













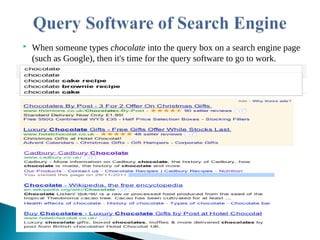




![* Every word matters- All the words you put in the
search box will be used.
* Search is always case insensitive- A search for
[ugc.ac.in] is the same as a search for [UGC]
* Generally, punctuation is ignored, including
@#$%^&*()=+[]/ and other special characters.](https://image.slidesharecdn.com/internetsearchanddrmissues-220224071403/85/Internet-Search-and-DRM-Issues-18-320.jpg)








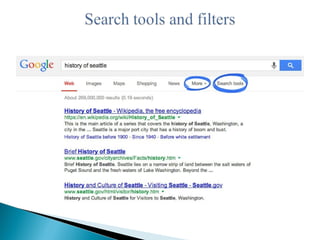
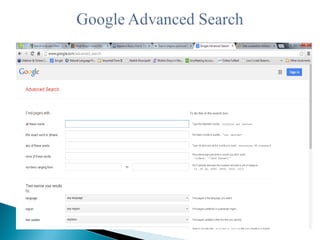

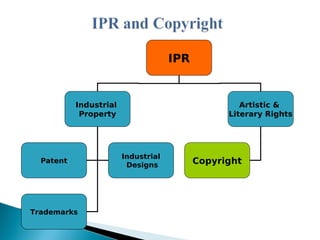

















The document presents an overview of information search methodologies and the functionalities of web search engines, emphasizing systematic and exhaustive searching techniques. It covers essential aspects of search engines, including the roles of spiders, indexing, and query software, alongside effective search strategies and copyright laws regarding digital content and rights management. Additionally, it discusses the impact of digitization on copyright, highlighting the need for updated legal measures like the Digital Millennium Copyright Act (DMCA) to protect intellectual property in the digital age.















































