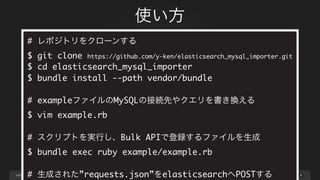
page
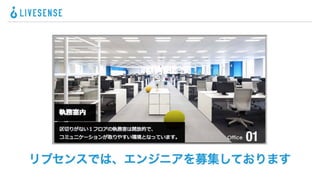
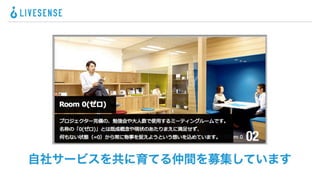
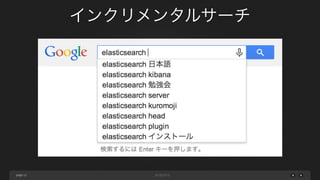
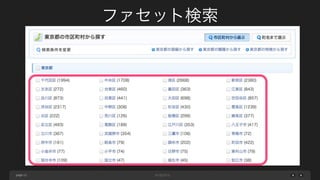
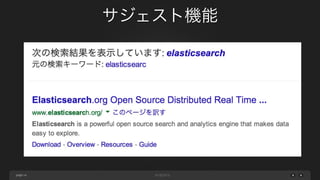
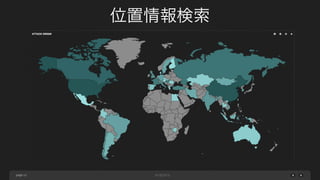
ネスト構造化の仕組み
53
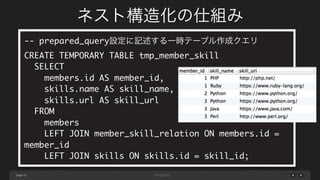
-- prepared_query設定に記述する一時テーブル作成クエリ
CREATE TEMPORARYTABLE tmp_member_skill
SELECT
members.id AS member_id,
skills.name AS skill_name,
skills.url AS skill_url
FROM
members
LEFT JOIN member_skill_relation ON members.id =
member_id
LEFT JOIN skills ON skills.id = skill_id;
58.
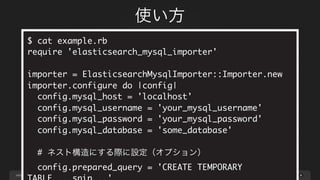
page
ネスト構造化の仕組み
53
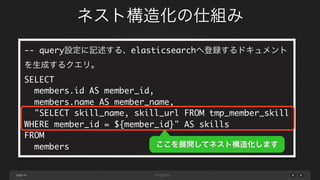
-- prepared_query設定に記述する一時テーブル作成クエリ
CREATE TEMPORARYTABLE tmp_member_skill
SELECT
members.id AS member_id,
skills.name AS skill_name,
skills.url AS skill_url
FROM
members
LEFT JOIN member_skill_relation ON members.id =
member_id
LEFT JOIN skills ON skills.id = skill_id;
































![page
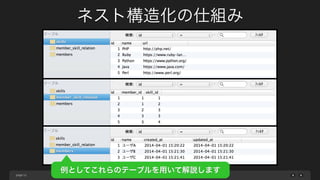
ネスト構造化の仕組み
52
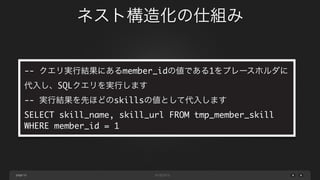
"member_name" : "ユーザA",
"skills" : [
{
"skill_name" : "PHP",
"skill_url" : "http://php.net/"
},
{
"skill_name" : "Ruby",
"skill_url" : "https://www.ruby-lang.org/"
}
]
}
}](https://image.slidesharecdn.com/introduceelasticsearchmysqlimporter-140526033758-phpapp01/85/MySQL-elasticsearch-56-320.jpg)


![page
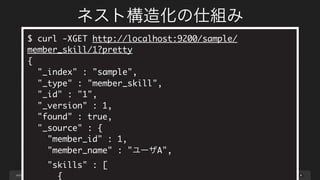
ネスト構造化の仕組み
56
{
"member_id" : 1,
"member_name" : "ユーザA",
"skills" : [
{
"skill_name" : "PHP",
"skill_url" : "http://php.net/"
},
{
"skill_name" : "Ruby",
"skill_url" : "https://www.ruby-lang.org/"
}
]
}](https://image.slidesharecdn.com/introduceelasticsearchmysqlimporter-140526033758-phpapp01/85/MySQL-elasticsearch-62-320.jpg)