Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
都元ダイスケ Miyamoto
1,806 views
20121215 DevLOVE2012 Mahout on AWS
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 14 times
1
/ 36
2
/ 36
3
/ 36
4
/ 36
5
/ 36
6
/ 36
7
/ 36
8
/ 36
9
/ 36
10
/ 36
11
/ 36
12
/ 36
13
/ 36
14
/ 36
15
/ 36
16
/ 36
17
/ 36
18
/ 36
19
/ 36
20
/ 36
21
/ 36
22
/ 36
23
/ 36
24
/ 36
25
/ 36
26
/ 36
27
/ 36
28
/ 36
29
/ 36
30
/ 36
31
/ 36
32
/ 36
33
/ 36
34
/ 36
35
/ 36
36
/ 36
More Related Content
PDF
性能測定道 実践編
by
Yuto Hayamizu
PDF
SmartNews TechNight Vol5 : SmartNews AdServer 解体新書 / ポストモーテム
by
SmartNews, Inc.
PDF
ElasticSearch勉強会 第6回
by
Naoyuki Yamada
PDF
Kof2016 postgresql-9.6
by
Toshi Harada
PDF
DeltaCubeにおけるユニークユーザー集計高速化(実践編)
by
BrainPad Inc.
PPTX
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
PPTX
My sqlで2億件のシリアルデータと格闘した話
by
saiken3110
PPTX
Azure SQLデータベース最新動向&TIPS
by
nishioka1
性能測定道 実践編
by
Yuto Hayamizu
SmartNews TechNight Vol5 : SmartNews AdServer 解体新書 / ポストモーテム
by
SmartNews, Inc.
ElasticSearch勉強会 第6回
by
Naoyuki Yamada
Kof2016 postgresql-9.6
by
Toshi Harada
DeltaCubeにおけるユニークユーザー集計高速化(実践編)
by
BrainPad Inc.
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
My sqlで2億件のシリアルデータと格闘した話
by
saiken3110
Azure SQLデータベース最新動向&TIPS
by
nishioka1
What's hot
PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
PPTX
Spark Structured Streaming with Kafka
by
Sotaro Kimura
PDF
現場的!AWSとオンプレの違い(赤べこバージョン)
by
真吾 吉田
PPTX
類義語検索と類義語ハイライト
by
Shinichiro Abe
PPTX
Apache Solr 入門
by
順平 西本
PDF
はてなブックマークに基づく関連記事レコメンドエンジンの開発
by
Shunsuke Kozawa
PPTX
Elasticsearchインデクシングのパフォーマンスを測ってみた
by
Ryoji Kurosawa
PPTX
Azure Search 言語処理関連機能 〜 アナライザー、検索クエリー、辞書、& ランキング, etc
by
Yoichi Kawasaki
PDF
ソーシャルゲームにおけるAWS/MongoDB利用事例
by
Masakazu Matsushita
PDF
Amazon RDS (MySQL) 入門
by
Manabu Shinsaka
PDF
Terraforming
by
Tomoaki Yahagi
PPTX
Amazon RDS for PostgreSQL ( JPUG 2014夏セミナー) #jpug
by
Yasuhiro Matsuo
PPTX
solr勉強会資料
by
Atsushi Takayasu
PDF
Aws×phpでの 高信頼かつハイパフォーマンスなシステム
by
KoteiIto
PDF
[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法
by
de:code 2017
PDF
Rds徹底入門
by
Junpei Nakada
PDF
Aurora
by
maruyama097
PPTX
Spark Structured StreamingでKafkaクラスタのデータをお手軽活用
by
Sotaro Kimura
PDF
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
PDF
ISUCON夏期講習2015_2 実践編
by
SATOSHI TAGOMORI
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
Spark Structured Streaming with Kafka
by
Sotaro Kimura
現場的!AWSとオンプレの違い(赤べこバージョン)
by
真吾 吉田
類義語検索と類義語ハイライト
by
Shinichiro Abe
Apache Solr 入門
by
順平 西本
はてなブックマークに基づく関連記事レコメンドエンジンの開発
by
Shunsuke Kozawa
Elasticsearchインデクシングのパフォーマンスを測ってみた
by
Ryoji Kurosawa
Azure Search 言語処理関連機能 〜 アナライザー、検索クエリー、辞書、& ランキング, etc
by
Yoichi Kawasaki
ソーシャルゲームにおけるAWS/MongoDB利用事例
by
Masakazu Matsushita
Amazon RDS (MySQL) 入門
by
Manabu Shinsaka
Terraforming
by
Tomoaki Yahagi
Amazon RDS for PostgreSQL ( JPUG 2014夏セミナー) #jpug
by
Yasuhiro Matsuo
solr勉強会資料
by
Atsushi Takayasu
Aws×phpでの 高信頼かつハイパフォーマンスなシステム
by
KoteiIto
[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法
by
de:code 2017
Rds徹底入門
by
Junpei Nakada
Aurora
by
maruyama097
Spark Structured StreamingでKafkaクラスタのデータをお手軽活用
by
Sotaro Kimura
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
ISUCON夏期講習2015_2 実践編
by
SATOSHI TAGOMORI
Similar to 20121215 DevLOVE2012 Mahout on AWS
PDF
Touch the mahout
by
Makoto Uehara
PDF
JAWSDAYS 2014 ACEに聞け! EMR編
by
陽平 山口
KEY
Apache Mahout お手軽レコメンド
by
Yoshiyuki MIYAGI
PDF
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
PDF
協調フィルタリング with Mahout
by
Katsuhiro Takata
PDF
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PDF
Spark MLlibではじめるスケーラブルな機械学習
by
NTT DATA OSS Professional Services
PDF
Introduction to fuzzy kmeans on mahout
by
takaya imai
PDF
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
PPTX
Apache Spark チュートリアル
by
K Yamaguchi
PDF
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
PDF
Run Spark on EMRってどんな仕組みになってるの?
by
Satoshi Noto
PDF
SparkやBigQueryなどを用いた モバイルゲーム分析環境
by
yuichi_komatsu
PPT
machine learning & apache mahout
by
あしたのオープンソース研究所
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
PDF
Amazonでのレコメンド生成における深層学習とAWS利用について
by
Amazon Web Services Japan
PPTX
ATN No.1 Hadoop vs Amazon EMR
by
AdvancedTechNight
PDF
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
PDF
Log解析の超入門
by
菊池 佑太
Touch the mahout
by
Makoto Uehara
JAWSDAYS 2014 ACEに聞け! EMR編
by
陽平 山口
Apache Mahout お手軽レコメンド
by
Yoshiyuki MIYAGI
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
協調フィルタリング with Mahout
by
Katsuhiro Takata
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
Spark MLlibではじめるスケーラブルな機械学習
by
NTT DATA OSS Professional Services
Introduction to fuzzy kmeans on mahout
by
takaya imai
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
Apache Spark チュートリアル
by
K Yamaguchi
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
Run Spark on EMRってどんな仕組みになってるの?
by
Satoshi Noto
SparkやBigQueryなどを用いた モバイルゲーム分析環境
by
yuichi_komatsu
machine learning & apache mahout
by
あしたのオープンソース研究所
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
Amazonでのレコメンド生成における深層学習とAWS利用について
by
Amazon Web Services Japan
ATN No.1 Hadoop vs Amazon EMR
by
AdvancedTechNight
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
Log解析の超入門
by
菊池 佑太
More from 都元ダイスケ Miyamoto
PDF
認証の標準的な方法は分かった。では認可はどう管理するんだい? #cmdevio
by
都元ダイスケ Miyamoto
PDF
アプリケーション動作ログ、 ERRORで出すか? WARNで出すか? #cmdevio2019
by
都元ダイスケ Miyamoto
PDF
マイクロサービス時代の認証と認可 - AWS Dev Day Tokyo 2018 #AWSDevDay
by
都元ダイスケ Miyamoto
PDF
クラスメソッドにおける Web API エンジニアリングの基本的な考え方と標準定義 - Developers.IO 2018 (2018-10-05)
by
都元ダイスケ Miyamoto
PDF
AWSクラウドデータストレージ総論
by
都元ダイスケ Miyamoto
PDF
20170312 F.K様向け ライフパートナーM.M様のご提案
by
都元ダイスケ Miyamoto
PDF
Spring Day 2016 - Web API アクセス制御の最適解
by
都元ダイスケ Miyamoto
PDF
マイクロWebアプリケーション - Developers.IO 2016
by
都元ダイスケ Miyamoto
PDF
Single Command Deployのための gradle-aws-plugin講座
by
都元ダイスケ Miyamoto
PDF
20150908 ”時間の流れ” という無限リストを扱うAWS Lambda
by
都元ダイスケ Miyamoto
PDF
体で覚えるSQS! DEVIO-MTUP11-TOKYO-007
by
都元ダイスケ Miyamoto
PDF
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
PDF
20140315 JAWS DAYS 2014 ACEに聞け! CloudFormation編
by
都元ダイスケ Miyamoto
PDF
20131210 CM re:Growth - Infrastructure as Code から Full Reproducible Infrastru...
by
都元ダイスケ Miyamoto
PDF
20130516 cm課外授業8-aws
by
都元ダイスケ Miyamoto
PDF
20121206 VOYAGE LT - 名前重要って言うけどさ
by
都元ダイスケ Miyamoto
PDF
20120830 DBリファクタリング読書会第三回
by
都元ダイスケ Miyamoto
PDF
java-ja 第1回 チキチキ『( ゜ェ゜)・;'.、ゴフッ』 - Strategy
by
都元ダイスケ Miyamoto
PDF
DevLOVE Beautiful Development - 第一幕 陽の巻
by
都元ダイスケ Miyamoto
PDF
DevelopersSummit2011 【17-E-1】 DBも変化せよ - Jiemamy
by
都元ダイスケ Miyamoto
認証の標準的な方法は分かった。では認可はどう管理するんだい? #cmdevio
by
都元ダイスケ Miyamoto
アプリケーション動作ログ、 ERRORで出すか? WARNで出すか? #cmdevio2019
by
都元ダイスケ Miyamoto
マイクロサービス時代の認証と認可 - AWS Dev Day Tokyo 2018 #AWSDevDay
by
都元ダイスケ Miyamoto
クラスメソッドにおける Web API エンジニアリングの基本的な考え方と標準定義 - Developers.IO 2018 (2018-10-05)
by
都元ダイスケ Miyamoto
AWSクラウドデータストレージ総論
by
都元ダイスケ Miyamoto
20170312 F.K様向け ライフパートナーM.M様のご提案
by
都元ダイスケ Miyamoto
Spring Day 2016 - Web API アクセス制御の最適解
by
都元ダイスケ Miyamoto
マイクロWebアプリケーション - Developers.IO 2016
by
都元ダイスケ Miyamoto
Single Command Deployのための gradle-aws-plugin講座
by
都元ダイスケ Miyamoto
20150908 ”時間の流れ” という無限リストを扱うAWS Lambda
by
都元ダイスケ Miyamoto
体で覚えるSQS! DEVIO-MTUP11-TOKYO-007
by
都元ダイスケ Miyamoto
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
20140315 JAWS DAYS 2014 ACEに聞け! CloudFormation編
by
都元ダイスケ Miyamoto
20131210 CM re:Growth - Infrastructure as Code から Full Reproducible Infrastru...
by
都元ダイスケ Miyamoto
20130516 cm課外授業8-aws
by
都元ダイスケ Miyamoto
20121206 VOYAGE LT - 名前重要って言うけどさ
by
都元ダイスケ Miyamoto
20120830 DBリファクタリング読書会第三回
by
都元ダイスケ Miyamoto
java-ja 第1回 チキチキ『( ゜ェ゜)・;'.、ゴフッ』 - Strategy
by
都元ダイスケ Miyamoto
DevLOVE Beautiful Development - 第一幕 陽の巻
by
都元ダイスケ Miyamoto
DevelopersSummit2011 【17-E-1】 DBも変化せよ - Jiemamy
by
都元ダイスケ Miyamoto
20121215 DevLOVE2012 Mahout on AWS
1.
黄色いゾウ使いの パレード ∼Mahout on AWS∼ 都元ダイスケ 2012-12-15
@DevLOVE2012
2.
自己紹介 • 都元ダイスケ (@daisuke_m) •
Java屋です • java-jaから来ま(ry Java オブジェクト指向 Eclipse 恭ライセンス 薬 Mahout Spring XML Jiemamy DDD HadoopOSGi Haskell Scala Maven Wicket AWS 酒
3.
works • 日経ソフトウエア • Java入門記事 •
Eclipse記事
4.
Mahoutインアクション
5.
Mahoutとは • Javaで実装された • スケーラブルな •
オープンソースの • 機械学習ライブラリ
6.
代表的な機械学習 • レコメンド(推薦) • クラスタリング •
クラシファイイング(分類) • その他色々ある
7.
アプリと機械学習 • CRUD (create,
read, update, delete) • FILTER (where) • AGGREGATE (count, sum, ave, max, min...) • SORT (order by) • INTELLIGENCE (machine learning)
8.
スケーラブル • 機械学習の精度は、データ量依存 • データ量に応じ、計算量が指数的に増加 •
大規模な計算リソースが必要 • Hadoop (MapReduce) • AWS Elastic MapReduce
9.
レコメンド 1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 ... 1128 [ 1179:5.0, 3160:4.6582785, ..., 797:4.0637455 ] 1136[ 33493:4.8670673, 6934:4.86497,
..., 230:4.335819 ] ... recommendation 【input】 【output】
10.
非分散 レコメンド
11.
入力データ (intro.csv) 1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 3,101,2.5 3,104,4.0 3,105,4.5 3,107,5.0 4,101,5.0 4,103,3.0 4,104,4.5 4,106,4.0 5,101,4.0 5,102,3.0 5,103,2.0 5,104,4.0 5,105,3.5 5,106,4.0
12.
簡単なレコメンド import java.io.File; import java.util.List; import
org.apache.mahout.cf.taste.impl.model.file.FileDataModel; import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood; import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender; import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity; import org.apache.mahout.cf.taste.model.DataModel; import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood; import org.apache.mahout.cf.taste.recommender.*; import org.apache.mahout.cf.taste.similarity.UserSimilarity; DataModel model = new FileDataModel(new File("intro.csv")); UserSimilarity similarity = new PearsonCorrelationSimilarity(model); UserNeighborhood neighborhood = new NearestNUserNeighborhood(2, similarity, model); Recommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity); List<RecommendedItem> recommendations = recommender.recommend(1, 2); for (RecommendedItem recommendation : recommendations) { System.out.println(recommendation); }
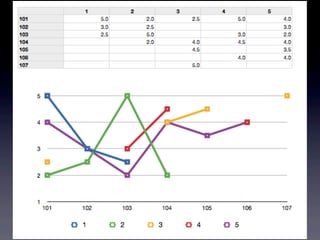
13.
結果! RecommendedItem[item:104, value:4.257081] RecommendedItem[item:106, value:4.0]
14.
レコメンドの理屈 • 1∼5の「ユーザ」 • 101∼107の「アイテム」 •
そしてスコア
16.
• 1さんと5さん似てる • 1さんと4さんも 何と無く似てる •
2さんとは逆の好み? • 3さんとの関連は 見えない
17.
• 1 vs
5 = 0.94 • 1 vs 4 = 0.99 • 1 vs 2 = -0.76 • 1 vs 3 = NaN • 1 vs 1 = 1.0
18.
相関係数 • 1 vs
1 = 1.0 • 1 vs 2 = -0.7642652566278799 • 1 vs 3 = NaN • 1 vs 4 = 0.9999999999999998 • 1 vs 5 = 0.944911182523068 それぞれの人が1さんの予想評点に与える影響度
19.
http://ja.wikipedia.org/wiki/相関係数
20.
加重平均 0.94 ×0.99 × 0.94
× 0.94 ×0.99 × )/ 1.93 )/ 0.94 )/ 1.93 4.25 =( 3.50 =( 4.00 =( この情報は 相関係数が低い またはNaNなので もうアテにしない
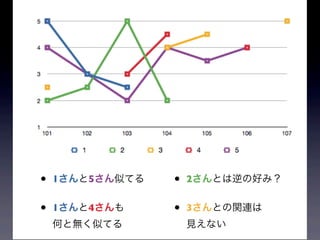
21.
結果! RecommendedItem[item:104, value:4.257081] RecommendedItem[item:106, value:4.0] (再掲)
22.
分散 レコメンド
23.
分散レコメンド 1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 ... 1128 [ 1179:5.0, 3160:4.6582785, ..., 797:4.0637455 ] 1136[ 33493:4.8670673, 6934:4.86497,
..., 230:4.335819 ] ... recommendation 【input】 【output】 S3 S3EMR
24.
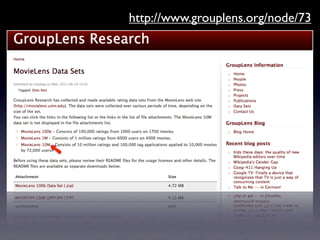
http://www.grouplens.org/node/73
25.
• 1万アイテム • 7万2千ユーザ •
1千万評価 MovieLens 10M 実は これでも まだ小規模 だと思う
26.
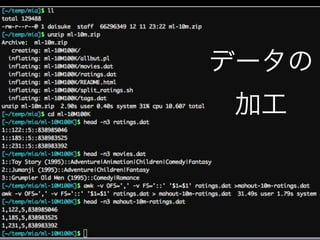
データの 加工
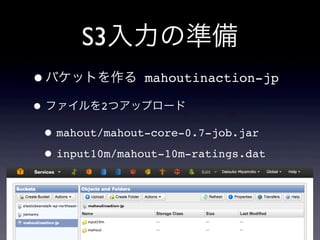
27.
S3入力の準備 •バケットを作る mahoutinaction-jp •ファイルを2つアップロード •mahout/mahout-core-0.7-job.jar •input10m/mahout-10m-ratings.dat
28.
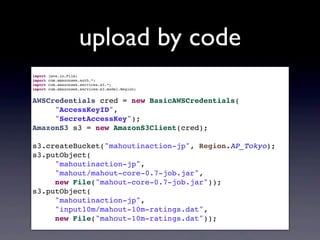
upload by code import
java.io.File; import com.amazonaws.auth.*; import com.amazonaws.services.s3.*; import com.amazonaws.services.s3.model.Region; AWSCredentials cred = new BasicAWSCredentials( "AccessKeyID", "SecretAccessKey"); AmazonS3 s3 = new AmazonS3Client(cred); s3.createBucket("mahoutinaction-jp", Region.AP_Tokyo); s3.putObject( "mahoutinaction-jp", "mahout/mahout-core-0.7-job.jar", new File("mahout-core-0.7-job.jar")); s3.putObject( "mahoutinaction-jp", "input10m/mahout-10m-ratings.dat", new File("mahout-10m-ratings.dat"));
29.
EMRの起動 • JAR Location mahoutinaction-jp/mahout/ mahout-core-0.7-job.jar •
JAR Arguments org.apache.mahout.cf.taste.hadoop.item.RecommenderJob -Dmapred.map.tasks=40 -Dmapred.reduce.tasks=19 -Dmapred.input.dir=s3n://mahoutinaction-jp/input10m -Dmapred.output.dir=s3n://mahoutinaction-jp/output10m --numRecommendations 100 --similarityClassname SIMILARITY_PEARSON_CORRELATION
30.
compute by code import
com.amazonaws.auth.*; import com.amazonaws.services.elasticmapreduce.*; import com.amazonaws.services.elasticmapreduce.model.*; import com.amazonaws.services.elasticmapreduce.util.*; AWSCredentials cred = new BasicAWSCredentials( "AccessKeyID", "SecretAccessKey"); AmazonElasticMapReduce emr = new AmazonElasticMapReduceClient(cred); emr.setEndpoint("elasticmapreduce.ap-northeast-1.amazonaws.com"); RunJobFlowRequest runRequest = new RunJobFlowRequest() .withName("mahout-10m") .withSteps( ... ) // detailed on next page .withInstances( ... ) // detailed on next page .withAmiVersion("2.1.4") .withLogUri("s3n://mahoutinaction-jp/log"); RunJobFlowResult runResult = emr.runJobFlow(runRequest);
31.
RunJobFlowRequest runRequest =
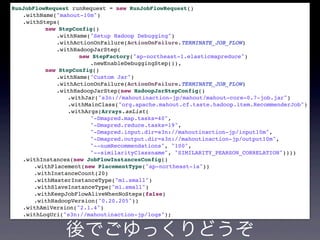
new RunJobFlowRequest() .withName("mahout-10m") .withSteps( new StepConfig() .withName("Setup Hadoop Debugging") .withActionOnFailure(ActionOnFailure.TERMINATE_JOB_FLOW) .withHadoopJarStep( new StepFactory("ap-northeast-1.elasticmapreduce") .newEnableDebuggingStep()), new StepConfig() .withName("Custom Jar") .withActionOnFailure(ActionOnFailure.TERMINATE_JOB_FLOW) .withHadoopJarStep(new HadoopJarStepConfig() .withJar("s3n://mahoutinaction-jp/mahout/mahout-core-0.7-job.jar") .withMainClass("org.apache.mahout.cf.taste.hadoop.item.RecommenderJob") .withArgs(Arrays.asList( "-Dmapred.map.tasks=40", "-Dmapred.reduce.tasks=19", "-Dmapred.input.dir=s3n://mahoutinaction-jp/input10m", "-Dmapred.output.dir=s3n://mahoutinaction-jp/output10m", "--numRecommendations", "100", "--similarityClassname", "SIMILARITY_PEARSON_CORRELATION")))) .withInstances(new JobFlowInstancesConfig() .withPlacement(new PlacementType("ap-northeast-1a")) .withInstanceCount(20) .withMasterInstanceType("m1.small") .withSlaveInstanceType("m1.small") .withKeepJobFlowAliveWhenNoSteps(false) .withHadoopVersion("0.20.205")) .withAmiVersion("2.1.4") .withLogUri("s3n://mahoutinaction-jp/logs"); 後でごゆっくりどうぞ
32.
watch by code AmazonElasticMapReduce
emr = ...; RunJobFlowResult runResult = ...; String jobFlowId = runResult.getJobFlowId(); DescribeJobFlowsRequest describeRequest = new DescribeJobFlowsRequest().withJobFlowIds(jobFlowId); DescribeJobFlowsResult describeResult = emr.describeJobFlows(describeRequest); JobFlowDetail detail = describeResult.getJobFlows().get(0); JobFlowExecutionStatusDetail statusDetail = detail.getExecutionStatusDetail(); JobFlowExecutionState state = JobFlowExecutionState.fromValue(statusDetail.getState()); // COMPLETED, FAILED, TERMINATED, RUNNING, SHUTTING_DOWN, // STARTING, WAITING, BOOTSTRAPPING
33.
結果を取り出す 指定したロケーションにファイルが いくつか生成されている。
35.
download by code import
java.io.InputStream; import java.util.List; import com.amazonaws.auth.*; import com.amazonaws.services.s3.*; import com.amazonaws.services.s3.model.*; AWSCredentials cred = new BasicAWSCredentials( "AccessKeyID", "SecretAccessKey"); AmazonS3 s3 = new AmazonS3Client(cred); ObjectListing listing = s3.listObjects( "mahoutinaction-jp", "output10m"); List<S3ObjectSummary> summaries = listing.getObjectSummaries(); for (S3ObjectSummary summary : summaries) { System.out.println(summary.getKey()); if (summary.getKey().endsWith("/_SUCCESS")) { continue; } S3Object obj = s3.getObject("mahoutinaction-jp", summary.getKey()); InputStream in = obj.getObjectContent(); // ... }
36.
Summary • 機械学習 は、ちょっとインテリな機能 •
分散・非分散アルゴリズム • 非分散ならオンラインで • 分散ならAWSのEMRで • 本スライドはこの後すぐにUP予定。 Twitterで @daisuke_m をチェック!
Download










![レコメンド
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
...
1128 [
1179:5.0,
3160:4.6582785, ...,
797:4.0637455
]
1136[
33493:4.8670673,
6934:4.86497, ...,
230:4.335819
]
...
recommendation
【input】 【output】](https://image.slidesharecdn.com/20121215-devlove2012-mahout-121215032930-phpapp01/85/20121215-DevLOVE2012-Mahout-on-AWS-9-320.jpg)


![結果!
RecommendedItem[item:104, value:4.257081]
RecommendedItem[item:106, value:4.0]](https://image.slidesharecdn.com/20121215-devlove2012-mahout-121215032930-phpapp01/85/20121215-DevLOVE2012-Mahout-on-AWS-13-320.jpg)




![結果!
RecommendedItem[item:104, value:4.257081]
RecommendedItem[item:106, value:4.0]
(再掲)](https://image.slidesharecdn.com/20121215-devlove2012-mahout-121215032930-phpapp01/85/20121215-DevLOVE2012-Mahout-on-AWS-21-320.jpg)

![分散レコメンド
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
...
1128 [
1179:5.0,
3160:4.6582785, ...,
797:4.0637455
]
1136[
33493:4.8670673,
6934:4.86497, ...,
230:4.335819
]
...
recommendation
【input】 【output】
S3 S3EMR](https://image.slidesharecdn.com/20121215-devlove2012-mahout-121215032930-phpapp01/85/20121215-DevLOVE2012-Mahout-on-AWS-23-320.jpg)




























![[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法](https://cdn.slidesharecdn.com/ss_thumbnails/di08-170605024559-thumbnail.jpg?width=640&height=640&fit=bounds)








![[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)](https://cdn.slidesharecdn.com/ss_thumbnails/20130925aws-meister-regenerate-emrpublic-130926030316-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



































