
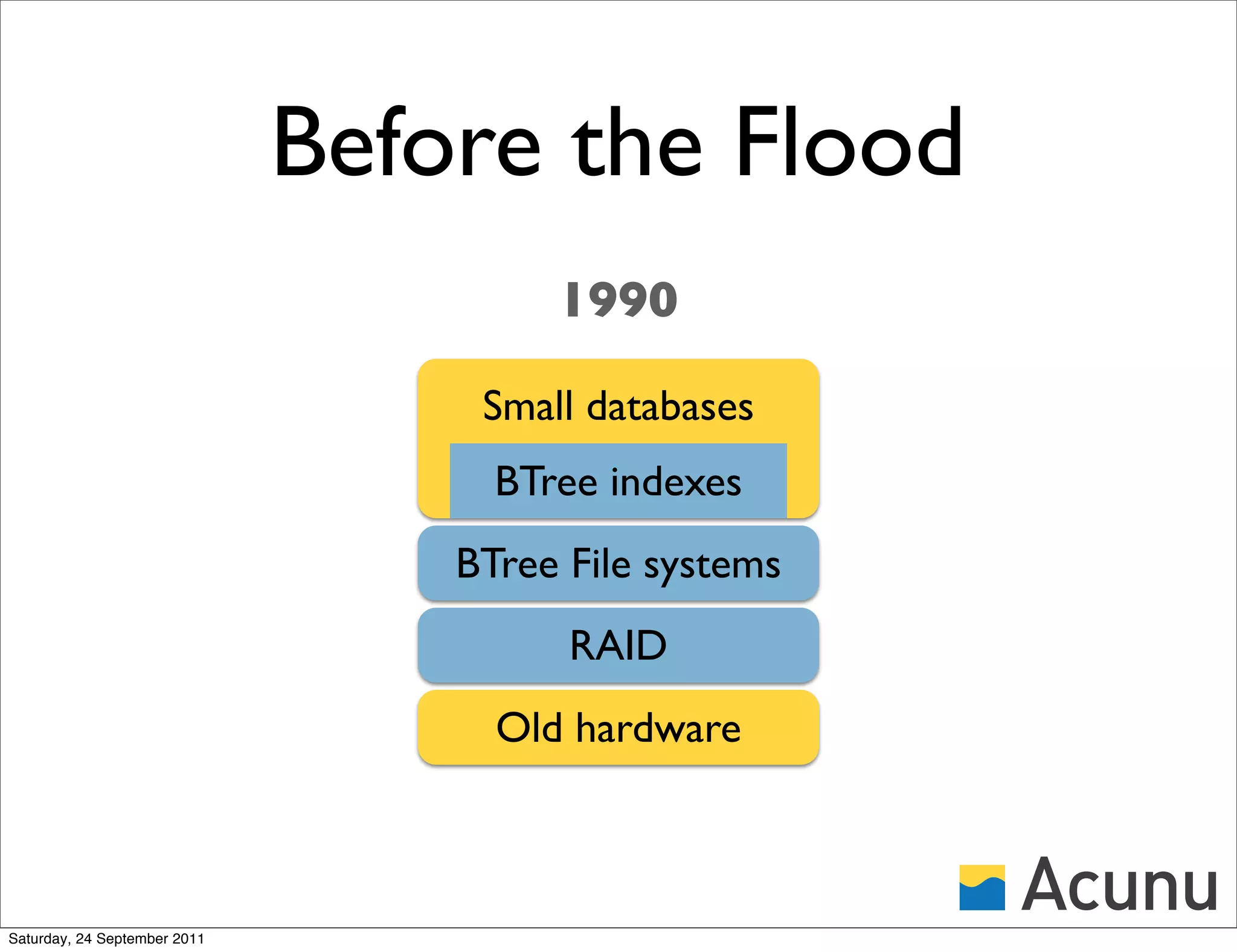
![Outline
• Why Castle?
• A [quick] tour of Castle
• Cassandra on Castle
• An aside into Memcache
• Cross-cluster snapshots and clones
Saturday, 24 September 2011](https://image.slidesharecdn.com/cassoncastlenyc-110924180616-phpapp02/75/Cassandra-on-Castle-2-2048.jpg)
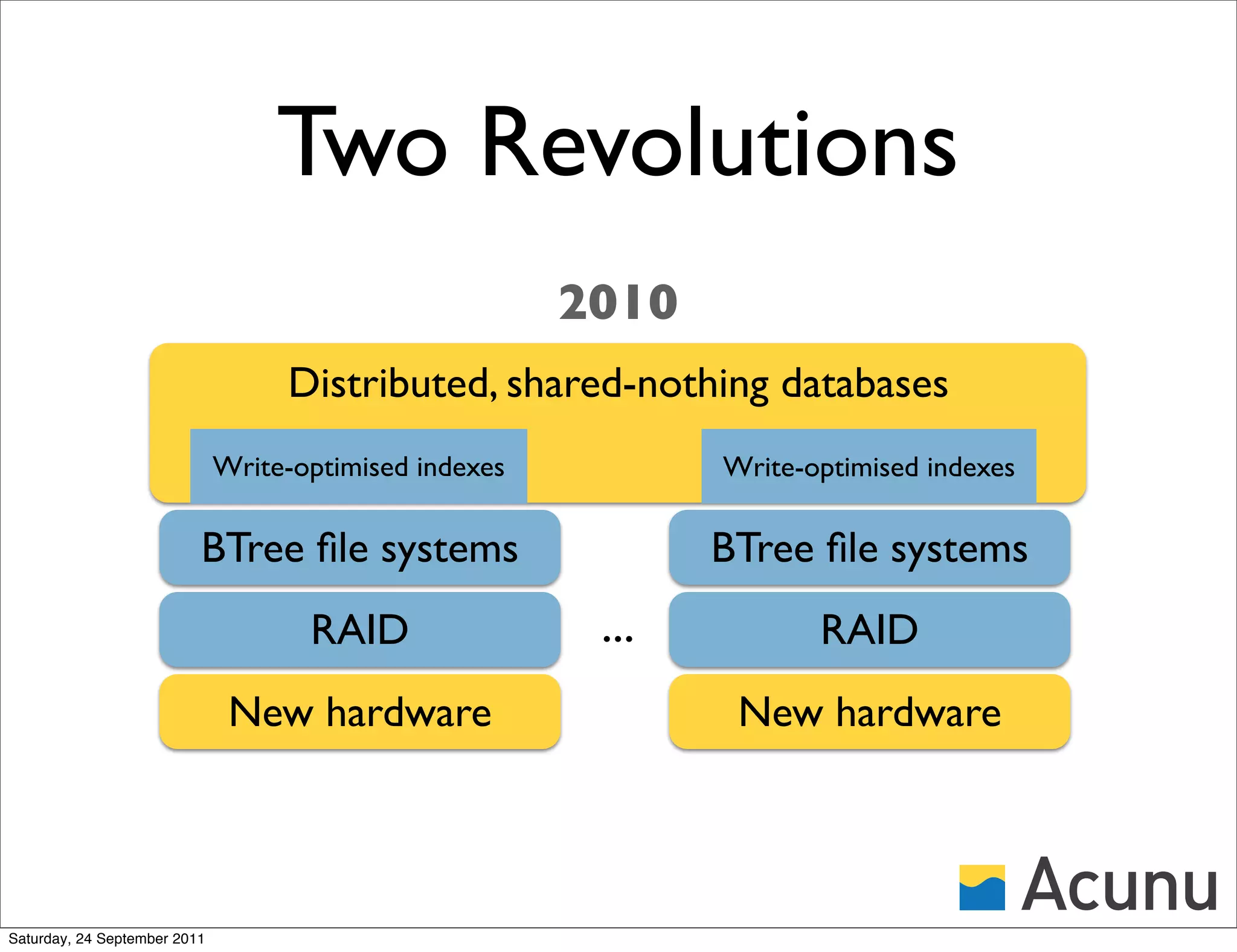








![Copy-on-Write BTree
Idea:
• Apply path-copying [DSST] to
the B-tree
Problems:
• Space blowup: Each update may
rewrite an entire path
• Slow updates: as above
A log file system makes updates sequential, but relies on
random access and garbage collection (achilles heel!)
Saturday, 24 September 2011](https://image.slidesharecdn.com/cassoncastlenyc-110924180616-phpapp02/75/Cassandra-on-Castle-17-2048.jpg)

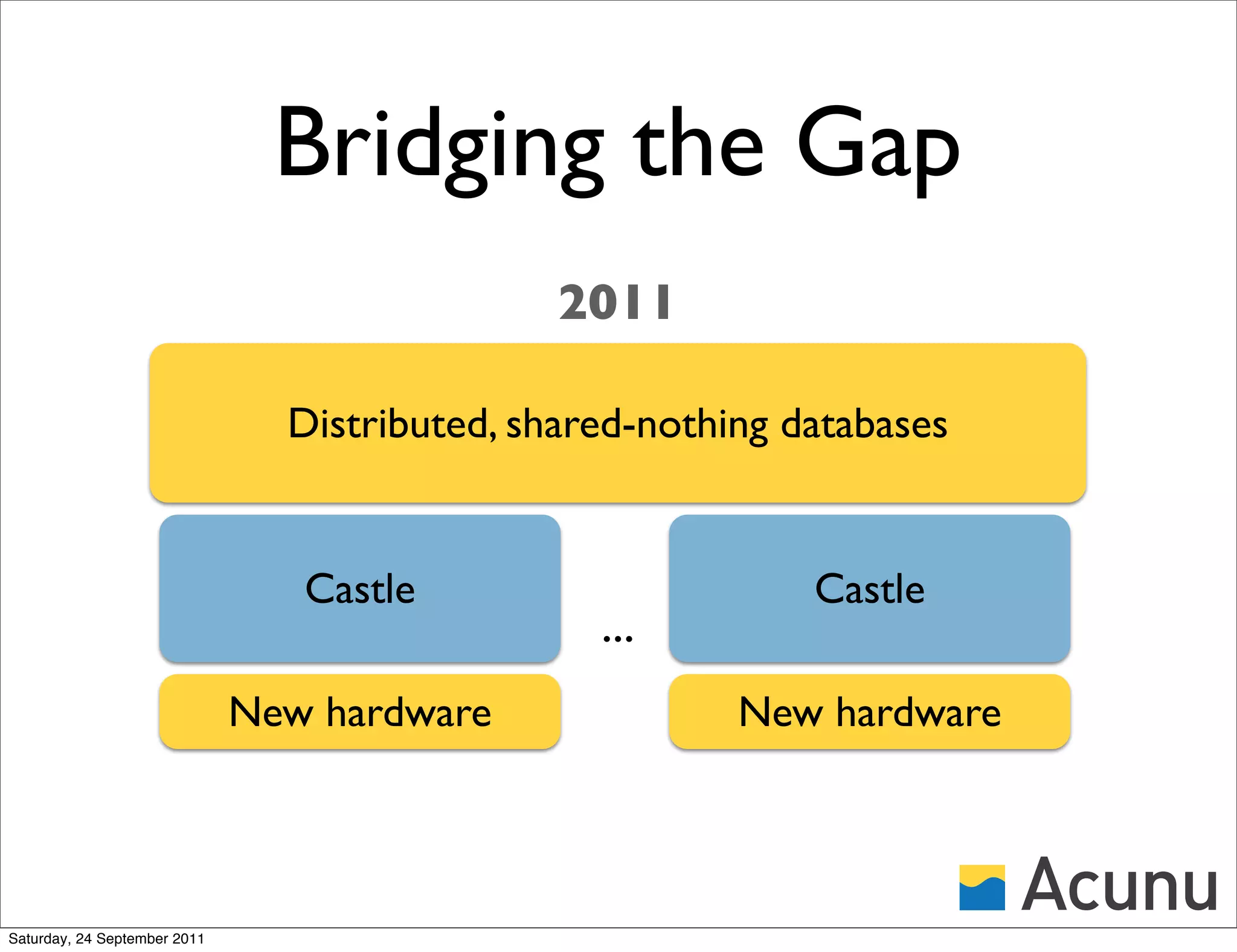
![Stratified B-Trees
• Retires Copy-On-Write B-Trees, the bedrock of
modern storage (Sun ZFS, NetApp WAFL, ...)
• Patent-pending, next-generation data structure
• Theoretically optimal, yet highly practical
Copy-on-write B-tree finally beaten.
Andy Twigg∗ , Andrew Byde∗ , Grzegorz Miło´∗ , Tim Moreton∗ , John Wilkes†∗ and Tom Wilkie∗
∗
s
Acunu, † Google http://goo.gl/INTb1
firstname@acunu.com
Abstract This paper presents some recent results on new con-
structions for B-trees that go beyond copy-on-write, that
A classic versioned data structure in storage and com- we call ‘stratified B-trees’. They solve two open prob-
puter science is the copy-on-write (CoW) B-tree – it un- lems: Firstly. they offer a fully-versioned B-tree with
derlies many of today’s file systems and databases, in- optimal space and the same lookup time as the CoW B-
cluding WAFL, ZFS, Btrfs and more. Unfortunately, it tree. Secondly, they are the first to offer other points on
doesn’t inherit the B-tree’s optimality properties; it has the Pareto optimal query/update tradeoff curve, and in
poor space utilization, cannot offer fast updates, and re- particular, our structures offer fully-versioned updates in
http://goo.gl/gzihe
lies on random IO to scale. Yet, nothing better has o(1) IOs, while using linear space. Experimental results
been developed since. We describe the ‘stratified B-tree’, indicate 100,000s updates/s on a large SATA disk, two
which beats the CoW B-tree in every way. In particu- orders of magnitude faster than a CoW B-tree.
lar, it is the first versioned dictionary to achieve optimal Since stratified B-trees subsume CoW B-trees (and in-
tradeoffs between space, query and update performance. deed all other known versioned external-memory dictio-
Therefore, we believe there is no longer a good reason to naries), we believe there is no longer a good reason to
use CoW B-trees for versioned data stores. use them for versioned data stores. Acunu is develop-
ing a commercial in-kernel implementation of stratified
B-tress, which we hope to release soon.
1 Introduction
Saturday, 24 September 2011
The B-tree was presented in 1972 [1], and it survives](https://image.slidesharecdn.com/cassoncastlenyc-110924180616-phpapp02/75/Cassandra-on-Castle-19-2048.jpg)


![SSD tiering [taster]
• Why? Key to >cache random reads
• v1: SSD for metadata structures
• Redundancy provided by disk
• SSD for selected collection data (CFs)
• 10x write rate on SSDs than regular FSs
Saturday, 24 September 2011](https://image.slidesharecdn.com/cassoncastlenyc-110924180616-phpapp02/75/Cassandra-on-Castle-23-2048.jpg)


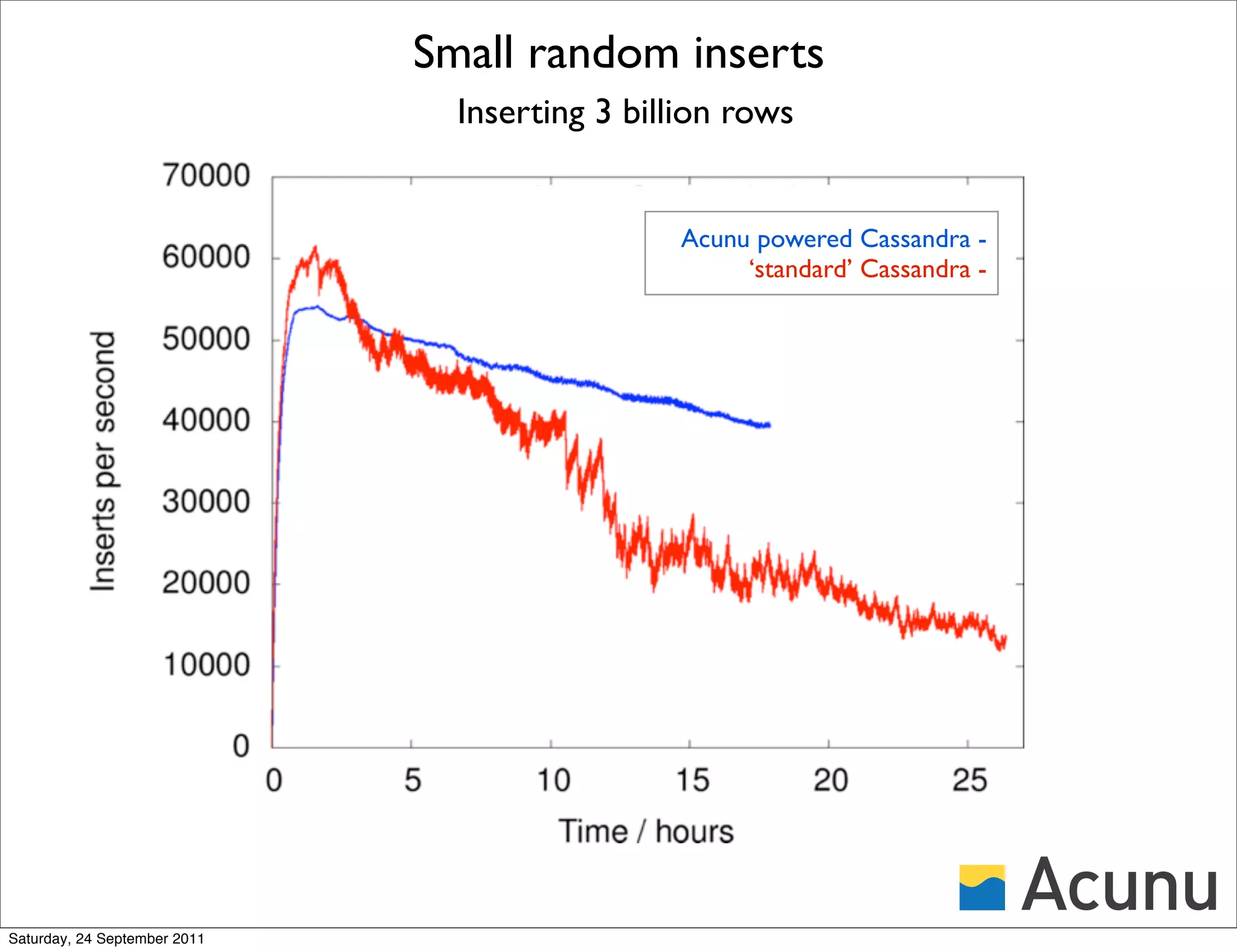

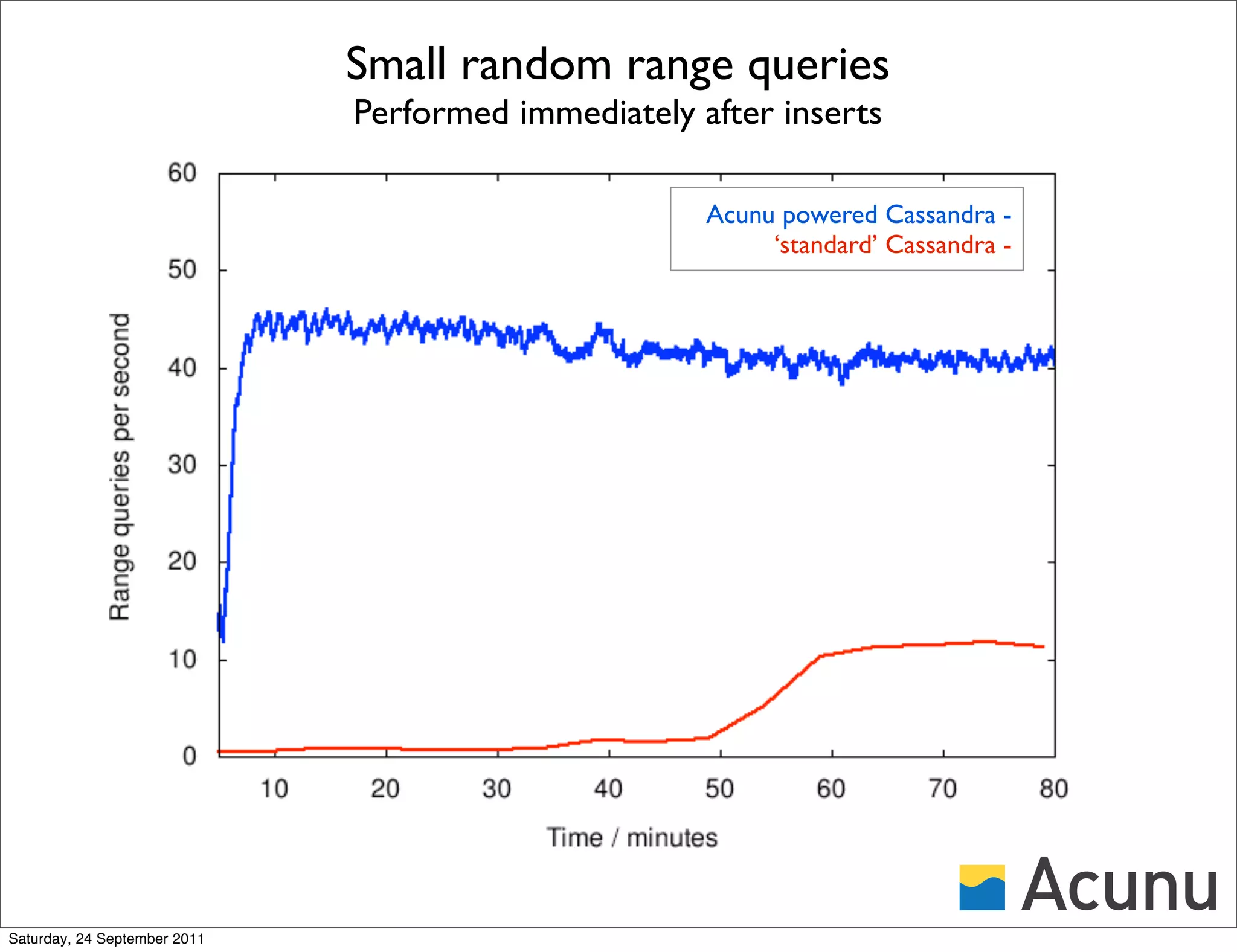
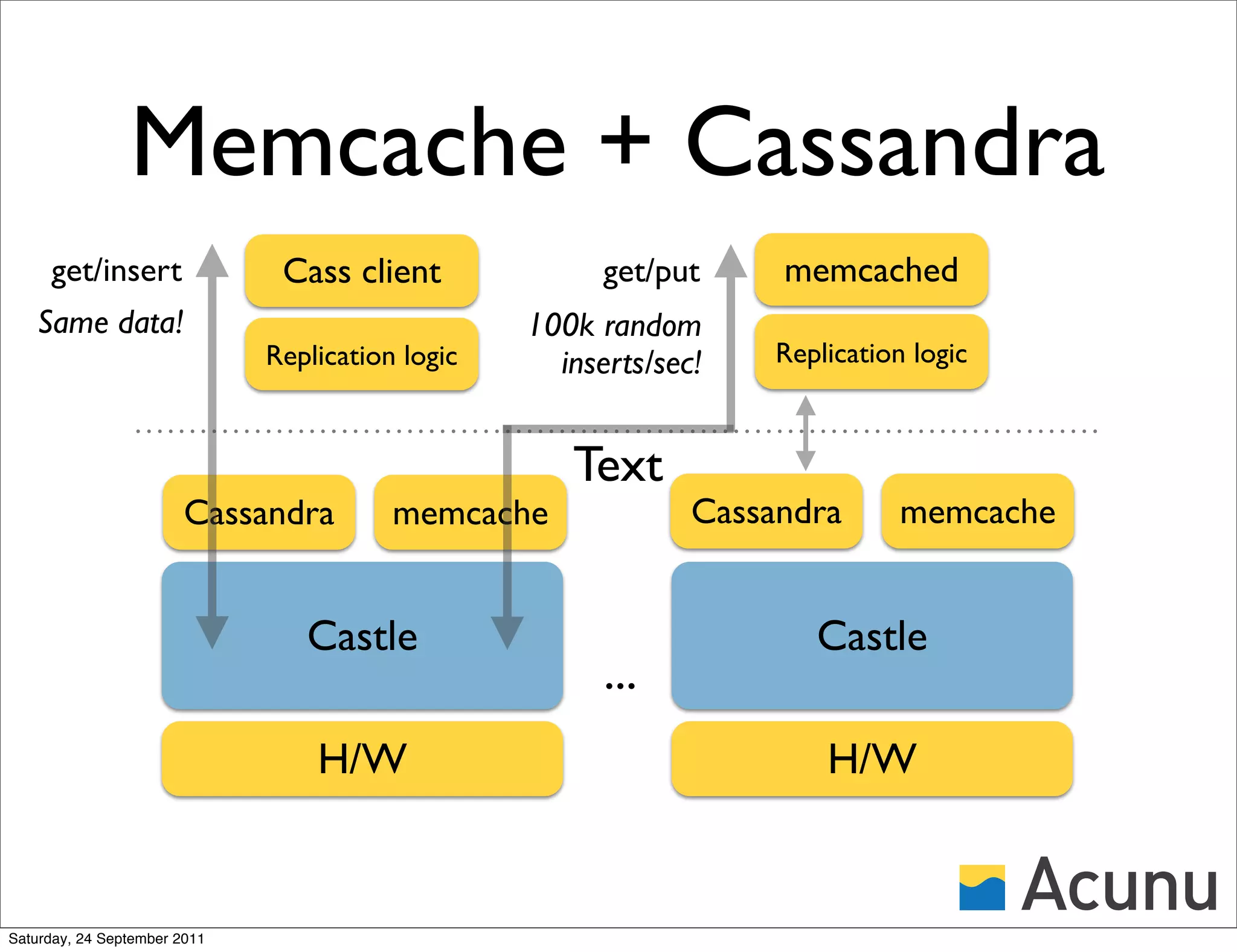





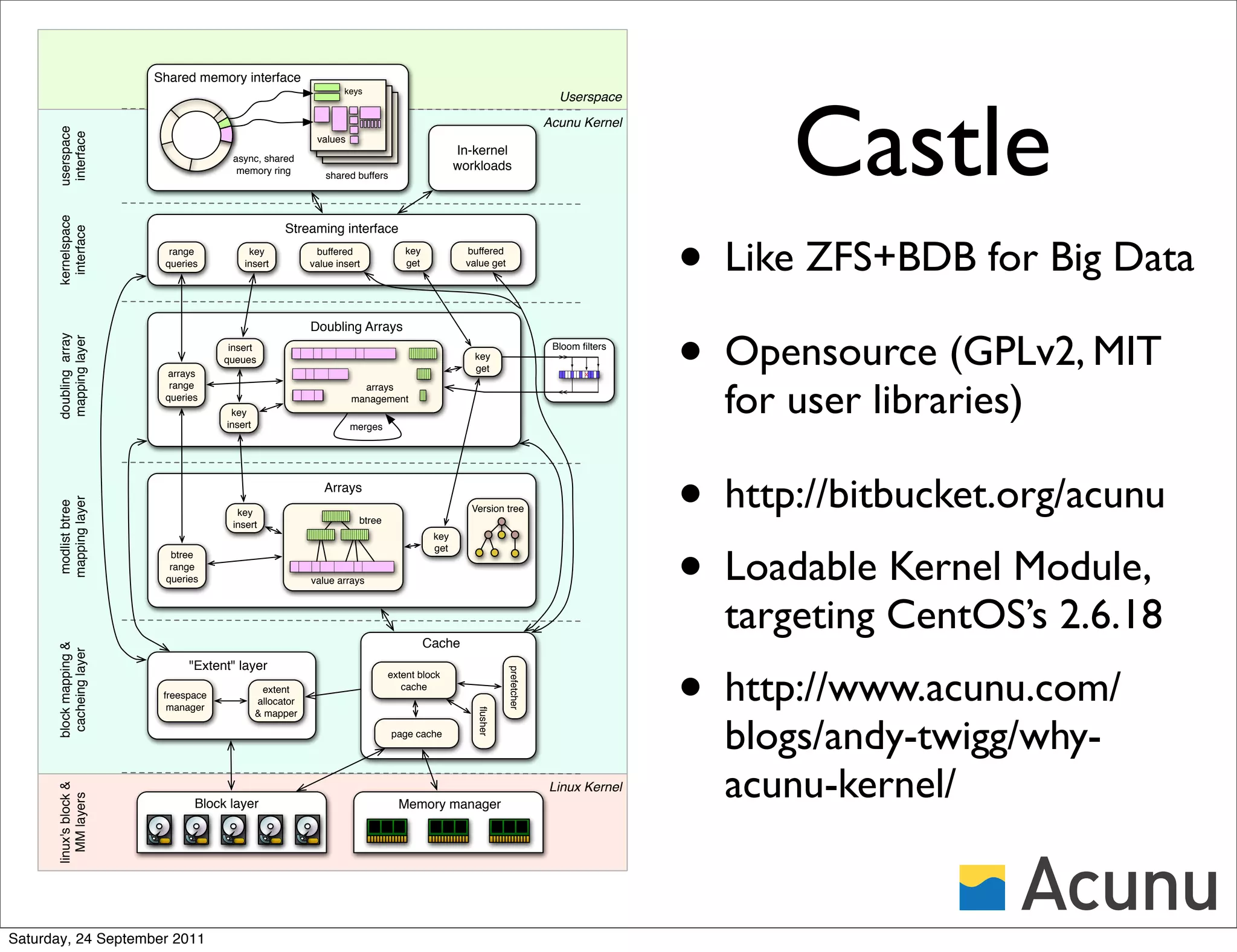
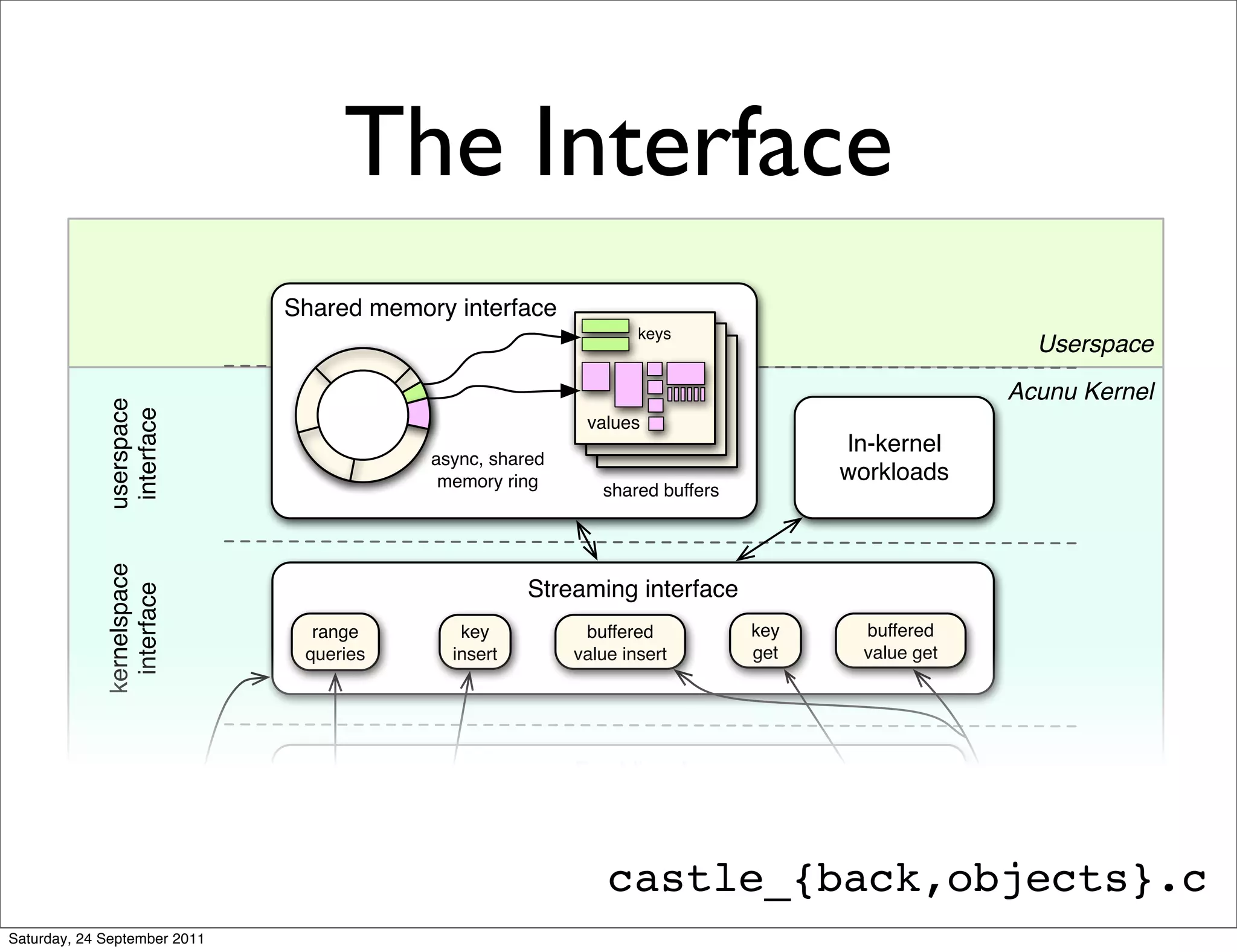
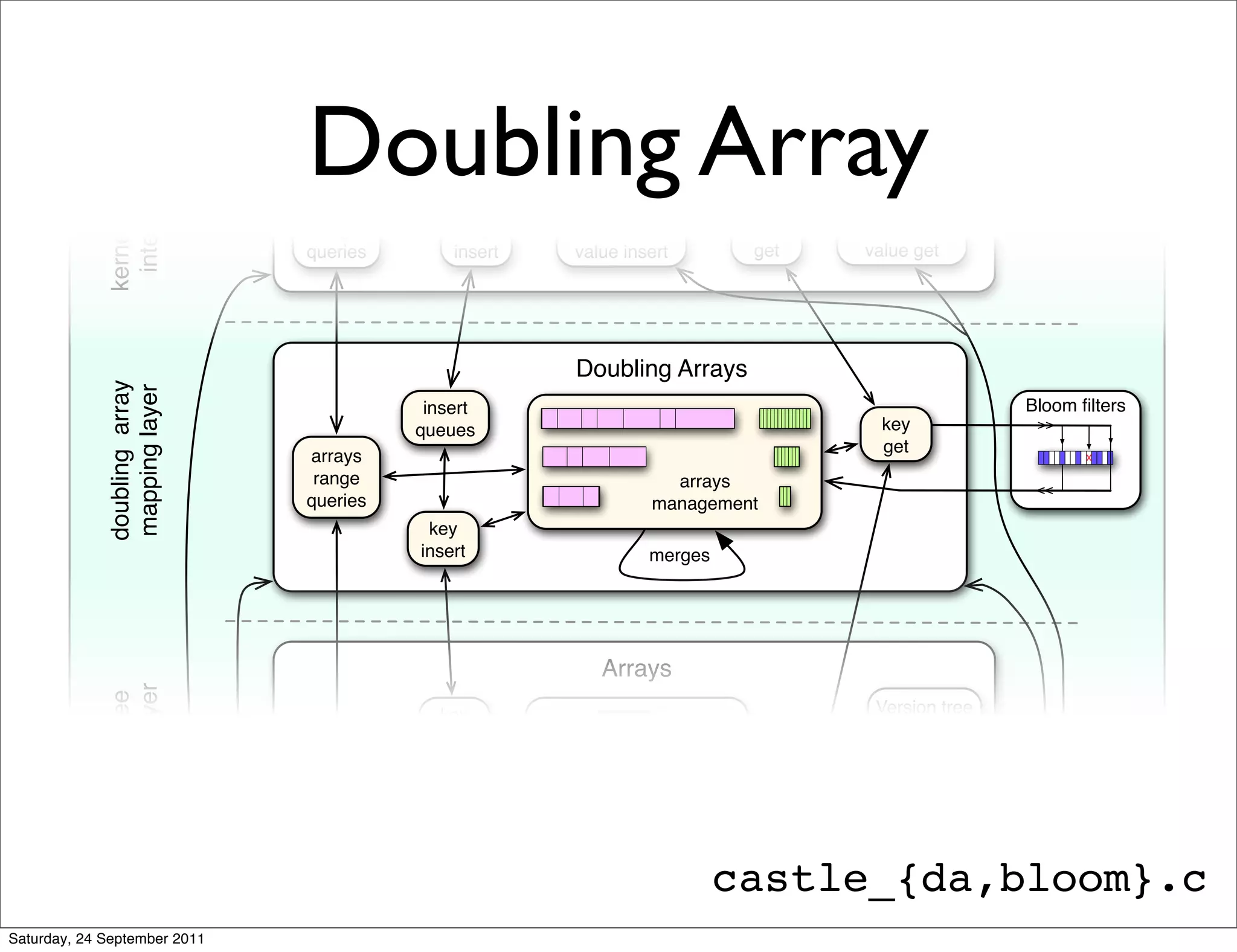
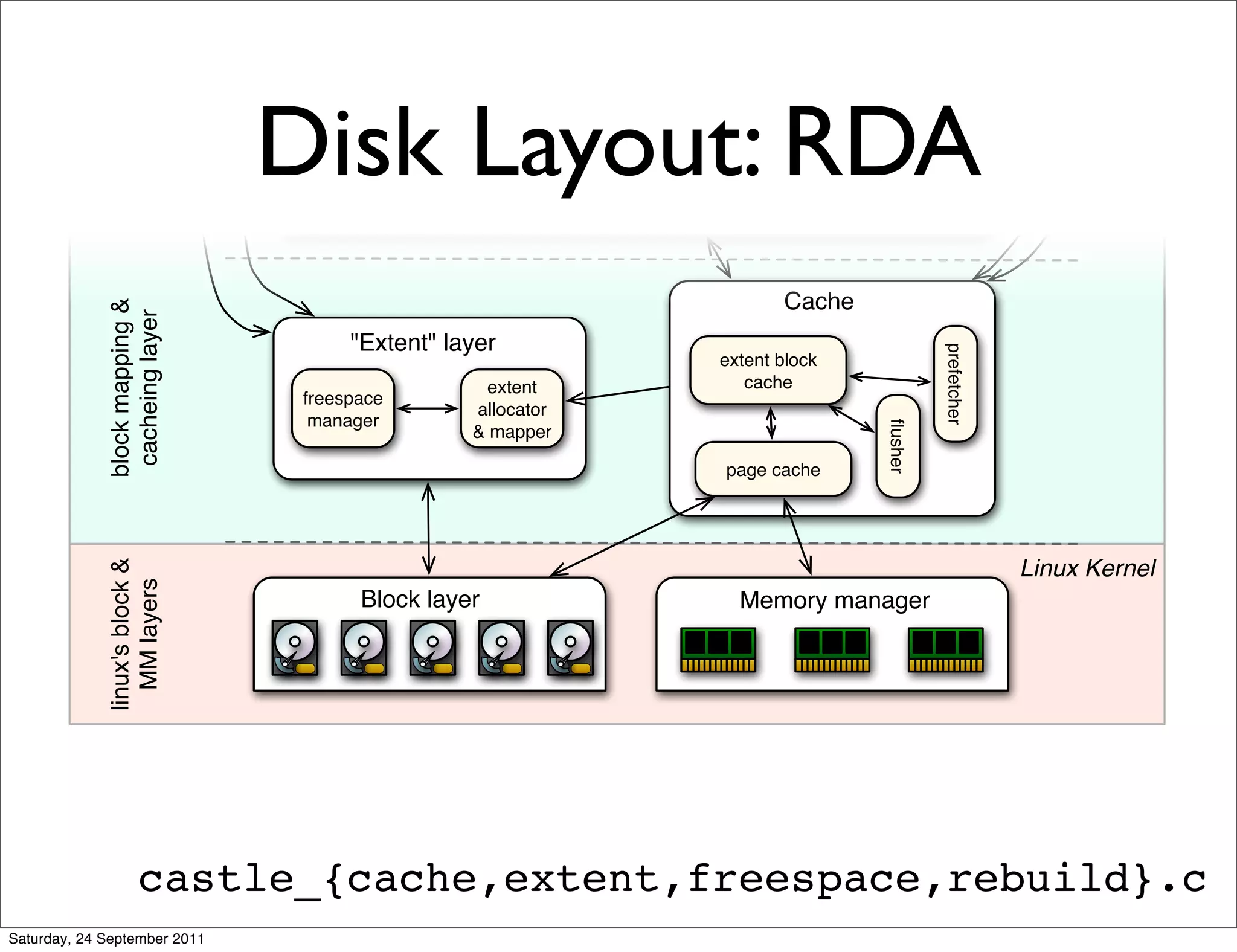
The document discusses the integration of Cassandra with Acunu's Castle, emphasizing advancements in database technology such as the stratified B-tree, which surpasses traditional copy-on-write B-trees in efficiency and performance. It highlights the benefits of a shared memory interface, improved insert rates, and the ability to handle large data sets effectively. Additionally, it outlines the architecture of Acunu and its application in enhancing Cassandra's capabilities for large-scale data management.














![Threads 2x[1]](https://cdn.slidesharecdn.com/ss_thumbnails/threads2x1-111010042244-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

