





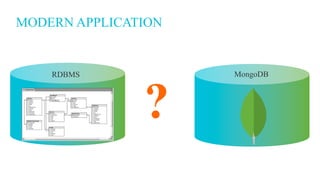







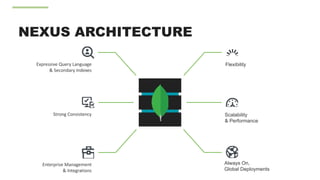


![DOCUMENT DATA MODEL
Relational MongoDB
{
first_name: ‘Paul’,
surname: ‘Miller’,
city: ‘London’,
location: [45.123,47.232],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
]
}](https://image.slidesharecdn.com/when-to-use-mongodb-v2-678e24de-57e6-4cb8-adef-b182516a098a-2073269434-170920174002/85/When-to-Use-MongoDB-19-320.jpg)
![DOCUMENTS ARE RICH DATA STRUCTURES
{
first_name: ‘Paul’,
surname: ‘Miller’,
cell: 447557505611,
city: ‘London’,
location: [45.123,47.232],
Profession: [‘banking’, ‘finance’, ‘trader’],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
]
}
Fields can contain an array of sub-
documents
Fields
Typed field values
Fields can contain
arrays](https://image.slidesharecdn.com/when-to-use-mongodb-v2-678e24de-57e6-4cb8-adef-b182516a098a-2073269434-170920174002/85/When-to-Use-MongoDB-20-320.jpg)
![DOCUMENTS ARE FLEXIBLE
Documents in the same product catalog collection in MongoDB
{
product_name: ‘Acme Paint’,
color: [‘Red’, ‘Green’],
size_oz: [8, 32],
finish: [‘satin’, ‘eggshell’]
}
{
product_name: ‘T-shirt’,
size: [‘S’, ‘M’, ‘L’, ‘XL’],
color: [‘Heather Gray’ … ],
material: ‘100% cotton’,
wash: ‘cold’,
dry: ‘tumble dry low’
}
{
product_name: ‘Mountain Bike’,
brake_style: ‘mechanical disc’,
color: ‘grey’,
frame_material: ‘aluminum’,
no_speeds: 21,
package_height: ‘7.5x32.9x55’,
weight_lbs: 44.05,
suspension_type: ‘dual’,
wheel_size_in: 26
}](https://image.slidesharecdn.com/when-to-use-mongodb-v2-678e24de-57e6-4cb8-adef-b182516a098a-2073269434-170920174002/85/When-to-Use-MongoDB-21-320.jpg)
![DO MORE WITH YOUR DATA
{
first_name: ‘Paul’,
surname: ‘Miller’,
city: ‘London’,
location: [45.123,47.232],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
}
}
Rich Queries
Find everybody in London with a car
built between 1970 and 1980
Geospatial
Find all of the car owners within 5km
of Trafalgar Sq.
Search
Find all the cars described as having
leather seats. Count them by model.
(text, facets, collation)
Aggregation
Calculate the average value of Paul’s
car collection
Graph
Find all the cars own by Paul’s family
(descendants)
Map Reduce
What is the ownership pattern of
colors by geography over time?
(is purple trending up in China?)](https://image.slidesharecdn.com/when-to-use-mongodb-v2-678e24de-57e6-4cb8-adef-b182516a098a-2073269434-170920174002/85/When-to-Use-MongoDB-22-320.jpg)














![REMEMBER THIS?
{
first_name: ‘Paul’,
surname: ‘Miller’,
city: ‘London’,
location: [45.123,47.232],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
}
}
Rich Queries
Find everybody in London with a car
built between 1970 and 1980
Geospatial
Find all of the car owners within 5km
of Trafalgar Sq.
Search
Find all the cars described as having
leather seats. Count them by model.
(text, facets, collation)
Aggregation
Calculate the average value of Paul’s
car collection
Graph
Find all the cars own by Paul’s family
(descendants)
Map Reduce
What is the ownership pattern of
colors by geography over time?
(is purple trending up in China?)](https://image.slidesharecdn.com/when-to-use-mongodb-v2-678e24de-57e6-4cb8-adef-b182516a098a-2073269434-170920174002/85/When-to-Use-MongoDB-47-320.jpg)













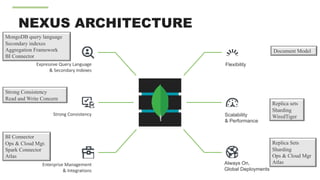





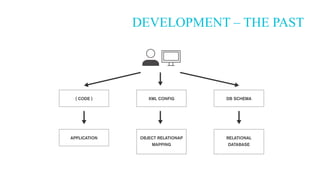
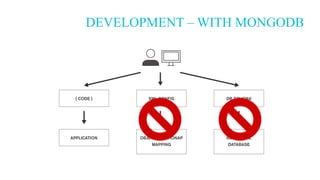
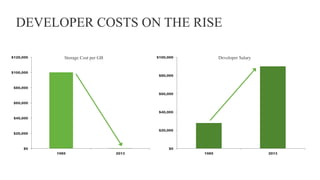
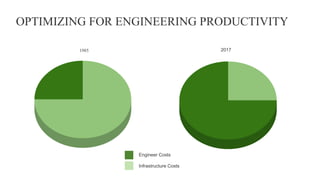
The document discusses the suitability of MongoDB as a database solution, outlining scenarios when it is advantageous to use versus when it isn't. It emphasizes the productivity gains and cost reductions achievable with MongoDB, particularly in the context of modern applications that require flexibility to handle changing data structures. The architect also evaluates the importance of assessing use cases against the capabilities of MongoDB, highlighting features such as scalability, rich data modeling, and efficient handling of complex queries.











![[MongoDB.local Bengaluru 2018] Just in Time Validation with JSON Schema](https://cdn.slidesharecdn.com/ss_thumbnails/1240-justintimeschemavalidationdinesh-180425155701-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)












