Download to read offline










![Publisher[T] Subscriber[T]](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-15-320.jpg)
![Think abstractly about these lines.
“async boundary”
This can be the network, or threads on the same CPU.
Publisher[T] Subscriber[T]](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-16-320.jpg)


![Publisher[T] Subscriber[T]
100 messages /
1 second
1 message /
1second
Fast Slow](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-19-320.jpg)
![Publisher[T] Subscriber[T]](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-20-320.jpg)
![Publisher[T] Subscriber[T]
drop overflowed
require resending](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-21-320.jpg)
![Publisher[T] Subscriber[T]
has to keep track
of messages to resend
not safe & complicated](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-22-320.jpg)

![Publisher[T] Subscriber[T]](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-24-320.jpg)
![Publisher[T] Subscriber[T]
stop!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-25-320.jpg)
![Publisher[T] Subscriber[T]
stop!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-26-320.jpg)
![Publisher[T] Subscriber[T]
stop!
sh#t!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-27-320.jpg)
![Publisher[T] Subscriber[T]
publisher didn’t receive NACK in time
so we lost that last message
not safe](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-28-320.jpg)

![Publisher[T] Subscriber[T]
100 messages /
1 second
1 message /
1second
FastSlow](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-30-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-31-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-32-320.jpg)
![Publisher[T] Subscriber[T]](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-33-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-34-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-35-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-36-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-37-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-38-320.jpg)
![Publisher[T] Subscriber[T]
gimme!](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-39-320.jpg)



![Publisher[T] Subscriber[T]
Data
Demand(n)](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-43-320.jpg)
![Publisher[T] Subscriber[T]
Data
Demand(n)
Dynamic Push/Pull
bounded buffers with no overflow
demand can be accumulated
batch processing -> performance](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-44-320.jpg)













 => a + b)
Sink.fold[Int, Int](0)(_ + _)
Sink.foreach[String](println)
FileIO.toPath(Paths.get("file.txt"))](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-59-320.jpg)
![val fold: Sink[Int, Future[Int]] = Sink.fold[Int, Int](0)(_ + _)](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-60-320.jpg)
![val fold: Sink[Int, Future[Int]] = Sink.fold[Int, Int](0)(_ + _)
Input type](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-61-320.jpg)
![val fold: Sink[Int, Future[Int]] = Sink.fold[Int, Int](0)(_ + _)
Materialized type](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-62-320.jpg)
![val fold: Sink[Int, Future[Int]] = Sink.fold[Int, Int](0)(_ + _)
Materialized type
Available when the stream ‘completes’](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-63-320.jpg)
![val fold: Sink[Int, Future[Int]] = Sink.fold[Int, Int](0)(_ + _)
val futureRes: Future[Int] = Source(1 to 10).runWith(fold)
futureRes.foreach(println)
// 55](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-64-320.jpg)

![val double: Flow[Int, Int, NotUsed] = Flow[Int].map(_ * 2)](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-67-320.jpg)
![val src = Source(1 to 10)
val double = Flow[Int].map(_ * 2)
val negate = Flow[Int].map(_ * -1)
val print = Sink.foreach[Int](println)
val graph = src via double via negate to print
graph.run()
-2
-4
-6
-8
-10
-12
-14
-16
-18
-20](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-68-320.jpg)






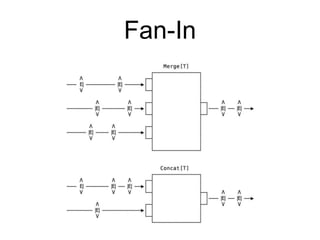


![bcast
ByteString
Convert to
Array[Byte]
flow
bcast
Process High
Res flow
Process Low
Res flow
Process Med
Res flow
sink
sink
sink](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-79-320.jpg)
)
val bcastRawBytes = b.add(Broadcast[Array[Byte]](3))
val processHigh: Flow[Array[Byte], ByteString, NotUsed]
val processMedium: Flow[Array[Byte], ByteString, NotUsed]
val processLow: Flow[Array[Byte], ByteString, NotUsed]
bcastInput.out(0) ~> byteAcc ~> bcastRawBytes ~> processHigh ~> highSink
bcastRawBytes ~> processMedium ~> mediumSink
bcastRawBytes ~> processLow ~> lowSink
SinkShape(bcastInput.in)
}
})
Our custom Sink](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-80-320.jpg)
)
val bcastRawBytes = b.add(Broadcast[Array[Byte]](3))
val processHigh: Flow[Array[Byte], ByteString, NotUsed]
val processMedium: Flow[Array[Byte], ByteString, NotUsed]
val processLow: Flow[Array[Byte], ByteString, NotUsed]
bcastInput.out(0) ~> byteAcc ~> bcastRawBytes ~> processHigh ~> highSink
bcastRawBytes ~> processMedium ~> mediumSink
bcastRawBytes ~> processLow ~> lowSink
SinkShape(bcastInput.in)
}
})
Has one input of type ByteString](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-81-320.jpg)
)
val bcastRawBytes = b.add(Broadcast[Array[Byte]](3))
val processHigh: Flow[Array[Byte], ByteString, NotUsed]
val processMedium: Flow[Array[Byte], ByteString, NotUsed]
val processLow: Flow[Array[Byte], ByteString, NotUsed]
bcastInput.out(0) ~> byteAcc ~> bcastRawBytes ~> processHigh ~> highSink
bcastRawBytes ~> processMedium ~> mediumSink
bcastRawBytes ~> processLow ~> lowSink
SinkShape(bcastInput.in)
}
})](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-82-320.jpg)
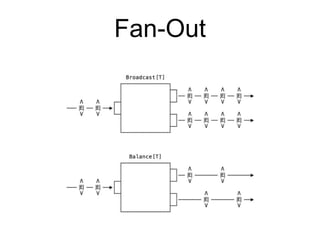
![Describes 3 processing stages
That are Flows of Array[Byte] => ByteString
Sink.fromGraph(GraphDSL.create(highRes, mediumRes, lowRes)((_, _, _){ implicit b =>
(highSink, mediumSink, lowSink) => {
import GraphDSL.Implicits._
val bcastInput = b.add(Broadcast[ByteString](1))
val bcastRawBytes = b.add(Broadcast[Array[Byte]](3))
val processHigh: Flow[Array[Byte], ByteString, NotUsed]
val processMedium: Flow[Array[Byte], ByteString, NotUsed]
val processLow: Flow[Array[Byte], ByteString, NotUsed]
bcastInput.out(0) ~> byteAcc ~> bcastRawBytes ~> processHigh ~> highSink
bcastRawBytes ~> processMedium ~> mediumSink
bcastRawBytes ~> processLow ~> lowSink
SinkShape(bcastInput.in)
}
})
Has one input of type ByteString
Takes 3 Sinks, which can be Files, DBs, etc.](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-83-320.jpg)
![Describes 3 processing stages
That are Flows of Array[Byte] => ByteString
Sink.fromGraph(GraphDSL.create(highRes, mediumRes, lowRes)((_, _, _){ implicit b =>
(highSink, mediumSink, lowSink) => {
import GraphDSL.Implicits._
val bcastInput = b.add(Broadcast[ByteString](1))
val bcastRawBytes = b.add(Broadcast[Array[Byte]](3))
val processHigh: Flow[Array[Byte], ByteString, NotUsed]
val processMedium: Flow[Array[Byte], ByteString, NotUsed]
val processLow: Flow[Array[Byte], ByteString, NotUsed]
bcastInput.out(0) ~> byteAcc ~> bcastRawBytes ~> processHigh ~> highSink
bcastRawBytes ~> processMedium ~> mediumSink
bcastRawBytes ~> processLow ~> lowSink
SinkShape(bcastInput.in)
}
})
Has one input of type ByteString
Emits result to the 3 Sinks
Takes 3 Sinks, which can be Files, DBs, etc.](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-84-320.jpg)
![Has a type of:
Sink[ByteString, (Future[IOResult], Future[IOResult], Future[IOResult])]
Sink.fromGraph(GraphDSL.create(highRes, mediumRes, lowRes)((_, _, _){ implicit b =>
(highSink, mediumSink, lowSink) => {
import GraphDSL.Implicits._
val bcastInput = b.add(Broadcast[ByteString](1))
val bcastRawBytes = b.add(Broadcast[Array[Byte]](3))
val processHigh: Flow[Array[Byte], ByteString, NotUsed]
val processMedium: Flow[Array[Byte], ByteString, NotUsed]
val processLow: Flow[Array[Byte], ByteString, NotUsed]
bcastInput.out(0) ~> byteAcc ~> bcastRawBytes ~> processHigh ~> highSink
bcastRawBytes ~> processMedium ~> mediumSink
bcastRawBytes ~> processLow ~> lowSink
SinkShape(bcastInput.in)
}
})](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-85-320.jpg)
![Sink[ByteString, (Future[IOResult], Future[IOResult], Future[IOResult])]
Materialized values
Sink.fromGraph(GraphDSL.create(highRes, mediumRes, lowRes)((_, _, _){ implicit b =>
(highSink, mediumSink, lowSink) => {
import GraphDSL.Implicits._
val bcastInput = b.add(Broadcast[ByteString](1))
val bcastRawBytes = b.add(Broadcast[Array[Byte]](3))
val processHigh: Flow[Array[Byte], ByteString, NotUsed]
val processMedium: Flow[Array[Byte], ByteString, NotUsed]
val processLow: Flow[Array[Byte], ByteString, NotUsed]
bcastInput.out(0) ~> byteAcc ~> bcastRawBytes ~> processHigh ~> highSink
bcastRawBytes ~> processMedium ~> mediumSink
bcastRawBytes ~> processLow ~> lowSink
SinkShape(bcastInput.in)
}
})](https://image.slidesharecdn.com/akka-streams-ppt-160823172329/85/Intro-to-Akka-Streams-86-320.jpg)



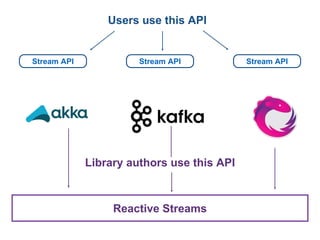
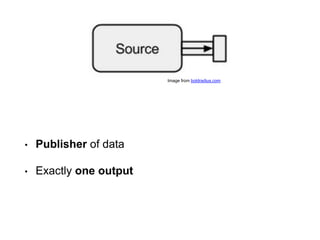
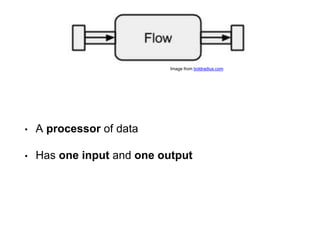
The document discusses reactive streams, focusing on the Akka Streams library, which standardizes asynchronous, back-pressured stream processing. It outlines the core concepts and API, emphasizing the importance of handling varying rates of data flow between publishers and subscribers while ensuring safe and efficient message processing. Furthermore, it highlights the design philosophy enabling compositionality and reusability in building data processing pipelines.































![Introduction to Akka Streams [Part-I]](https://cdn.slidesharecdn.com/ss_thumbnails/babystepsinakkastreampart-i-171117070802-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Tokyo Scala User Group] Akka Streams & Reactive Streams (0.7)](https://cdn.slidesharecdn.com/ss_thumbnails/2014-akka-streams-tokyo-140914201812-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























