Download as PDF, PPTX





























![NERC: Features 36
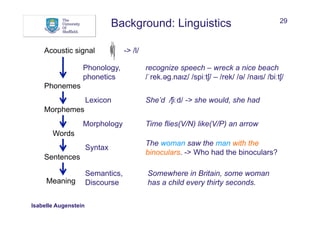
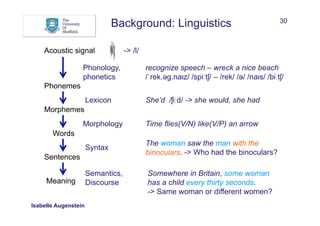
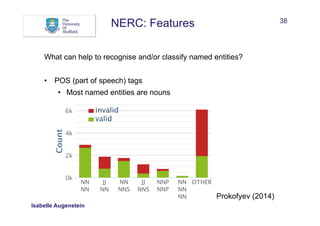
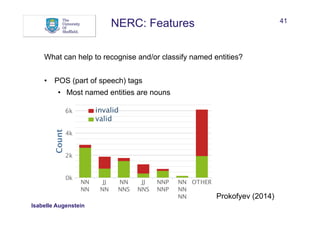
What can help to recognise and/or classify named entities?
• Words:
• Words in window before and after mention
• Sequences
• Bags of words
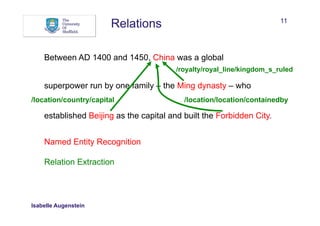
Between AD 1400 and 1450, China was a global superpower
w: China w-1: , w-2: 1450 w+1: was w+2: a
seq[-]: 1450, seq[+]: was a
bow: China bow[-]: , bow[-]: 1450 bow[+]: was bow[+]: a
Isabelle Augenstein](https://image.slidesharecdn.com/isabelle-nlp-140907045015-phpapp01/85/Natural-Language-Processing-for-the-Semantic-Web-36-320.jpg)








The document discusses Natural Language Processing (NLP) and its application in linking semi-structured and unstructured information to knowledge bases, highlighting techniques such as named entity recognition (NER), relation extraction, temporal extraction, and event extraction. It emphasizes different methodologies for implementing NER, including rule-based, supervised, unsupervised, and semi-supervised approaches, as well as the importance of linguistic features for effective entity classification. The challenges posed by language ambiguity and the need for background knowledge in entity extraction are also addressed.

















































































