Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kentaro Yoshida
5,832 views
トレジャーデータ 導入体験記 リブセンス編
第1回 トレジャーデータ ユーザ会で発表した、 Livesense Inc. での導入事例紹介です。
Engineering
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 12 times
1
/ 52
2
/ 52
3
/ 52
4
/ 52
5
/ 52
6
/ 52
7
/ 52
8
/ 52
9
/ 52
10
/ 52
11
/ 52
12
/ 52
13
/ 52
14
/ 52
15
/ 52
16
/ 52
17
/ 52
18
/ 52
19
/ 52
20
/ 52
21
/ 52
22
/ 52
23
/ 52
24
/ 52
25
/ 52
26
/ 52
27
/ 52
28
/ 52
29
/ 52
30
/ 52
31
/ 52
32
/ 52
33
/ 52
34
/ 52
35
/ 52
36
/ 52
37
/ 52
38
/ 52
39
/ 52
40
/ 52
41
/ 52
42
/ 52
43
/ 52
44
/ 52
45
/ 52
46
/ 52
47
/ 52
48
/ 52
49
/ 52
50
/ 52
51
/ 52
52
/ 52
More Related Content
PPTX
Data Factoryの勘所・大事なところ
by
Tsubasa Yoshino
PDF
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
PPTX
認証/認可が実現する安全で高速分析可能な分析処理基盤
by
Masahiro Kiura
PPTX
Hueによる分析業務の改善事例
by
Masahiro Kiura
PPTX
2014年4月17日 dstnHub発表スライド「dataspiderインターナル:アーキテクチャ編」
by
dstn
PDF
Elastic Stackの紹介とOpenStackでの活用事例(Searchlightなど) - OpenStack最新情報セミナー 2016年5月
by
VirtualTech Japan Inc.
PPTX
Data Factory V2 新機能徹底活用入門
by
Keisuke Fujikawa
Data Factoryの勘所・大事なところ
by
Tsubasa Yoshino
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
認証/認可が実現する安全で高速分析可能な分析処理基盤
by
Masahiro Kiura
Hueによる分析業務の改善事例
by
Masahiro Kiura
2014年4月17日 dstnHub発表スライド「dataspiderインターナル:アーキテクチャ編」
by
dstn
Elastic Stackの紹介とOpenStackでの活用事例(Searchlightなど) - OpenStack最新情報セミナー 2016年5月
by
VirtualTech Japan Inc.
Data Factory V2 新機能徹底活用入門
by
Keisuke Fujikawa
What's hot
PDF
[Azure Deep Dive] Spark と Azure HDInsight によるビッグ データ分析入門 (2017/03/27)
by
Naoki (Neo) SATO
PDF
Graviton2プロセッサの性能特性と適用箇所/Supership株式会社 中野 豊
by
Supership株式会社
PDF
Azure Database for PostgreSQL 入門 (PostgreSQL Conference Japan 2021)
by
Keisuke Takahashi
PPTX
2015年2月26日 dsthHUB 『DataSpiderインターナル プラガブルアーキテクチャで広がる可能性』
by
dstn
PDF
GresCubeで快適PostgreSQLライフ
by
NTT DATA OSS Professional Services
PPTX
Redmineosaka 20 talk_crosspoints
by
Shinji Tamura
PDF
DynamoDBを利用したKPI保存システム
by
gree_tech
PPTX
[db tech showcase Tokyo 2017] B26: レデータの仮想化と自動化がもたらす開発効率アップとは?by 株式会社インサイトテクノ...
by
Insight Technology, Inc.
PDF
GDLC11 oracle-ai
by
Hirokuni Uchida
PDF
Yahoo! JAPANのOracle構成-2017年版
by
Yahoo!デベロッパーネットワーク
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PPTX
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
PDF
DB Tech showcase Tokyo 2015 Works Applications
by
2t3
PDF
グラフデータベースNeo4Jでアセットダウンロードの構成管理と最適化
by
gree_tech
PDF
Innodb Deep Talk #2 でお話したスライド
by
Yasufumi Kinoshita
PDF
Google bigquery導入記
by
Yugo Shimizu
PDF
JavaOne2017参加報告 Microservices topic & approach #jjug
by
Yahoo!デベロッパーネットワーク
PDF
[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...
by
Insight Technology, Inc.
PDF
ヤフーを支えるフラッシュストレージ
by
Yahoo!デベロッパーネットワーク
PPTX
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
[Azure Deep Dive] Spark と Azure HDInsight によるビッグ データ分析入門 (2017/03/27)
by
Naoki (Neo) SATO
Graviton2プロセッサの性能特性と適用箇所/Supership株式会社 中野 豊
by
Supership株式会社
Azure Database for PostgreSQL 入門 (PostgreSQL Conference Japan 2021)
by
Keisuke Takahashi
2015年2月26日 dsthHUB 『DataSpiderインターナル プラガブルアーキテクチャで広がる可能性』
by
dstn
GresCubeで快適PostgreSQLライフ
by
NTT DATA OSS Professional Services
Redmineosaka 20 talk_crosspoints
by
Shinji Tamura
DynamoDBを利用したKPI保存システム
by
gree_tech
[db tech showcase Tokyo 2017] B26: レデータの仮想化と自動化がもたらす開発効率アップとは?by 株式会社インサイトテクノ...
by
Insight Technology, Inc.
GDLC11 oracle-ai
by
Hirokuni Uchida
Yahoo! JAPANのOracle構成-2017年版
by
Yahoo!デベロッパーネットワーク
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
DB Tech showcase Tokyo 2015 Works Applications
by
2t3
グラフデータベースNeo4Jでアセットダウンロードの構成管理と最適化
by
gree_tech
Innodb Deep Talk #2 でお話したスライド
by
Yasufumi Kinoshita
Google bigquery導入記
by
Yugo Shimizu
JavaOne2017参加報告 Microservices topic & approach #jjug
by
Yahoo!デベロッパーネットワーク
[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...
by
Insight Technology, Inc.
ヤフーを支えるフラッシュストレージ
by
Yahoo!デベロッパーネットワーク
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
Similar to トレジャーデータ 導入体験記 リブセンス編
PPTX
ビッグデータ&データマネジメント展
by
Recruit Technologies
PPT
マーケティング向け大規模ログ解析事例紹介
by
Kenji Hara
PDF
スマートニュースの世界展開を支えるログ解析基盤
by
Takumi Sakamoto
PDF
20121205 nosql(okuyama fs)セミナー資料
by
Takahiro Iwase
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
KEY
ソーシャルゲームログ解析基盤のMongoDB活用事例
by
知教 本間
PDF
既存システムへの新技術活用法 ~fluntd/MongoDB~
by
じゅん なかざ
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
Info talk #36
by
Hiroshi Bunya
PPTX
Hadoopカンファレンス2013
by
Recruit Technologies
PPTX
Fluentdの監視サービス (Treasure Agent Monitoring Service) by Treasure Data
by
Kiyoto Tamura
PDF
「NOSQLの基礎知識」講義資料 第20回JDMC定例セミナー(201310)
by
CLOUDIAN KK
PDF
【18-B-2】データ分析で始めるサービス改善最初の一歩
by
Developers Summit
PPT
081108huge_data.ppt
by
Naoya Ito
PPTX
ビッグデータとioDriveの夕べ:ドリコムのデータ分析環境のお話
by
Tokoroten Nakayama
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PDF
StepInNosql
by
abedaisuke1
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PPT
YAPC::Asia 2008 Tokyo - Pathtraq - building a computation-centric web service
by
Kazuho Oku
PDF
fluentd を利用した大規模ウェブサービスのロギング
by
Yuichi Tateno
ビッグデータ&データマネジメント展
by
Recruit Technologies
マーケティング向け大規模ログ解析事例紹介
by
Kenji Hara
スマートニュースの世界展開を支えるログ解析基盤
by
Takumi Sakamoto
20121205 nosql(okuyama fs)セミナー資料
by
Takahiro Iwase
Facebookのリアルタイム Big Data 処理
by
maruyama097
ソーシャルゲームログ解析基盤のMongoDB活用事例
by
知教 本間
既存システムへの新技術活用法 ~fluntd/MongoDB~
by
じゅん なかざ
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
Info talk #36
by
Hiroshi Bunya
Hadoopカンファレンス2013
by
Recruit Technologies
Fluentdの監視サービス (Treasure Agent Monitoring Service) by Treasure Data
by
Kiyoto Tamura
「NOSQLの基礎知識」講義資料 第20回JDMC定例セミナー(201310)
by
CLOUDIAN KK
【18-B-2】データ分析で始めるサービス改善最初の一歩
by
Developers Summit
081108huge_data.ppt
by
Naoya Ito
ビッグデータとioDriveの夕べ:ドリコムのデータ分析環境のお話
by
Tokoroten Nakayama
Osc2012 spring HBase Report
by
Seiichiro Ishida
StepInNosql
by
abedaisuke1
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
YAPC::Asia 2008 Tokyo - Pathtraq - building a computation-centric web service
by
Kazuho Oku
fluentd を利用した大規模ウェブサービスのロギング
by
Yuichi Tateno
More from Kentaro Yoshida
PDF
Improve data engineering work with Digdag and Presto UDF
by
Kentaro Yoshida
PDF
TREASUREDATAのエコシステムで作るロバストなETLデータ処理基盤の作り方
by
Kentaro Yoshida
PDF
Fluentd, Digdag, Embulkを用いたデータ分析基盤の始め方
by
Kentaro Yoshida
PDF
Hivemallで始める不動産価格推定サービス
by
Kentaro Yoshida
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PDF
MySQLと組み合わせて始める全文検索プロダクト"elasticsearch"
by
Kentaro Yoshida
PDF
MySQLユーザ視点での小さく始めるElasticsearch
by
Kentaro Yoshida
PDF
Fluentdベースのミドルウェア"Yamabiko"でMySQLのテーブルをElasticsearchへレプリケートする話 #fluentdcasual
by
Kentaro Yoshida
PDF
MySQL 5.6への完全移行を実現したTritonnからMroongaへの移行体験記
by
Kentaro Yoshida
PDF
ElasticSearch+Kibanaでログデータの検索と視覚化を実現するテクニックと運用ノウハウ
by
Kentaro Yoshida
PDF
Tritonn (MySQL5.0.87+Senna)からの mroonga (MySQL5.6) 移行体験記
by
Kentaro Yoshida
PDF
MySQL Casual Talks Vol.4 「MySQL-5.6で始める全文検索 〜InnoDB FTS編〜」
by
Kentaro Yoshida
Improve data engineering work with Digdag and Presto UDF
by
Kentaro Yoshida
TREASUREDATAのエコシステムで作るロバストなETLデータ処理基盤の作り方
by
Kentaro Yoshida
Fluentd, Digdag, Embulkを用いたデータ分析基盤の始め方
by
Kentaro Yoshida
Hivemallで始める不動産価格推定サービス
by
Kentaro Yoshida
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
MySQLと組み合わせて始める全文検索プロダクト"elasticsearch"
by
Kentaro Yoshida
MySQLユーザ視点での小さく始めるElasticsearch
by
Kentaro Yoshida
Fluentdベースのミドルウェア"Yamabiko"でMySQLのテーブルをElasticsearchへレプリケートする話 #fluentdcasual
by
Kentaro Yoshida
MySQL 5.6への完全移行を実現したTritonnからMroongaへの移行体験記
by
Kentaro Yoshida
ElasticSearch+Kibanaでログデータの検索と視覚化を実現するテクニックと運用ノウハウ
by
Kentaro Yoshida
Tritonn (MySQL5.0.87+Senna)からの mroonga (MySQL5.6) 移行体験記
by
Kentaro Yoshida
MySQL Casual Talks Vol.4 「MySQL-5.6で始める全文検索 〜InnoDB FTS編〜」
by
Kentaro Yoshida
トレジャーデータ 導入体験記 リブセンス編
2.
page 1. 自己紹介 2. 事業紹介 3.
導入当時 4. 活用方法 5. 導入前後 6. 安定運用化 7. 今後の期待 8. まとめ 本日の流れ 2
3.
page 1. 自己紹介 3
5.
page Fluentd歴 < TreasureData歴 5
6.
page 執筆書籍 6 サーバ/インフラエンジニア養成読本 ログ収集∼可視化編 [現場主導のデータ分析環 境を構築!] (Software
Design plus) 出版社/メーカー: 技術評論社 定価: 本体1,980円+税
7.
page 7
8.
page 拙作の公開中Fluentdプラグイン 8 rewrite-tag-filter geoip mysql-replicator munin twitter anonymizer mysql-query gamobile watch-process twilio sentry feedly
9.
page 2. 事業紹介 9
10.
あたりまえを、発明しよう。
17.
可視化された未来型 不動産プラットフォームサービス
18.
page 3. 導入当時 18
19.
page 導入当時 19 MySQL5.0系を利用。その構成にムリが生じ始めていた トランザクションテーブルとログテーブルの混在 分析クエリによるスロークエリの温床 本番のスキーマ変更のレビュー工数の手間 データのサイジング計画を建てる手間
20.
page 導入当時 20 MySQLへの高コストなINSERTクエリによるページ表示遅延 INSERTコストを下げる為に、可能な限りログを定期的に 消し込む必要がある。消し込みバッチが増殖。 消し込める範囲も限られるため、INSERTクエリと消し込 みクエリにより、レプリケーション遅延は常態化する 例え非同期化してもレプリケーション遅延は直らない
21.
page これじゃダメだ! 21
22.
page 事業加速のスピードをさらに上げたい 22
23.
page Hadoop基盤が必要であることは明白 しかし少ない人員で誰が運用するのか 23
24.
page かの有名な太田さんや古橋さんが Bigdata as a
Serviceを “TreasureData”として サービスインする を耳にする 24
25.
page 当時のトレジャーデータのメンバー 25 引用元 http://itpro.nikkeibp.co.jp/article/NEWS/20120928/426103/
26.
page 2012年5月 太田さんにメール 数営業日後、全サーバへの導入完了 26
27.
page 1つの社内スタートアップメディアを 先行事例として試験導入 27
28.
page 4. 活用方法 28
29.
page 活用方法 29 ユーザの行動ログの収集と分析 集計結果のGoogleSpreadSheet書き出しが圧倒的に多い さまざまな履歴データの保管と集計 A/Bテスト 不達メールアドレスのクリーニング 名寄せ処理、クロールデータ etc… 機械学習 (Hivemall)
30.
page 活用方法 30 行動ログの分析(A/Bテストや不正ユーザ検出) KPIダッシュボードへの書き出し(GoogleSpreadSheetベース) レガシーブラウザのコンバージョン数のモニタリング デグレが発生し取りこぼしが発生しても早期に検出可能 ロボットのクロール状況の追跡 ロボットからのクロールが意図通りかモニタリング レスポンスタイムや500エラーの発生率の追跡 JavaScript SDKを用いたWebビーコン型アクセス解析
31.
page A/Bテストなどの裏側ではTreasureDataが大活躍 31 活用方法
32.
page 単にABテストをすると必要な 計測回数を満たしていないこともある 32
33.
page あるメディアでのA/Bテスト事例 33 引用元:【テストツール不要】明日から試せる転職会議式ABテストのはじめ方 http://qiita.com/kekekenta/items/8b1f9d2a17c4c6a6b638
34.
page 途中でクリック率が反転する例 34 引用元:【テストツール不要】明日から試せる転職会議式ABテストのはじめ方 http://qiita.com/kekekenta/items/8b1f9d2a17c4c6a6b638
35.
page A/Bテストの計測量が足りているかは 信頼区間を計算するべきである 35
36.
page 信頼区間の計算手法など、詳しくは 「転職会議 2倍」で検索! 36
37.
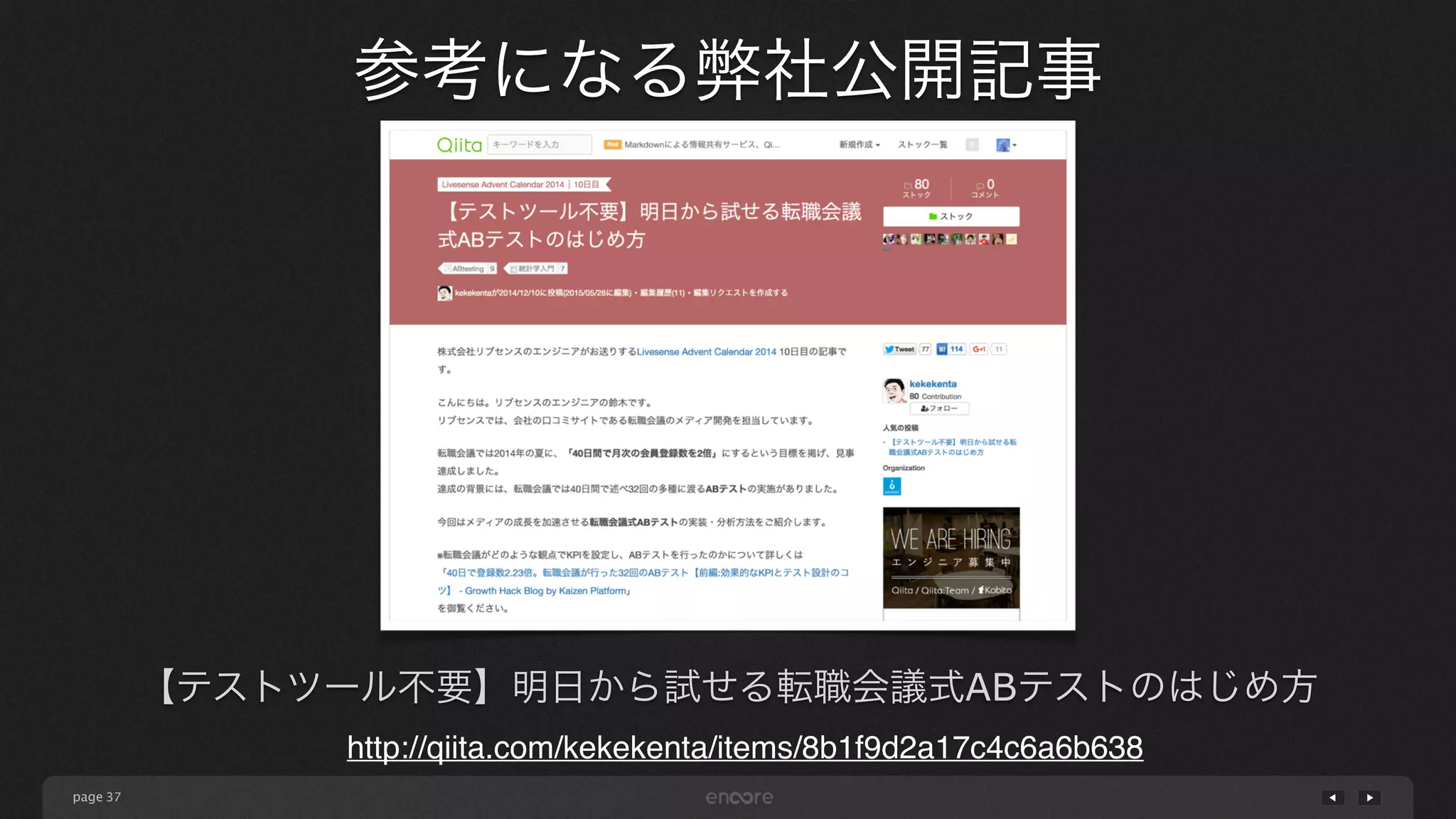
page 参考になる弊社公開記事 37 【テストツール不要】明日から試せる転職会議式ABテストのはじめ方 http://qiita.com/kekekenta/items/8b1f9d2a17c4c6a6b638
38.
page 参考になる弊社公開スライド 38 登録数2倍にしてと言われた時の正しい対処法 http://www.slideshare.net/KurosawaChihiro/2-42758053
39.
page 39 「コンバージョン数を2倍にしてくれ」と言われた時の対処法 http://www.slideshare.net/tsuyoshika/2-52482724 参考になる弊社公開スライド
40.
page 5. 導入前後 40
41.
page 導入前後 41 スキーマやデータサイズの呪縛から解放された クエリの結果をURLとして参照できる GoogleSpreadSheet書き出しでリアルタイム更新される ダッシュボードが手軽に作れることに感激する Hadoopの運用が任せられるため事業に集中出来る サポートチャットの対応が素晴らしいため心強い 新規事業立ち上げに伴う導入支援にも応えていただけた
42.
page サポートチャット利用状況 42
43.
page いつもありがとうございます! 43
44.
page 6. 安定運用化 44
45.
page 安定運用化 45 td-agentの監視はもちろん必要(Mackerl + PagerDutyなど) td-agentのバッファサイズなどのチューニングも必要 社内向けにクエリのクックブックを提供 社内向けにWebコンソールの運用ガイドラインを定める Teamユーザの発行方針 Saved
Queiesの命名ルール 一部のノウハウはQiitaなどで公開中
48.
page 7. 今後の期待 48
49.
page 今後の期待 49 Pythonを用いた独自UDF対応 ストリーミングデータ処理の対応 環境変数への対応(Hivemallの乱数seedを固定したい) Hivemallを用いた予測結果をDynamoDBへ書き出したい 億単位の全組み合わせ予測結果を事前に計算しておきたい コンソールのスピードや使い勝手の改善 2016 Q1のNew Web
Consoleが楽しみです
50.
page 8. まとめ 50
51.
page まとめ 51 TreasureDataを契約して良かった 導入によるメリットは計り知れない 今ではHiveよりもPrestoをメインに利用している 共に成長すること3年、今後の動向が楽しみです
52.
page Thanks! 52 ご清聴ありがとうございました。
Download






![page
執筆書籍
6
サーバ/インフラエンジニア養成読本
ログ収集∼可視化編 [現場主導のデータ分析環
境を構築!] (Software Design plus)
出版社/メーカー: 技術評論社
定価: 本体1,980円+税](https://image.slidesharecdn.com/treasuredatausermeetupjapan-151110085108-lva1-app6892/75/slide-6-2048.jpg)





















































![[Azure Deep Dive] Spark と Azure HDInsight によるビッグ データ分析入門 (2017/03/27)](https://cdn.slidesharecdn.com/ss_thumbnails/20170327azuredeepdivehdinsightspark-170327093409-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db tech showcase Tokyo 2017] B26: レデータの仮想化と自動化がもたらす開発効率アップとは?by 株式会社インサイトテクノ...](https://cdn.slidesharecdn.com/ss_thumbnails/b26-170912020934-thumbnail.jpg?width=640&height=640&fit=bounds)









![[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...](https://cdn.slidesharecdn.com/ss_thumbnails/d35-170912024713-thumbnail.jpg?width=640&height=640&fit=bounds)

































