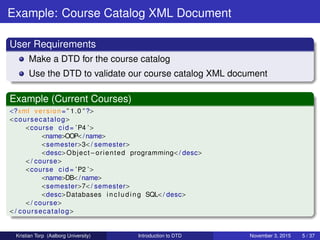
The document is an introduction to Document Type Definitions (DTD) by Kristian Torp and covers essential aspects such as reading, constructing, and validating DTDs for XML documents. It provides detailed examples of DTD declarations, including elements, attributes, and common errors, while highlighting the limitations of DTDs compared to XML schemas. The focus is on understanding the structure and integrity constraints of XML documents from a database perspective.







![Simplest Entity
Example (Element Declaration)
<!ELEMENT name (#PCDATA)>
Example (Allowed Values)
<name>Hello Element</name>
<name/>
<name><![CDATA[ select ∗ from emp where sal > 10]]></name>
Example (Illegal Values)
<name>> </name>
<name>></name>
<name><it>Hello</it></name>
Unknown element <it>, must be defined in DTD
Note
Root, internal-node, and leafs in XML tree representation
Terminal and non-terminal in grammar terminology
Kristian Torp (Aalborg University) Introduction to DTD November 3, 2015 9 / 37](https://image.slidesharecdn.com/dtd-151103192013-lva1-app6892/85/Introduction-to-DTD-9-320.jpg)

















![Summary: Attributes
General Syntax
<!ATTLIST element−name attribute−name type [DefaultValue]>
Often used types
Type Example
CDATA <!ATTLIST course id CDATA>
ID <!ATTLIST course id ID #REQUIRED>
Enumeration <!ATTLIST course id (OOP | DB)>
Defaults
Type Example
#REQUIRED <!ATTLIST course id ID #REQUIRED>
#IMPLIED <!ATTLIST course id CDATA #IMPLIED>
#FIXED <!ATTLIST course id CDATA #FIXED ”1”>
A value <!ATTLIST course id (OOP | DB) ”DB”>
Kristian Torp (Aalborg University) Introduction to DTD November 3, 2015 25 / 37](https://image.slidesharecdn.com/dtd-151103192013-lva1-app6892/85/Introduction-to-DTD-27-320.jpg)








![Using an Internal DTD
Example (DTD for Courses with Flexible Description)
<?xml version=” 1.0 ” standalone=” yes ” ?>
<!DOCTYPE courses [
<!ELEMENT courses ( course )∗>
<!ELEMENT course (name, desc )>
<!ELEMENT name (#PCDATA)>
<!ELEMENT desc ANY>
]>
<courses>
<course>
<name>OOP</name>
<desc>
<name>object−oriented</name>
<desc>programming</ desc>.
</ desc>
</ course>
</ courses>
Note
Benefit: All information in one file
Drawback: DTD is not reused (maintenance nightmare)
Kristian Torp (Aalborg University) Introduction to DTD November 3, 2015 33 / 37](https://image.slidesharecdn.com/dtd-151103192013-lva1-app6892/85/Introduction-to-DTD-36-320.jpg)

















































































