PEGパーザの実装(関数型)
規則 V ←"a" V / "c"の実装を考える
def parse_V(input)
r1 = match("a", input)
if r1.succeed?
r2 = parse_V(r1.output)
if r2.succeed? then r2 else match("c", input) end
else
match("c", input)
end
end
PEGパーザの実装(手続き型)
規則 V ←"a" V / "c"の実装を考える
def parse_V
backup_pos = current_pos
if match("a")
if parse_V then return true
rewind(backup_pos); return match("c")
else
return match("c")
end
end
Backtrack parsing
E ←V "+" E / V
V ← "a" / "b" / "c"
E(1)
V(1)
"a"
"+" E(3)
V(3)
"a" "b"
V(3)
"a" "b"
"+"
式: E, 入力:"a+b"
同じ計算を二度行う
26.
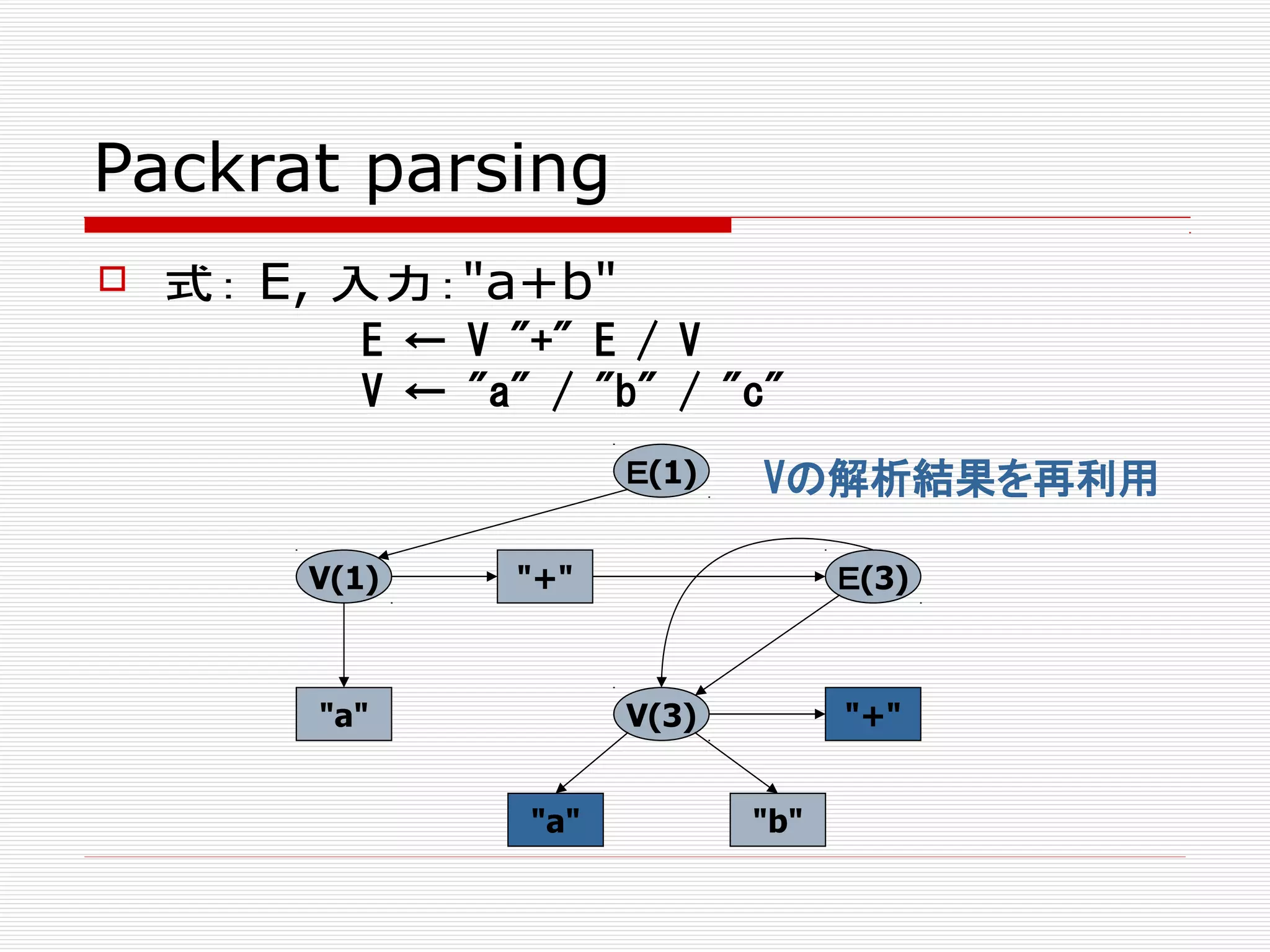
Packrat parsing
E ←V "+" E / V
V ← "a" / "b" / "c"
E(1)
V(1)
"a"
"+" E(3)
V(3)
"a" "b"
"+"
式: E, 入力:"a+b"
Vの解析結果を再利用
27.
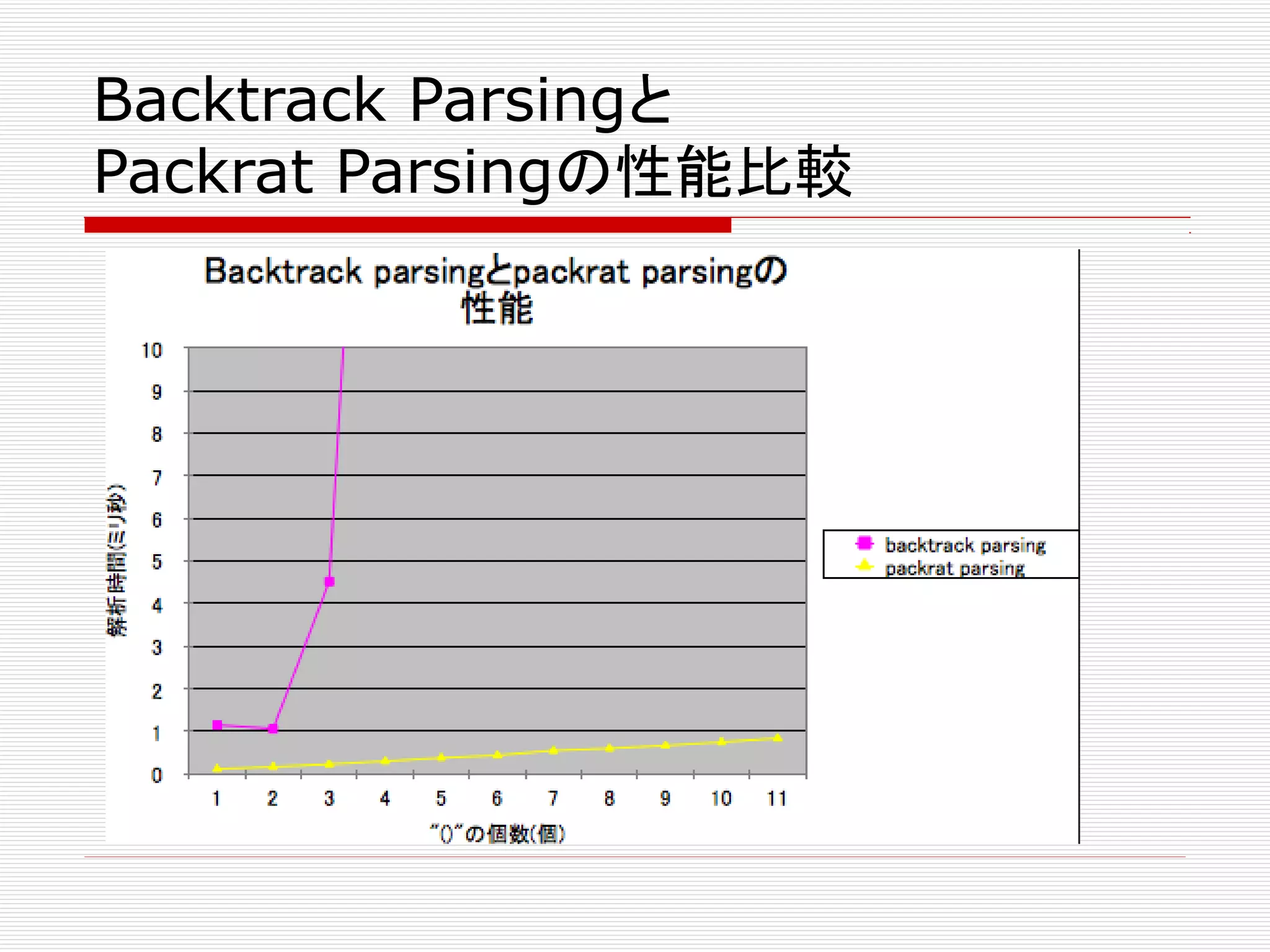
Backtrack Parsingと
Packrat Parsingの性能比較
次の文法の言語を解析する時の性能を比較
Backtrackが頻発する入力を与える
入力: '(1)', '((1))', '(((1)))', …
E ← M
M ← A Spacing MS / A
MS ← "*" Spacing M / "/" Spacing M / "%" Spacing M
A ← P Spacing AS / P
AS ← "+" Spacing A / "-" Spacing A
P ← Number / "(" Spacing E Spacing ")"









![Parsing Expression(1)
N : 規則(非終端記号)の参照
"a" : 文字列a
ε : 空文字列
. : 任意の一文字
[...] : 文字クラス
e1 e2 : e1とe2の並び
e1 / e2 : e1を試し、失敗したらe2を試す
e1 / e2 ≠ e2 / e1](https://image.slidesharecdn.com/introductiontopeg-150808064612-lva1-app6892/75/Introduction-to-PEG-10-2048.jpg)












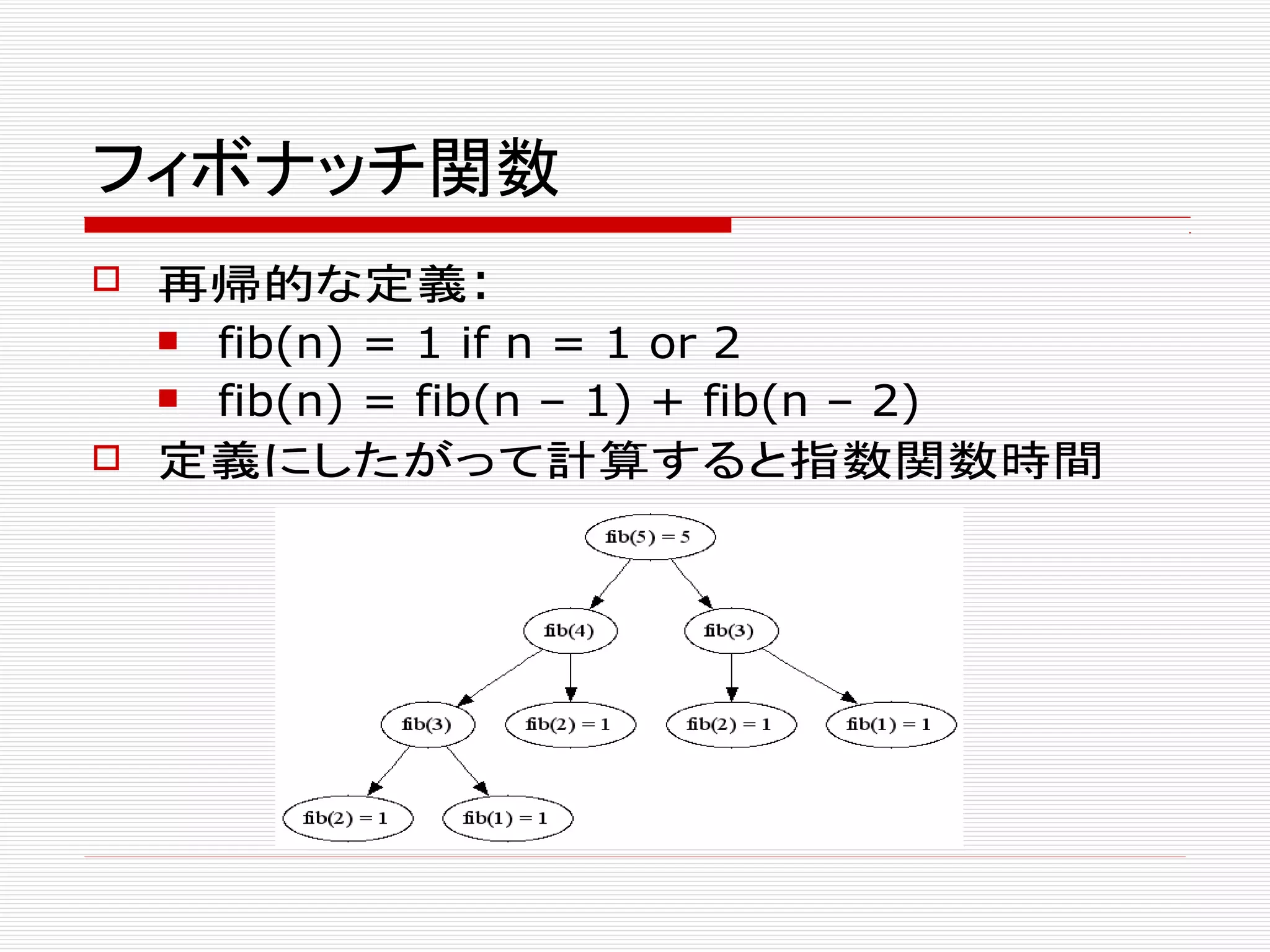
![メモ化されたフィボナッチ関数
同じ引数に対して、計算結果を再利用
fib(n) = m[n] if m[n] != null
fib(n) = m[n]:=1 ; m[n] if n = 1 or 2
fib(n) = m[n]:=fib(n–1)+fib(n–2); m[n]
入力の大きさに対して線形時間](https://image.slidesharecdn.com/introductiontopeg-150808064612-lva1-app6892/75/Introduction-to-PEG-24-2048.jpg)

















































![[Basic 11] 文脈自由文法 / 構文解析 / 言語解析プログラミング](https://cdn.slidesharecdn.com/ss_thumbnails/basic-11-180306134245-thumbnail.jpg?width=640&height=640&fit=bounds)












![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)





























