Download as PDF, PPTX












The document discusses IPVS (IP Virtual Server), a kernel-level load balancer that facilitates high-performance request routing for Docker containers without additional costs. It highlights IPVS's capabilities, such as its configuration flexibility, support for various protocols, and benefits like persistent connection handling and low CPU usage during high traffic. Additionally, it introduces 'gorb,' a REST API daemon for managing IPVS configurations dynamically, making it especially useful for modern cloud environments.
Overview of IPVS, its functionality, and features including load-balancing methods.
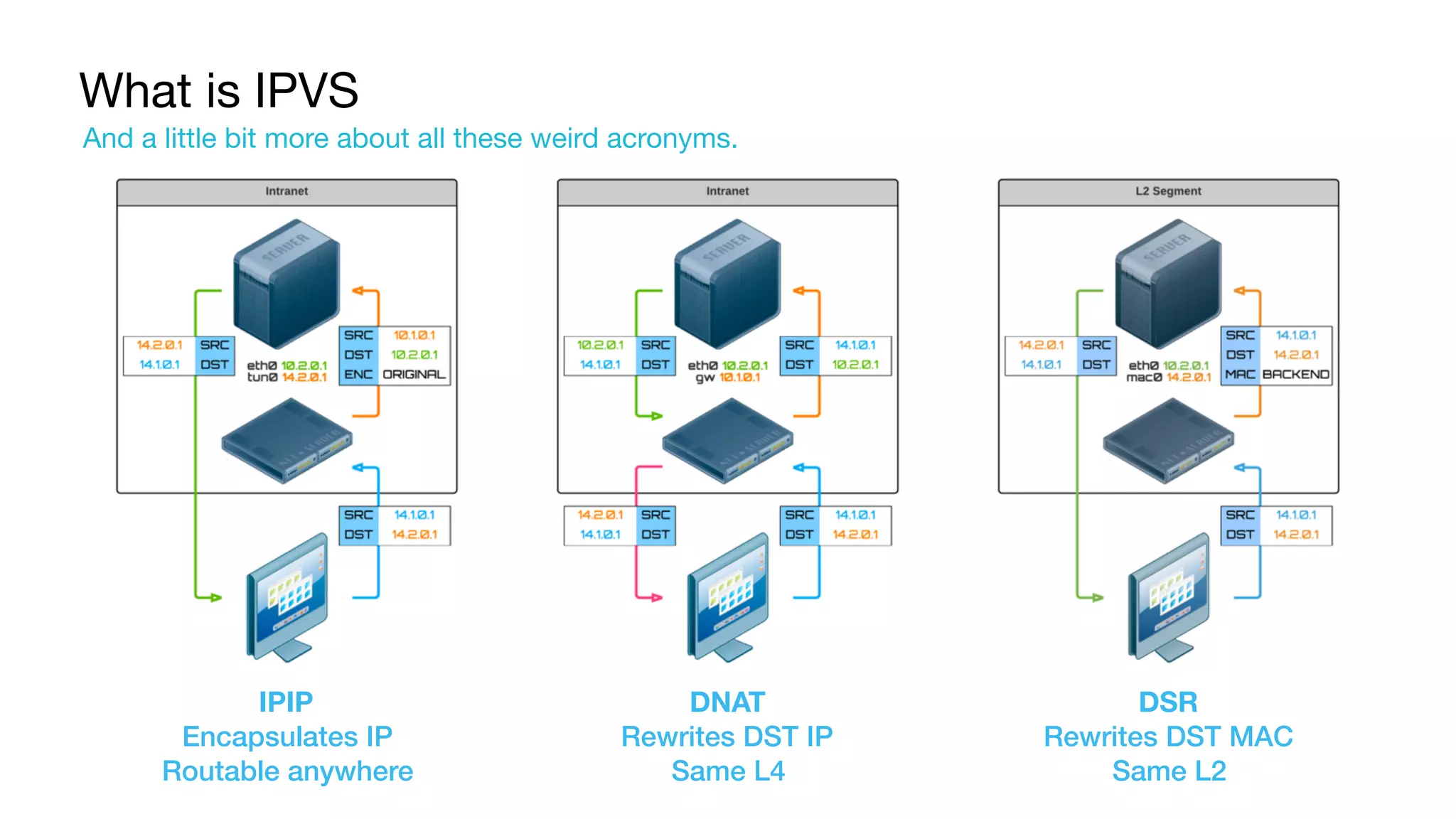
Deep dive into IPVS's operating mechanisms, types of NAT, and why load balancing is essential.
Challenges of cloud-based load balancing vs. IPVS advantages, with usage guidelines.
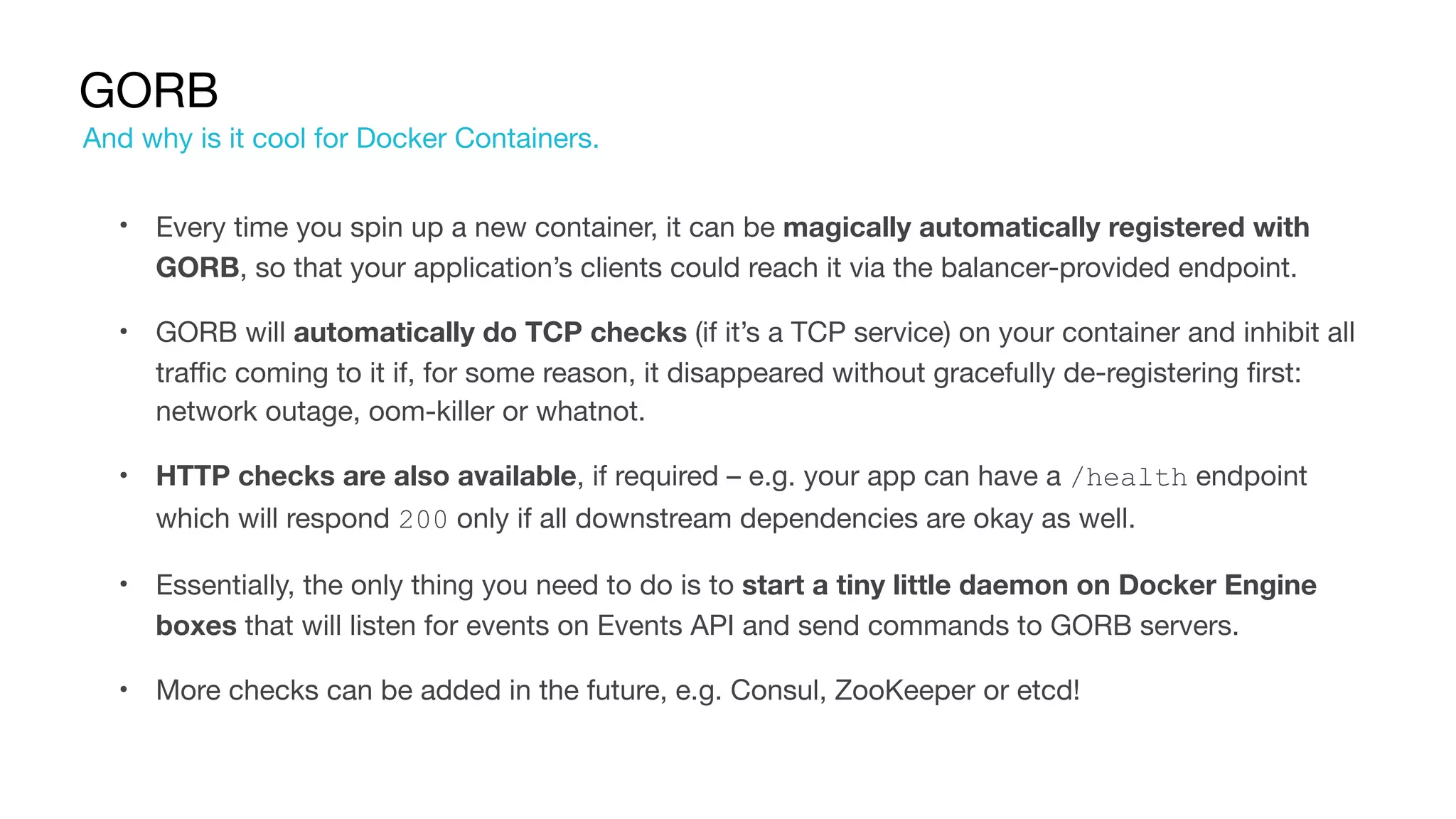
Overview of GORB, a REST API daemon for managing IPVS configurations and health checks.
Commands for setting up GORB, and introduction to BGP for routing optimization.
Summary of IPVS stability, costs, author credibility, and avenues for further questions.



































































