Recommended
PDF
CLUB DB2 第137回:基礎から再入門!DB2モニタリング入門
PDF
JJUG CCC 2014 Spring IBM SDK for Java 8の全貌 #jjug_ccc #ccc_r57
PDF
CLUB DB2 第122回 DB2管理本の著者が教える 簡単運用管理入門
PDF
PDF
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
PDF
Db tech showcase2015 how to replicate between clusters
PDF
PDF
20130203 OSS-DB Exam Silver 技術解説無料セミナー
PPTX
Spark Structured Streaming with Kafka
PDF
PPTX
Modern stream processing by Spark Structured Streaming
PDF
PPTX
データベースMeetup~Vol.1 HANA概要からOLAPアプリの進化
PPTX
データベースMeetup~Vol.2 HANAのOLTPのからくり
PDF
PDF
Amazon Aurora Deep Dive (db tech showcase 2016)
PDF
PDF
[db tech showcase Tokyo 2015] B17:PostgreSQLで動的にスケールアウト可能な負荷分散DBクラスタを作ろう! by ...
PDF
PDF
[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata
PDF
Dbts2015 tokyo vector_in_hadoop_vortex
PDF
シンプルでシステマチックな Oracle Database, Exadata 性能分析
PPTX
SQLまで使える高機能NoSQLであるCouchbase Serverの勉強会資料
PDF
PDF
KEY
NHN techcon-20120519-fujimoto
PDF
バックアップことはじめ JPUG第29回しくみ+アプリケーション分科会(2014-05-31)
PPTX
PDF
iOS/Androidにも対応した SQL Anywhere 12の魅力
PDF
More Related Content
PDF
CLUB DB2 第137回:基礎から再入門!DB2モニタリング入門
PDF
JJUG CCC 2014 Spring IBM SDK for Java 8の全貌 #jjug_ccc #ccc_r57
PDF
CLUB DB2 第122回 DB2管理本の著者が教える 簡単運用管理入門
PDF
PDF
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
PDF
Db tech showcase2015 how to replicate between clusters
PDF
PDF
20130203 OSS-DB Exam Silver 技術解説無料セミナー
What's hot
PPTX
Spark Structured Streaming with Kafka
PDF
PPTX
Modern stream processing by Spark Structured Streaming
PDF
PPTX
データベースMeetup~Vol.1 HANA概要からOLAPアプリの進化
PPTX
データベースMeetup~Vol.2 HANAのOLTPのからくり
PDF
PDF
Amazon Aurora Deep Dive (db tech showcase 2016)
PDF
PDF
[db tech showcase Tokyo 2015] B17:PostgreSQLで動的にスケールアウト可能な負荷分散DBクラスタを作ろう! by ...
PDF
PDF
[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata
PDF
Dbts2015 tokyo vector_in_hadoop_vortex
PDF
シンプルでシステマチックな Oracle Database, Exadata 性能分析
PPTX
SQLまで使える高機能NoSQLであるCouchbase Serverの勉強会資料
PDF
PDF
KEY
NHN techcon-20120519-fujimoto
PDF
バックアップことはじめ JPUG第29回しくみ+アプリケーション分科会(2014-05-31)
PPTX
Similar to [INSIGHT OUT 2011] B27 SQL Anywhereの先進のセルフヒーリング技術について(glenn paulley)
PDF
iOS/Androidにも対応した SQL Anywhere 12の魅力
PDF
PDF
20121130 solaris-11.1-day.ohsone
PDF
【17-C-1】 Big Data を扱うアーキテクチャーの原則
PDF
PPTX
PDF
SQL Server運用実践 - 3年間80台の運用経験から20の教訓
PDF
PDF
[INSIGHT OUT 2011] C26 ミッションクリティカルを実現する国産データベースHiRDBの技術(hara)
PPTX
Cloud impact on IT industry (in Japanese)
PDF
Sql server 2012 の新機能を使ってみよう。db 管理者向け機能の紹介
PDF
Sql server 2012 の新機能を 3 つの視点でご紹介(大阪版)
PDF
RWC2012(ワコムアイティ&テクノプロジェクト)
PDF
Awsのクラウドデザインパターンをwindows azureに持ってきてみた
PDF
PPTX
A 1-3 awsのクラウドデザインパターンをwindows-azureに持ってきてみた
PDF
PDF
PPTX
PDF
More from Insight Technology, Inc.
PDF
PDF
Docker and the Oracle Database
PDF
Great performance at scale~次期PostgreSQL12のパーティショニング性能の実力に迫る~
PDF
PDF
仮想通貨ウォレットアプリで理解するデータストアとしてのブロックチェーン
PDF
PDF
PDF
PDF
SQL Server エンジニアのためのコンテナ入門
PDF
Lunch & Learn, AWS NoSQL Services
PDF
db tech showcase2019オープニングセッション @ 森田 俊哉
PDF
db tech showcase2019 オープニングセッション @ 石川 雅也
PDF
db tech showcase2019 オープニングセッション @ マイナー・アレン・パーカー
PPTX
難しいアプリケーション移行、手軽に試してみませんか?
PPTX
Attunityのソリューションと異種データベース・クラウド移行事例のご紹介
PPTX
PPTX
コモディティサーバー3台で作る高速処理 “ハイパー・コンバージド・データベース・インフラストラクチャー(HCDI)” システム『Insight Qube』...
PDF
複数DBのバックアップ・切り戻し運用手順が異なって大変?!運用性の大幅改善、その先に。。
PPTX
Attunity社のソリューションの日本国内外適用事例及びロードマップ紹介[ATTUNITY & インサイトテクノロジー IoT / Big Data フ...
PPTX
レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]
[INSIGHT OUT 2011] B27 SQL Anywhereの先進のセルフヒーリング技術について(glenn paulley) 1. SQL Anywhere
自己管理データベースシステム
ゼロアドミニストレーション/モバイルデータ管理/クラウド
GLENN PAULLEY
DIRECTOR, ENGINEERING
HTTP://IABLOG.SYBASE.COM/PAULLEY
PAULLEY@SYBASE.COM
1 INSIGHT OUT ‐ 20 October 2011
2. このプレゼンテーションについて
このセッションでは以下について説明します。
• 自動管理データベースの必要性
• SQL Anywhere の設計思想
• SQL Anywhereの関連機能の紹介
− Self management:自己管理
− Self tuning:自己チューニング
− Self healing:自己回復
• クラウドインフラストラクチャー“Fuji (富士)”の紹介
2 INSIGHT OUT ‐ 20 October 2011
3. 弊社製品デモの御紹介
ビデオ:
IVANANYWHERE ドキュメンタリー
YOUTUBEのIVANANYWHEREチャンネルで視聴できます。
http://www.youtube.com/user/IvanAnywhere
3 INSIGHT OUT ‐ 20 October 2011
4. IVANANYWHERE & SQL ANYWHERE
• 御紹介したビデオで使用されている「IvanAnywhere遠隔会
議ロボット」は管理不要なモバイルアプライアンスの一例
• IvanAnywhereに搭載されたSQL Anywhereデータベース
サーバがロボットが収集した各種センサーなどから得られ
るデータをリアルタイムで保管
• 収集されたデータは定期的にデスクトップサーバに同期し、
分析を実行
• IvanAnywhereロボットの(cpu,disk,memory等の)ワーク
ロードは搭載されているタブレットPCで実行されるソフトウェ
アにより変化
• IvanAnywhereに搭載されたSQL Anywhereデータベース
サーバはIvanAnywhere全体のワークロードの変化に応じ
て変化し、他のアプリケーションと協調してリソース
(disk,memory)を共有する必要がある
4 INSIGHT OUT ‐ 20 October 2011
5. 6. SQL Anywhereの設計目標
• 自己管理処理:
• クロスプラットフォームのサポート:
- 32‐ and 64‐bit Windows
- Windows 7, Vista, XP, Server, 2008, 2003, 2000
- Windows CE/Pocket PC
- Linux 32‐ and 64‐bit
- HP‐UX, AIX, Solaris (SPARC and Intel), Mac OS/X
- コンバイラー: Microsoft Visual Studio, GCC, SunPro, XLC (AIX), aCC (HP‐UX)
• 相互運用性:
• 箱から出した状態で発揮できるパフォーマンス:
• 自動管理データベースへの総合的なアプローチ:
6 INSIGHT OUT ‐ 20 October 2011
7. 8. SQL Anywhereの物理的なデータベース設計
• SQL Anywhereデータベースは最大15のデータベース領域で構成
- データベース領域は普通のOSファイル
- 内2つはテンポラリーファイルとトランザクションログの為に予約
- 残りはユーザーデータに使用可能
- UNIXのrawデバイスは非サポート
• データベースはOSのファイルコピーだけでコピー
- イメージコピーユーティリティーは不要
- 違うマシンやモバイルデバイスへのデータベースの配備が容易
- ファイルは、全対応プラットフォームで相互にコピーするだけで使用可能。
変換作業も不要
• DB内の文字コードを変えたい時等の為に変換ツールも用意していま
す。
8
8 INSIGHT OUT ‐ 20 October 2011
9. 物理的なデータベース設計
• データベースファイルサイズはデータ量の増大に応じて自動的に拡大
- ディスクが一杯になった場合はSQL Anywhereデータベースサーバが
(予め設定しておいた)コールバック関数を呼び出すことが可能
- SQL処理で一時ファイルが必要な時に枯渇しないようにテンポラリファ
イルガバナー機構が使用可能
• プライマリー、外部キーのインデックスは自動的に作成
- サーバーが自動的に同義、あるいは重複するインデックスを検知
• データベースに定義された複数個の同義・重複インデックスが
ディスク上の同じインデックスデータを共有することができます。
9
9 INSIGHT OUT ‐ 20 October 2011
10. SQL Anywhereのトランザクションログ
• SQL Anywhereは行レベルの論理的なトランザクションログ機構やトランザクショ
ンリカバリー機構を使用(物理コピーやページベースではない)
• トランザクションログからINSERT, UPDATE, DELETE, COMMIT, ROLLBACK 等ログ
に書かれた際に実行されたSQL文に変換が可能
- DBTRANユーティリティーで変換可能
単純なバックアップのリストアからでは復帰出来ない障害からの復旧に役に
-
立ちます。
• 弊社が提供する「Mobile Link」や「SQL Remote」等のデータベース双方向デ-タ
同期ソリューションの根幹としても使用
DELETE
トランザクションログファイル
FROM <table>
DBTRAN WHERE <primary key> = <value>;
COMMIT;
INSERT INTO <table> VALUES ….
10 INSIGHT OUT ‐ 20 October 2011
11. バッファープール自己管理
サーバーキャッシュを動的に拡大・縮小可能
11 INSIGHT OUT ‐ 20 October 2011
12. 動的バッファープールサイジング
• SQL Anywhereサーバーはバッファープールを必要に応じて自動的に拡
大・縮小可能
• これは以下の時に発生:
- データベースサーバのワークロードに応じて
- データベース上で同時に実行されるSQLに応じて
- 同じコンピューター上の他のアプリケーションの物理メモリーの
要求に応じて
- 組み込みアプリケエーションに必須
• 全サポートプラットフォームでデフォルトで使用可能
- 管理者はバッファープールの初期サイズと上限・下限の設定が可能
12 INSIGHT OUT ‐ 20 October 2011
13. SQL Anywhereのバッファープール管理
• バッファープールは一つ(用途別に分かれていない)
バッファーの各用途別に事前割り当てもされていない
-
• バッファープールは以下に使用:
- テーブルとインデックスデータページ
- チェックポイントログページ
- ビットマップページ
- ヒープページ(クエリ実行プラン、最適化グラフ、接続構造、
ストアドプロシージャー、トリガーのデータ構造)
- フリー(使用可能)ページ
• バッファーページのサイズは共通
13 INSIGHT OUT ‐ 20 October 2011
14. SQL Anywhere バッファープール管理
• 単一のバッファープールは自己管理には必須
• サーバースレッド/ファイバで必要な全メモリーはバッファープールから取得
- これによりSQL Anywhereサーバー全体のメモリー容量の管理を実現
• バッファープール内のページ変更スキーマは、バッファーページに発生する
様々な変更要求をそれに応じてデマンドベースで管理可能でなければなら
ない
- マシンのワークロードに応じて処理時間が変化
14 INSIGHT OUT ‐ 20 October 2011
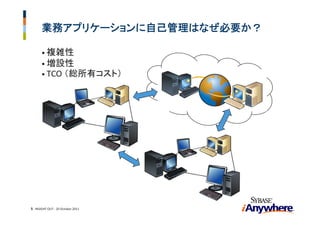
15. ダイナミックバッファープールサイジング
• 基本の考え方: バッファーサイズをOSのサーバープロセスのワーキング
セットサイズに合わせる
- フィードバックコントロールループ
OSの オペレーティング
ワーキング システム
セットサイズ
バッファー
ミス率
調節済み 拡大量 バッファープール
バッファープール
メモリー ・縮小量 マネージャー
ガバナー
ターゲット
新しいバッファー
プールサイズ
15 INSIGHT OUT ‐ 20 October 2011
16. 17. タスクスケジューリングモデル
• データベースサーバーには主に2つのアーキテクチャがある:
• Worker‐per‐connection:
- ユーザー接続毎に要求を処理する“Worker”が割り当てられる
• Worker‐per‐request:
- ユーザーからの処理要求に応じて“Worker Pool”から“Worker”
が割り当てられる。Workerはその処理が完了したらWorker Pool
へ返される
- 同一接続中に複数回処理を要求しても、同じ“Worker”がその
ユーザーからの処理を実行する保証は無い。毎回違う“Worker”
が割り当てられる
17 INSIGHT OUT ‐ 20 October 2011
18. タスクスケジューリングモデル
• SQL Anywhereではworker‐per‐requestモデルを採用
- 少量のリソースで動作させる上で効率的
- マルチスレッドモデルと親和性が高い
- ファイバをサポートしているプラットフォームではファイバを使用(Windows,
Linux)
• マルチプログラミングレベル:ワーカープールのサイズ
- ワーカープールのサイズが同時に実行できるSQLリクエストの最大数を決定
• ワーカープールサイズが使用者数、同時実行数等の「ニーズ」に合っている必要がある
- クラウドでは、仮想化がマルチプログラミングレベルの手動設定を非常に難しくして
いる。
18 INSIGHT OUT ‐ 20 October 2011
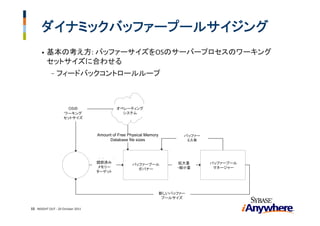
19. MPL(multi programing level)をワークロードに
マッチングさせる
• SQL Anywhereを使用したTPC‐Cに似たワークロード
• 32bit インテルデュアルコアプロセッサー、1GBバッファープール
ス
ル
ー
プ
ッ
ト
(
リ
ク
エ
ス
ト
分
/
)
スレッド数
19 INSIGHT OUT ‐ 20 October 2011
20. マルチプログラミングレベルのトレードオフ
• ワークロードの大小によるトレードオフ:
- ワーカープールが大きい場合:
• サーバーの並列処理数が上がる
• サーバーリソース(memory, I/O)の競合が増える
• サーバーのバッファープールサイズが増える
• スラッシング発生のリスクが増加する
- ワーカープールが小さい場合:
• ハードウェアのリソース使用率が低くなる
• 並列処理数が制限される
• 数によっては即処理できずに一旦「キュー」に入って待たされる可
能性は増える
20 INSIGHT OUT ‐ 20 October 2011
21. マルチプログラミングレベルのトレードオフ
• ワーカープールのサイズはどのように決定すべきか?
- 考慮すべき項目:
• メモリー、I/O、CPUリソースの利用と競合
• 並行処理の際のロック待ちのインパクト
• 求めるパフォーマンスと実際のパフォーマンス
21 INSIGHT OUT ‐ 20 October 2011
22. SQL Anywhereのソリューション
• ワーカープールサイズの動的な自己調整機能
• (例)サーバーのマルチプログラミングレベル(MPL)
- 処理に必要なスレッド数は必要に応じて増減
• これは要求の完了数と要求の新規受付数を監視することで行なっている。
• システムの負荷により自己調整するアルゴリズムは2つの異なった技術から構成
- 特許申請中
- カナダ・ウォータールー大学の支援を受けて開発
22 INSIGHT OUT ‐ 20 October 2011
23. SQL Anywhereのソリューション
• 動的マルチプログラミングレベルの長所:
• データベース管理者が考慮しなければならないパラメーターを1つ削減
• データベースサーバの再スタートの必要なくスループットを改善
• データベースサーバの負荷やシステムリソース状況の変化に自動的に適応
• クラウド環境では非常に重要
• 注意:
• 一瞬増大してその後沈静化するような「爆発的な」処理増大に対しての動的
MPLの効果は限定的
23 INSIGHT OUT ‐ 20 October 2011
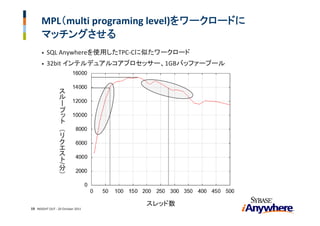
24. SQL Anywhere スケジューラー
ワーカープール
リクエスト ワーカースレッド1
完了したリクエスト
のキュー
ワーカースレッドm
待機中リクエスト 処理中のリクエスト 変数の
コントロール
MISO
並行処理レベル スループット
コントローラー
データベースサーバー
(worker-per-request)
24 INSIGHT OUT ‐ 20 October 2011
25. SQL Anywhereのタスクスケジューリングアーキテクチャー
• サーバーは動的内部並列処理をサポート
- 並列処理の程度は使用可能なリソースによって変動
- 一つの処理要求から分解された各(並列)処理プランは異なるワーカー
を使用
• ディスクにスワップされるのは待機中の処理要求
- 仮想メモリーを使用し、できるだけ物理メモリに確保された容量を一定に
維持しようとします。
- サーバーの負荷増大した場合、ユーザー接続のヒープをディスクにス
ワップ
• 1989年のSQL Anywhereの最初のバージョンで実装
- 要求ベースでヒープのロードを許可するためヒープ内のポインターは適
宜書き換えが発生
25 INSIGHT OUT ‐ 20 October 2011
26. 27. SQL Anywhere クエリオプティマイザー
• SQL AnywhereではSQLは実行する際にオプティマイザにより解析・最適化
• サーバーの状態(リソース状態やディスクの速度等)を考慮
• 複雑なクエリでも最適化処理は高速
− left‐deep treeを構成する結合が主の場合はコストベースのジョインアルゴリズ
ムを使用
− 複雑で入れ子となるLEFT, RIGHT, FULL OUTER JOIN のような際はBushy tree を
使用
− 最適化プロセスはヒューリスティックとコストベースの複雑な書換の両方を含む
− 数量的な限界(結合数等)は ない
• 長所:プランはサーバー環境、バッファープールコンテンツ/サイズ、データの変化
に応じたものになります。パッケージ・バインドファイルのようなものを管理する必要
がない
27 INSIGHT OUT ‐ 20 October 2011
28. クエリオプティマイザーを使用しないパターン
• アクセスプランの迅速な生成のため、単一テーブルの単純なクエリは、クエリ
オプティマイザーで最適化「しない」
- 例:
• SELECT * FROM <table> WHERE <primary key column> = <value>
• ストアドプロシージャー/トリガー/イベントのクエリのアクセスプランは、将来
の実行に備えてキャッシュし、再利用可
- プランが分散(再実行の際にキャッシュしたものと違う事が多い場合)して
いる場合はプランは「トレーニング期間」に入る
- (変数値がない場合でも)プランの分散がない場合には、プランはキャッ
シュして、再利用
- プランが“準”最適にならないようにクエリを対数的なスケールで定期的に
再最適化
28 INSIGHT OUT ‐ 20 October 2011
29. 適応型クエリ処理
• SQL実行途中の中間結果サイズがあまりにオプティマイザが想定したものと異
なる際は、オプティマイザーが(その時点から)実行可能な代替アクセスプラン
を作成することがある。
サーバーがランタイム時に自動的に代替プランにスイッチさせる
-
• メモリー集中処理、例えばハッシュジョインなど:
- クエリ実行中の使用可能メモリーの変化に対して自動的に結合アルゴリズ
ム等が変化することがある。
- 例えばバッファープールの使用率が高い場合は代わりにメモリーの使用量
が低い結合方式(例えばhash‐join から nested‐loop joinなど)に変化するこ
とがある
• メモリーが集中する処理、例えば、大規模なソートなどで、メモリーの割り当て
をコントロールするためにサーバーにはメモリーガバナーが含まれている
- 増大・縮小に合わせてメモリーガバナーはバッファープールサイズに適応
する必要がある
29 INSIGHT OUT ‐ 20 October 2011
30. 適応型クエリ処理
• 幾つかの処理、例えばデータベースのバックアップなどではストレージに
使用されているI/Oデバイスの性能を調査するためサンプリングプロセス
が含まれる。
- 一番の目的は使用可能なディスクヘッドの数を決定すること
- プロセスはスループットを最大にするために「正しい」CPU数を利用可
能
- 最適化アルゴリズムは、システムの他の部分で必要なCPUに敏感。必
要に応じてCPUの使用を自動的にスケールダウン
30 INSIGHT OUT ‐ 20 October 2011
31. 適応型内部並列処理
• SQL Anywhereのアプローチは、アクセスプランを並列処理すると「メ
リットがある場合にそれを実行する」こと。メリットがないと判断すれ
ば並列処理はしない。
- 並列処理の程度は、最適化中のクエリのコスト計算によって決定
• 並列ワークはワーカープールからそれぞれ独立して割り当て
- プランは、並列処理の程度によって広範囲に自己チューニング
- 使用可能なワーカー数が少ない場合は、並列処理によるワー
カーの枯渇を防ぐ設計
31 INSIGHT OUT ‐ 20 October 2011
32. 自己ヒーリング統計
SQL ANYWHERE 12 新機能
32 INSIGHT OUT ‐ 20 October 2011
33. 自律型統計管理
• 1992年に実装されたSQL Anywhereの機能
- 初期の実装では、カラムの密度と頻出値統計を管理するためにhash‐
baseの構造を使用
• 今日
- 自己管理のカラムヒストグラム
• ベーステーブルとテンポラリーテーブルの両方
• 自動的に統計を更新
- 最適化処理中の中間結果分析のためのジョインヒストグラム
- サーバーはリアルタイムで 永続的インデックス統計を維持
- さらに、最適化中にサーバーでインデックスサンプリングを実行可
33 INSIGHT OUT ‐ 20 October 2011
34. カラムヒストグラム
• 自己チューニングの実装
- スタンダード[範囲]バケットや頻出値統計の両方を実装
- 述部の評価とINSERT, UPDATE, MERGE、DELETE 文の結果とともにリアル
タイムにアップデート
- デフォルトでは、統計は毎データ操作SQL リクエストを実行する間に計算
• LIKE述部の最適化に使用するストリングスの統計のキャプチャにはNovelの
技術を使用
• ヒストグラムはLOAD TABLEまたはCREATE INDEX文で自動的に計算
- 必要に応じて明示的に作成/ストップ
- ヒストグラムはデフォルトでアンロード/リロードにわたって保持
34 INSIGHT OUT ‐ 20 October 2011
35. 自己ヒーリング統計へのモチベーション
• 統計の自己チューニングはトランザクション的ではない
− オーバーヘッドを低く保つ
− 統計はROLLBACK文やコンカレントな行修正の際にはエラーを招く可能性がある
• 設計による、自己チューニングアルゴリズム、近似を使用
− より効果的、しかし少々不正確な方法を単一行のUPDATE, INSERT DELETE 文に使用
− 統計の生成にはデータを一度スキャンすることが必要
− 正確さとオーバーヘッドのトレードオフ;完璧は難しい
厳しいデータの偏りでは評価エラーが発生する可能性あり
• 自己チューニングは、ビジーなサーバーでは「キープ」できない可能性がある
− 自己調整した統計の質は独断で下げてしまう。
− システムは自身を監視して修復する必要がある
クラウドの配備には必要不可欠
35 INSIGHT OUT ‐ 20 October 2011
36. SQL Anywhere のソリューション
• 統計的ガバナー: SQL Anywhereの新機能
- バックグラウンドサーバー処理の内部システム
- 使用につれての統計の「質」を自己監視
- 「おそまつな」統計を自己ヒーリング
- 「悪い」統計はとり除く
• 方法
- クエリ処理中の評価エラーを自動的にカテゴリ分けし記録
- 様々な技術を使用して自動的に統計を収集
• 他のSQL クエリのピギーバッキング、インデックス分析、階層化サン
プリング
- 統計的保全性を決定
- オプティマイザで統計的使用を監視
• 使用されていないままの場合はヒストグラムをメモリーからアンロード
- 低オーバーヘッド
36 INSIGHT OUT ‐ 20 October 2011
37. 38. 39. FUJI(富士)の紹介
“Fuji(富士)”は、ISVが妥協することなくクラウドアプリケーション
をビルド、配備、管理するためのデータ管理ソリューションで
す。
39 INSIGHT OUT ‐ 20 October 2011
40. INTRODUCING FUJI
“Fuji(富士)”は、ISVがスケールというクラウドの経済性の利点
を享受し、妥協することなくクラウドアプリケーションをビルド、
配備、管理するためのデータ管理ソリューションです。
40 INSIGHT OUT ‐ 20 October 2011
41. INTRODUCING FUJI
“Fuji(富士)”は、ISVが各顧客を個別に対応できるツールを備え、
スケールというクラウドの経済性の利点を享受し、妥協するこ
となくクラウドアプリケーションをビルド、配備、管理するため
のデータ管理ソリューションです。
41 INSIGHT OUT ‐ 20 October 2011
42. ビデオ:
「ゴーンフィッシング」ソフト社
SQL ANYWHERE ON DEMAND EDITIONのデモ
http://www.ianywhere.jp/saondemand/ で視聴できます。
42 INSIGHT OUT ‐ 20 October 2011
43. 44. まとめ
• SQL Anywhereでは、それぞれの機能が自己管理できるように設計
• 自己管理機能は総合的に考慮しないといけない
- just‐in‐timeの最適化と適応型クエリ処理のどちらもサポートしなけれ
ば動的バッファープールサイジング機能をサポートする意味ない
• 実装には多くの困難・課題
- 製品テストが困難
- 自己管理の要件と全体のサーバーのパフォーマンスとのバランスをと
る必要がある
- オーバーヘッドを低くするのは難しい
- 制御不能な動作の回避の必要性
44 INSIGHT OUT ‐ 20 October 2011
45. Thank You!
• QUESTIONS OR COMMENTS?
• PAULLEY@SYBASE.COM
• HTTP://SQLANYWHERE‐FORUM.SYBASE.COM
• HTTP://IABLOG.SYBASE.COM/PAULLEY
45 INSIGHT OUT ‐ 20 October 2011
46. その他の自己管理機能
• キャッシュウォーミング
- 前回の終了時の状態に応じて起動時に自動的にページキャッシュを読み込ん
でしまう機能
• セルフチューニングパラレルバックアップ
- 自動的に検知する並列処理の程度
• 自動化の「イベント」をサポート
- あるスケジュール時、あるいは検査、観察、対策が必要な特定のサーバーイベ
ントが発生した時
• SQL Anywhere のI/O コストモデル
- 実際の(現実 or 仮想)ハードウェア上で測定可能
• 今後のバージョンでも様々な自己管理機能を計画
46 INSIGHT OUT ‐ 20 October 2011






























![カラムヒストグラム
• 自己チューニングの実装
- スタンダード[範囲]バケットや頻出値統計の両方を実装
- 述部の評価とINSERT, UPDATE, MERGE、DELETE 文の結果とともにリアル
タイムにアップデート
- デフォルトでは、統計は毎データ操作SQL リクエストを実行する間に計算
• LIKE述部の最適化に使用するストリングスの統計のキャプチャにはNovelの
技術を使用
• ヒストグラムはLOAD TABLEまたはCREATE INDEX文で自動的に計算
- 必要に応じて明示的に作成/ストップ
- ヒストグラムはデフォルトでアンロード/リロードにわたって保持
34 INSIGHT OUT ‐ 20 October 2011](https://image.slidesharecdn.com/insightout2011b27sqlanywhereglennpaulley-111114012436-phpapp02/85/INSIGHT-OUT-2011-B27-SQL-Anywhere-glenn-paulley-34-320.jpg)















![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)












![[db tech showcase Tokyo 2015] B17:PostgreSQLで動的にスケールアウト可能な負荷分散DBクラスタを作ろう! by ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b17postgresqlsraoss-150616021919-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata](https://cdn.slidesharecdn.com/ss_thumbnails/d31postgresnagata-131128230735-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[INSIGHT OUT 2011] C26 ミッションクリティカルを実現する国産データベースHiRDBの技術(hara)](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011c26hara-111114012851-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)