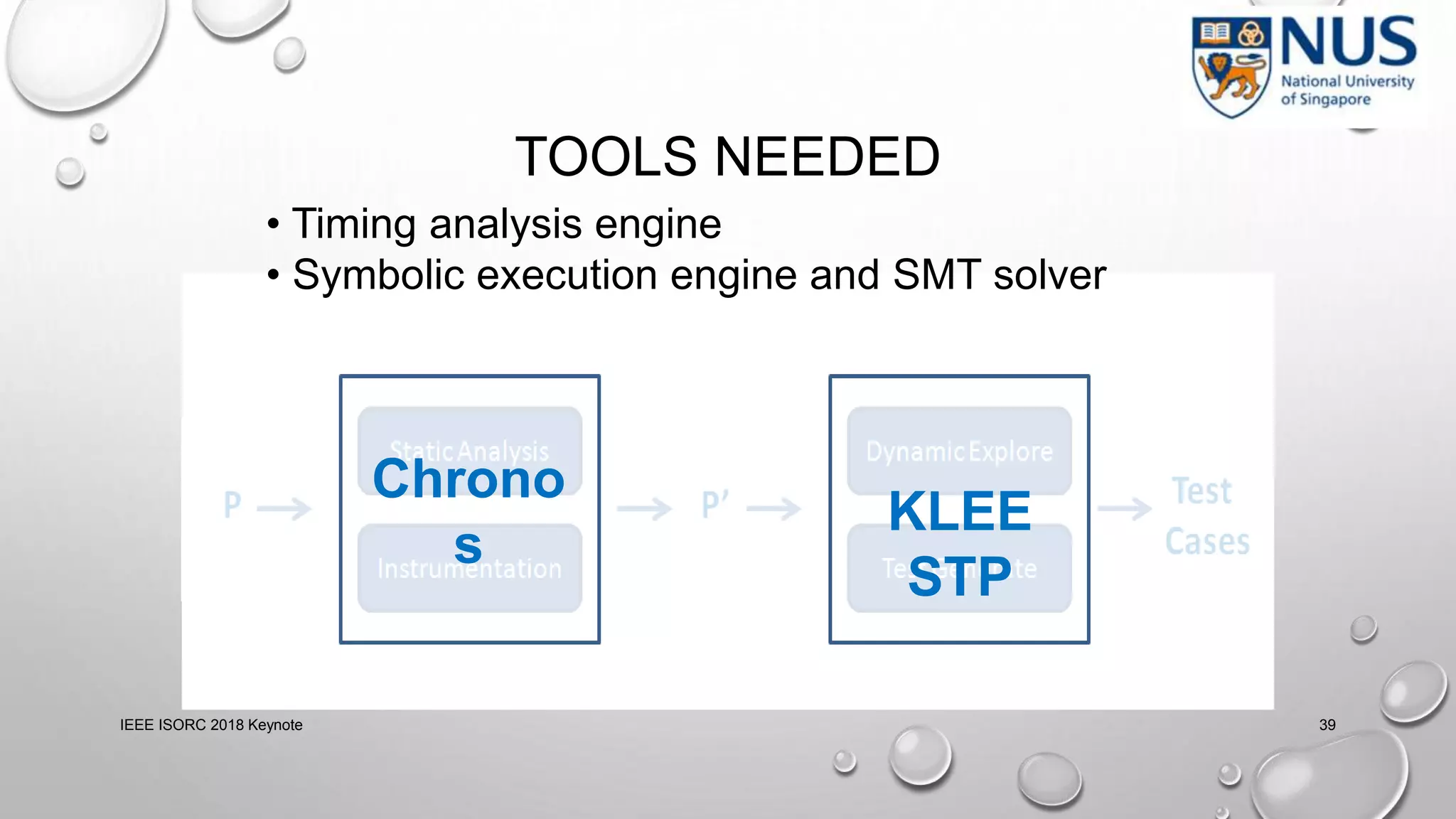
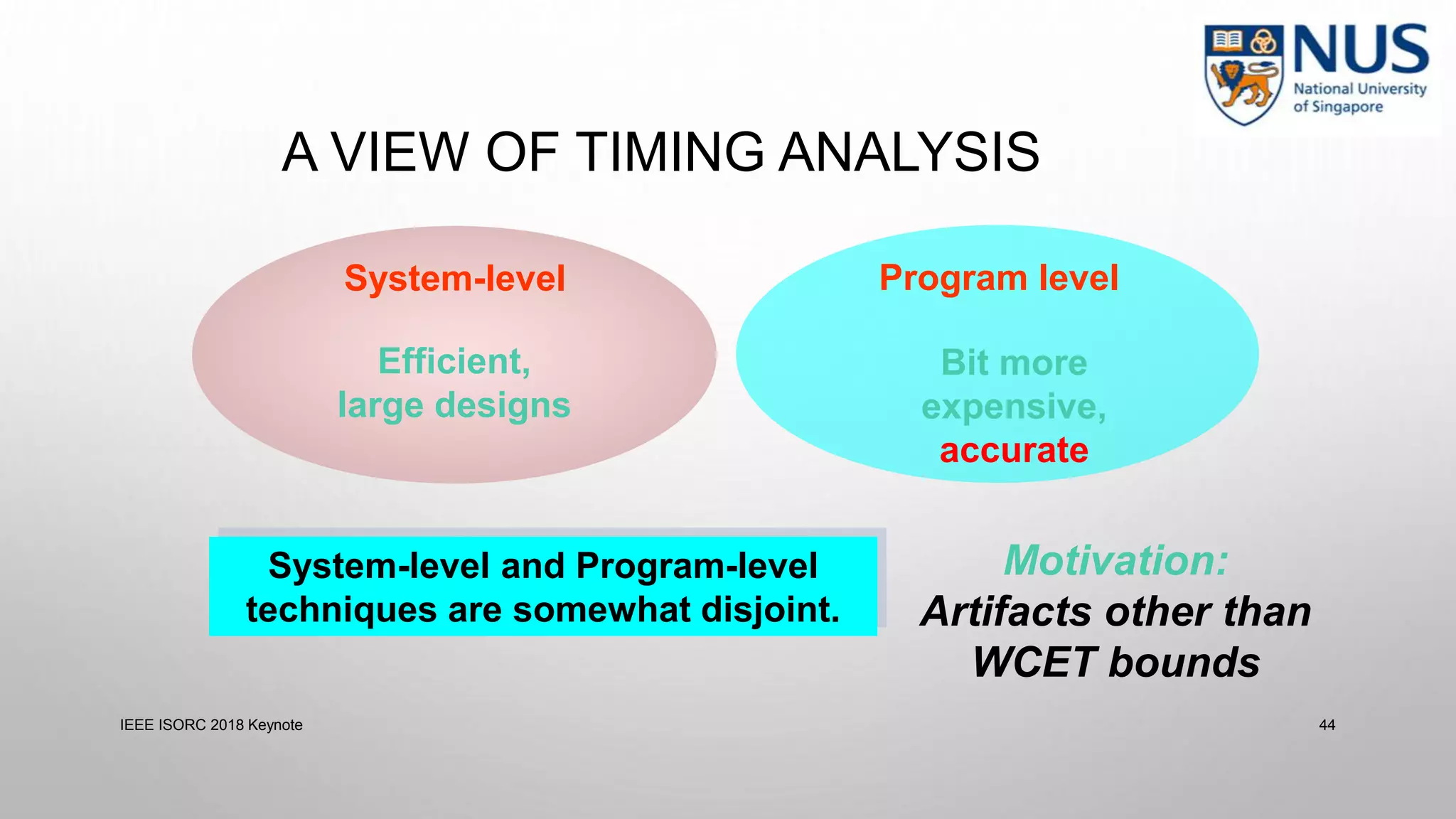
This document summarizes a keynote presentation on timing analysis and testing. It discusses several topics: - Timing analysis techniques including worst-case execution time analysis, detailed architectural modeling, and the Chronos timing analysis tool. - Cache analysis including identifying thrashing scenarios, instrumenting assertions, and using symbolic execution to generate tests that expose cache performance issues. - Applications to multi-core timing analysis, analyzing cache side channels, and generating tests or attack scenarios rather than just worst-case execution bounds. The document advocates leveraging advances in constraint solving and symbolic execution to develop additional timing analysis applications beyond traditional worst-case execution time analysis.































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)






![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)







