Recommended
PDF
[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...
PDF
[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...
PDF
[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...
PDF
[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...
PDF
[db tech showcase Tokyo 2015] D35:高トランザクションを実現するスケーラブルRDBMS技術 by 日本電気株式会社 並木悠太
PDF
[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...
PDF
[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...
PDF
[db tech showcase Tokyo 2015] B17:PostgreSQLで動的にスケールアウト可能な負荷分散DBクラスタを作ろう! by ...
PDF
[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告
PDF
[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔
PDF
PDF
[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...
PDF
IBM版Hadoop - BigInsights/Big SQL (2013/07/26 CLUB DB2発表資料)
PDF
MySQL InnoDB Clusterによる高可用性構成(DB Tech Showcase 2017)
PPTX
[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...
PDF
[db tech showcase Tokyo 2014] L34: そのデータベース 5年後大丈夫ですか by 日本ヒューレット・パッカード株式会社 後藤宏
PDF
[db tech showcase Sapporo 2015] A12:DBAが知っておくべき最新テクノロジー: フラッシュ, ストレージ, クラウド b...
PDF
[db tech showcase Tokyo 2017] E34: データベース・サービスを好きなところで動かそう Db2 Warehouse by 日...
PDF
事例から見るNoSQLの使い方 - db tech showcase Tokyo 2015 2015/06/11
PDF
[db tech showcase Tokyo 2017] B14: 4年連続No.1リーダー評価のストレージでDBクローンするとどんな感じ?瞬時のクロー...
PDF
[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...
PDF
[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...
PDF
Couchbase introduction-20150611
PDF
[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...
PDF
[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...
PDF
[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...
PDF
[db tech showcase Tokyo 2015] A33:Amazon DynamoDB Deep Dive by アマゾン データ サービス ...
PDF
[db tech showcase Tokyo 2015] D33:Superdome X 上の SQL Server 2014 OLTP 検証結果と S...
PDF
[db tech showcase Tokyo 2015] E27: Neo4jグラフデータベース by クリエーションライン株式会社 李昌桓
PDF
[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介
More Related Content
PDF
[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...
PDF
[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...
PDF
[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...
PDF
[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...
PDF
[db tech showcase Tokyo 2015] D35:高トランザクションを実現するスケーラブルRDBMS技術 by 日本電気株式会社 並木悠太
PDF
[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...
PDF
[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...
PDF
[db tech showcase Tokyo 2015] B17:PostgreSQLで動的にスケールアウト可能な負荷分散DBクラスタを作ろう! by ...
What's hot
PDF
[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告
PDF
[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔
PDF
PDF
[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...
PDF
IBM版Hadoop - BigInsights/Big SQL (2013/07/26 CLUB DB2発表資料)
PDF
MySQL InnoDB Clusterによる高可用性構成(DB Tech Showcase 2017)
PPTX
[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...
PDF
[db tech showcase Tokyo 2014] L34: そのデータベース 5年後大丈夫ですか by 日本ヒューレット・パッカード株式会社 後藤宏
PDF
[db tech showcase Sapporo 2015] A12:DBAが知っておくべき最新テクノロジー: フラッシュ, ストレージ, クラウド b...
PDF
[db tech showcase Tokyo 2017] E34: データベース・サービスを好きなところで動かそう Db2 Warehouse by 日...
PDF
事例から見るNoSQLの使い方 - db tech showcase Tokyo 2015 2015/06/11
PDF
[db tech showcase Tokyo 2017] B14: 4年連続No.1リーダー評価のストレージでDBクローンするとどんな感じ?瞬時のクロー...
PDF
[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...
PDF
[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...
PDF
Couchbase introduction-20150611
PDF
[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...
PDF
[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...
PDF
[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...
PDF
[db tech showcase Tokyo 2015] A33:Amazon DynamoDB Deep Dive by アマゾン データ サービス ...
PDF
[db tech showcase Tokyo 2015] D33:Superdome X 上の SQL Server 2014 OLTP 検証結果と S...
Viewers also liked
PDF
[db tech showcase Tokyo 2015] E27: Neo4jグラフデータベース by クリエーションライン株式会社 李昌桓
PDF
[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介
PDF
PDF
Storm×couchbase serverで作るリアルタイム解析基盤
PDF
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
PDF
[db tech showcase Tokyo 2015] C32:「データ一貫性にこだわる日立のインメモリ分散KVS~こだわりの理由と実現方法とは~」 ...
PDF
[db tech showcase Tokyo 2015] C33:ビッグデータ・IoT時代のキーテクノロジー、CEPの「今」を掴む! by 株式会社日立...
PDF
[db tech showcase Tokyo 2015] E15:Hadoop大量データ処理技術と日立匿名化技術によるプライバシー保護とデータ活用 by...
PDF
PDF
[db tech showcase Tokyo 2015] C14:30万のユーザ部門を抱える日立、情シスの「理想と現実」 by 株式会社日立製作所 情報...
PDF
[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...
PDF
[db tech showcase Tokyo 2015] B27:インメモリーDBとスケールアップマシンによりBig Dataの課題を解決する by S...
PDF
[db tech showcase Tokyo 2015] D23:MySQLはドキュメントデータベースになり、HTTPもしゃべる - MySQL Lab...
PDF
DBTS2015 Tokyo DBAが知っておくべき最新テクノロジー
PDF
[db tech showcase Tokyo 2015] C25:HP NonStop SQLはなぜグローバルに分散DBを構築できるのか、 データの整合...
PDF
PDF
[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう
PDF
[db tech showcase Tokyo 2015] D25:The difference between logical and physical...
PDF
Similar to Dbts2015 tokyo vector_in_hadoop_vortex
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
PDF
今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
PDF
PDF
ちょっと理解に自信がないな�という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
PDF
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06
PDF
PDF
[Japan Tech summit 2017] DAL 002
PDF
Osc2012 spring HBase Report
PDF
PDF
Hadoop, NoSQL, GlusterFSの概要
PPTX
PDF
PDF
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
PDF
[db analytics showcase Sapporo 2018] B25 Hadoop上で動く世界最速のAnalytic DBをSparkと一緒に...
PDF
Configureing analytics system with apache spark and object storage service of...
PDF
PPTX
1,000,000 foot view of Hadoop-like parallel data processing systems
PPTX
お見合いで趣味を聞かれたときに 「IoTとビッグデータを少々」と答えたいSEが読む資料
More from Koji Shinkubo
PDF
関西DB勉強会 (SAP HANA, express edition)
PDF
Tech JAM 2016 TEC 11 実践 SAP HANA 大解剖
PDF
Dbts2013 特濃jpoug log_file_sync
PDF
SAP HANA 2 SPS03 highlights and SAP HANA express edition
PDF
Jpoug presents なーんでだ2 db tech showcase 2015 tokyo
PPT
PDF
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
PDF
PDF
PDF
PPTX
PDF
PDF
Meetup! jpoug oracle cloud world - なーんでだ1
PDF
LT SAP HANAネットワークプロトコル初段
Dbts2015 tokyo vector_in_hadoop_vortex 1. 2. アジェンダ
• VectorやVector Hadoop SQL Editionの概要
• Vector Hadoop SQL Editionのアーキテクチャー
• Vector Hadoop SQL Editionの特徴のいくつかをピックアップ
• 簡単な疑似ベンチマークの結果
• 2015年の製品ロードマップ
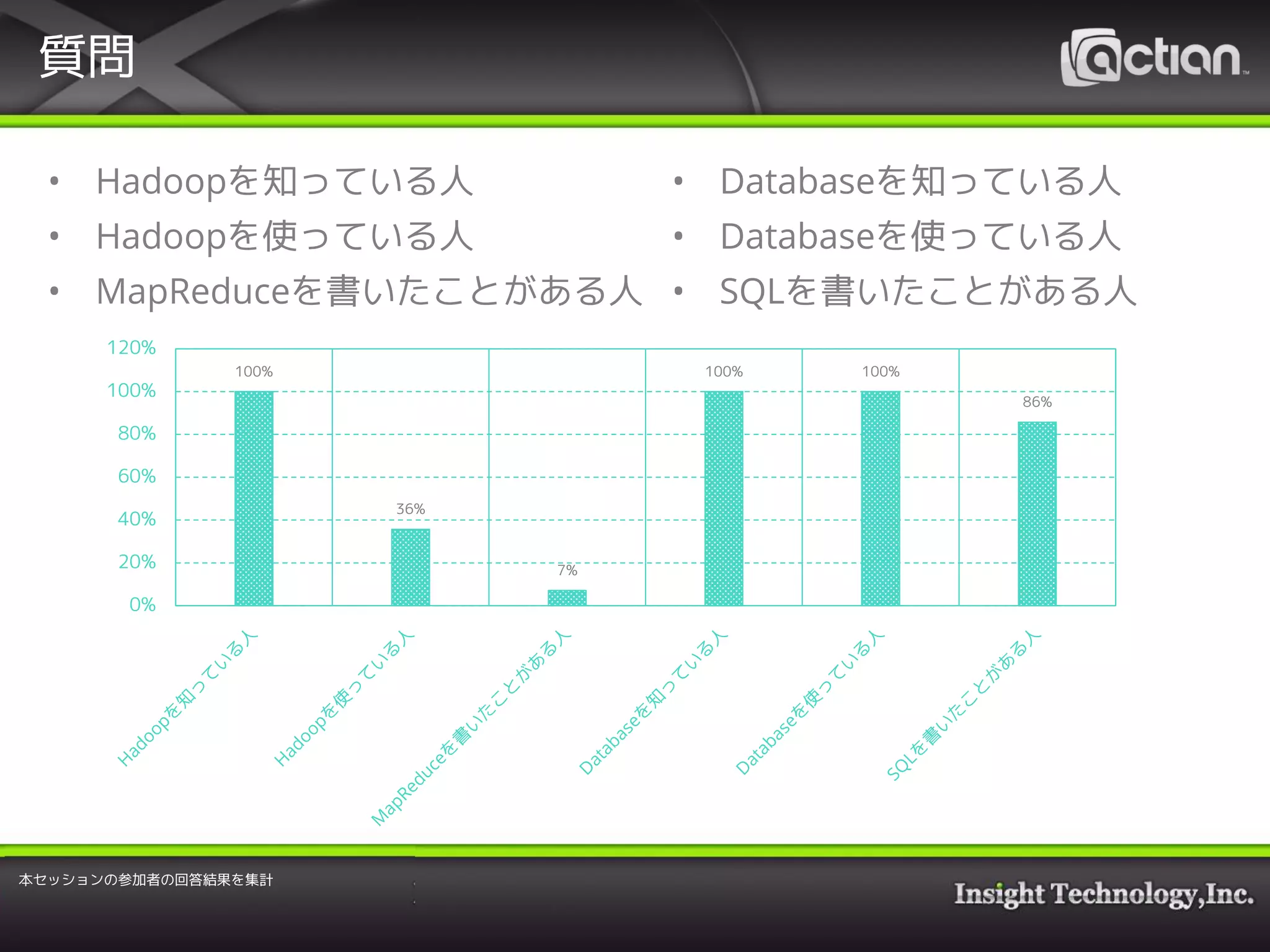
3. 質問
• Hadoopを知っている人
• Hadoopを使っている人
• MapReduceを書いたことがある人
• Databaseを知っている人
• Databaseを使っている人
• SQLを書いたことがある人
100%
36%
7%
100% 100%
86%
0%
20%
40%
60%
80%
100%
120%
本セッションの参加者の回答結果を集計
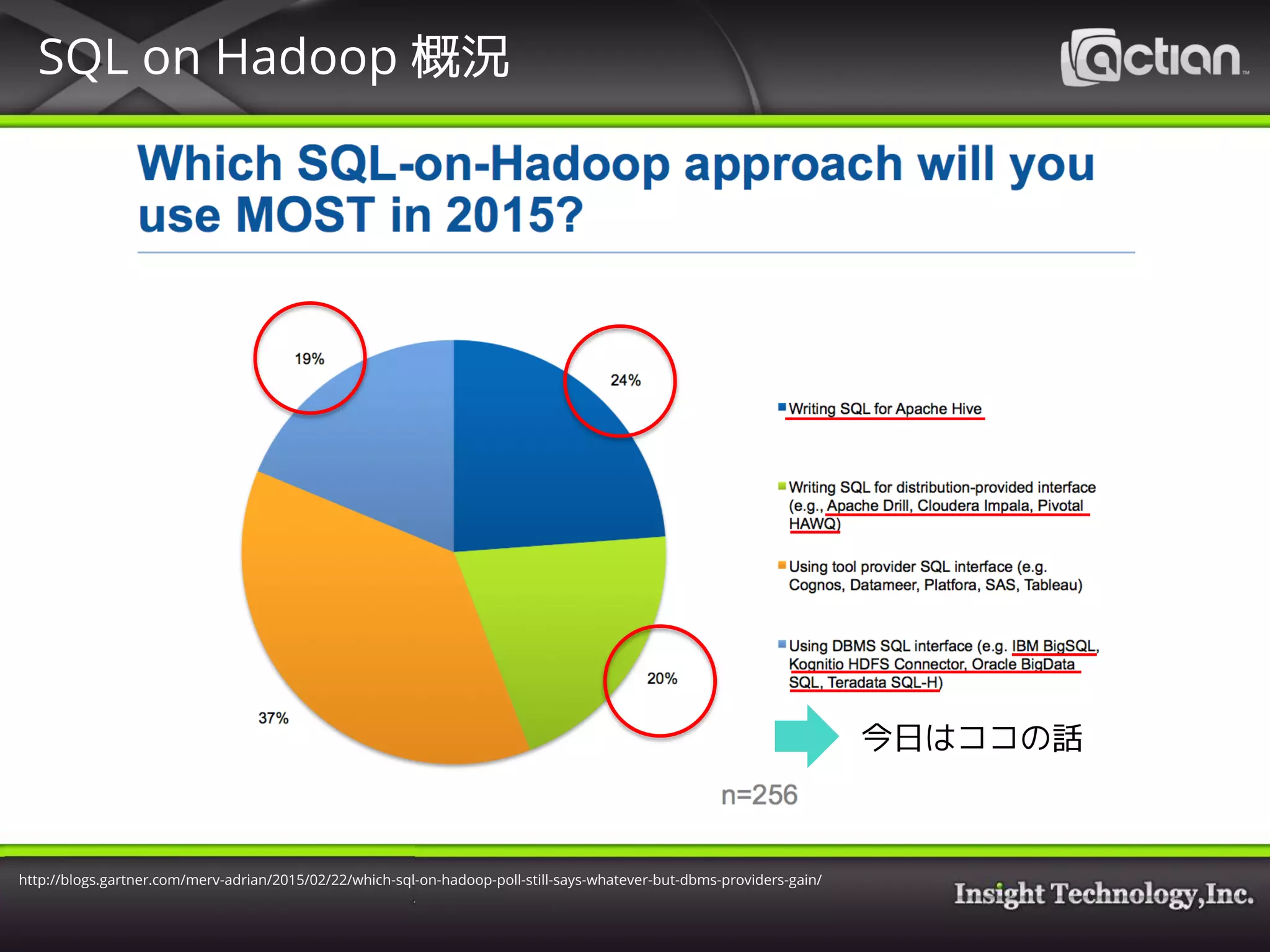
4. SQL on Hadoop 概況
http://blogs.gartner.com/merv-adrian/2015/02/22/which-sql-on-hadoop-poll-still-says-whatever-but-dbms-providers-gain/
今日はココの話
5. 6. Vector Hadoop SQL Editionの特徴
• HDFS上のデータを直接SQLでアクセス(Hadoop 2.0以降をサポート*1)
• 分散実行エンジンはMapReduceではなく独自実装
• VectorのパフォーマンスをHadoopクラスター上の全ノードで実現
• VectorでHDFSのスケーラビリティと高可用性を活用
• Vectorのカラムナー&圧縮フォーマットをそのままHDFS上で実現
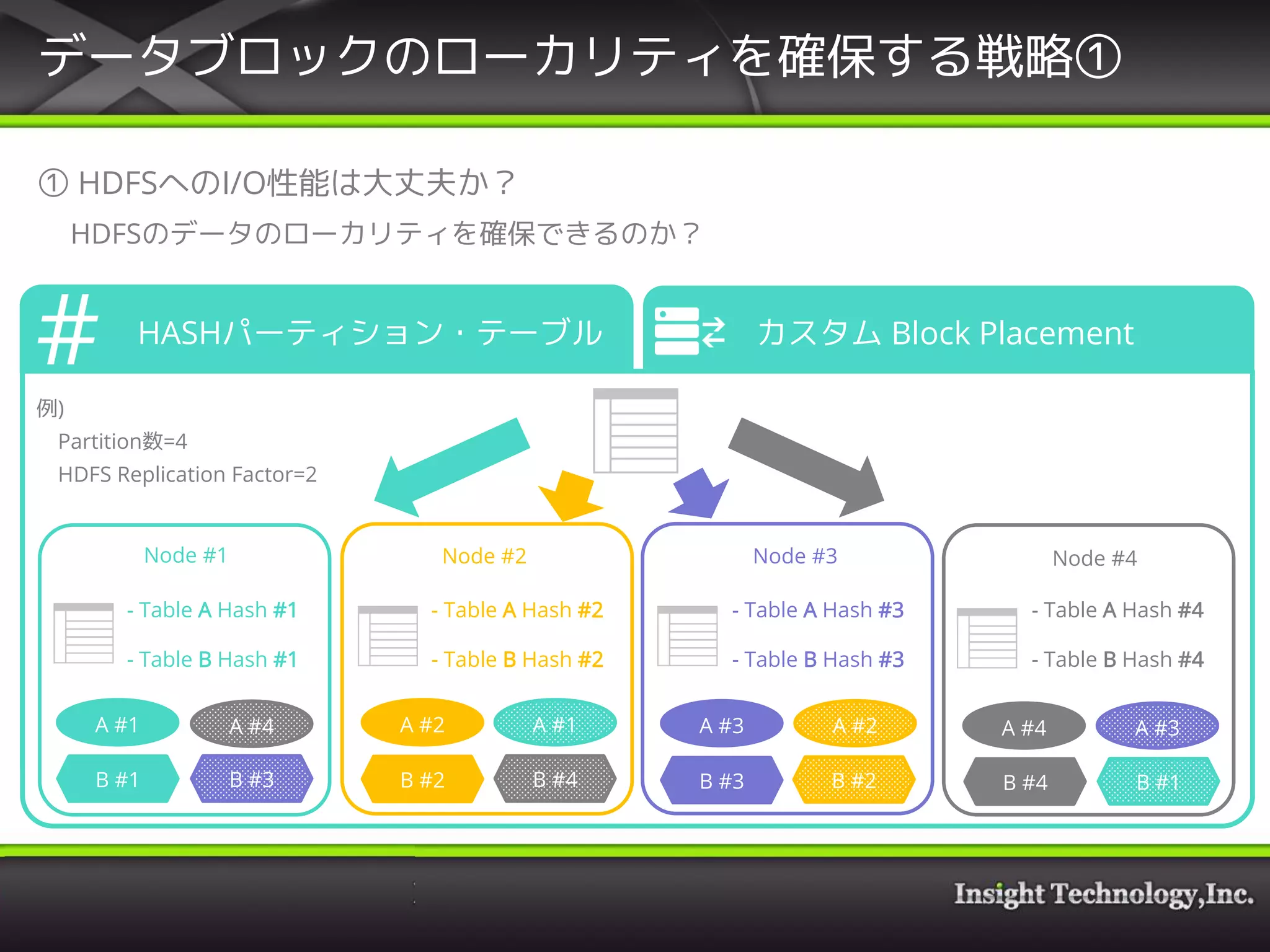
• データブロックのローカリティを確保する戦略
• 分析クエリーとACID対応の”更新可能”なDML文のサポート
• YARNによるリソースマネージメント
*1) MapRについてはMapR 4.0以降をサポート。ただし現バージョン(Vector Hadoop SQL Edition 4.1)
ではMapRのYARNには未対応
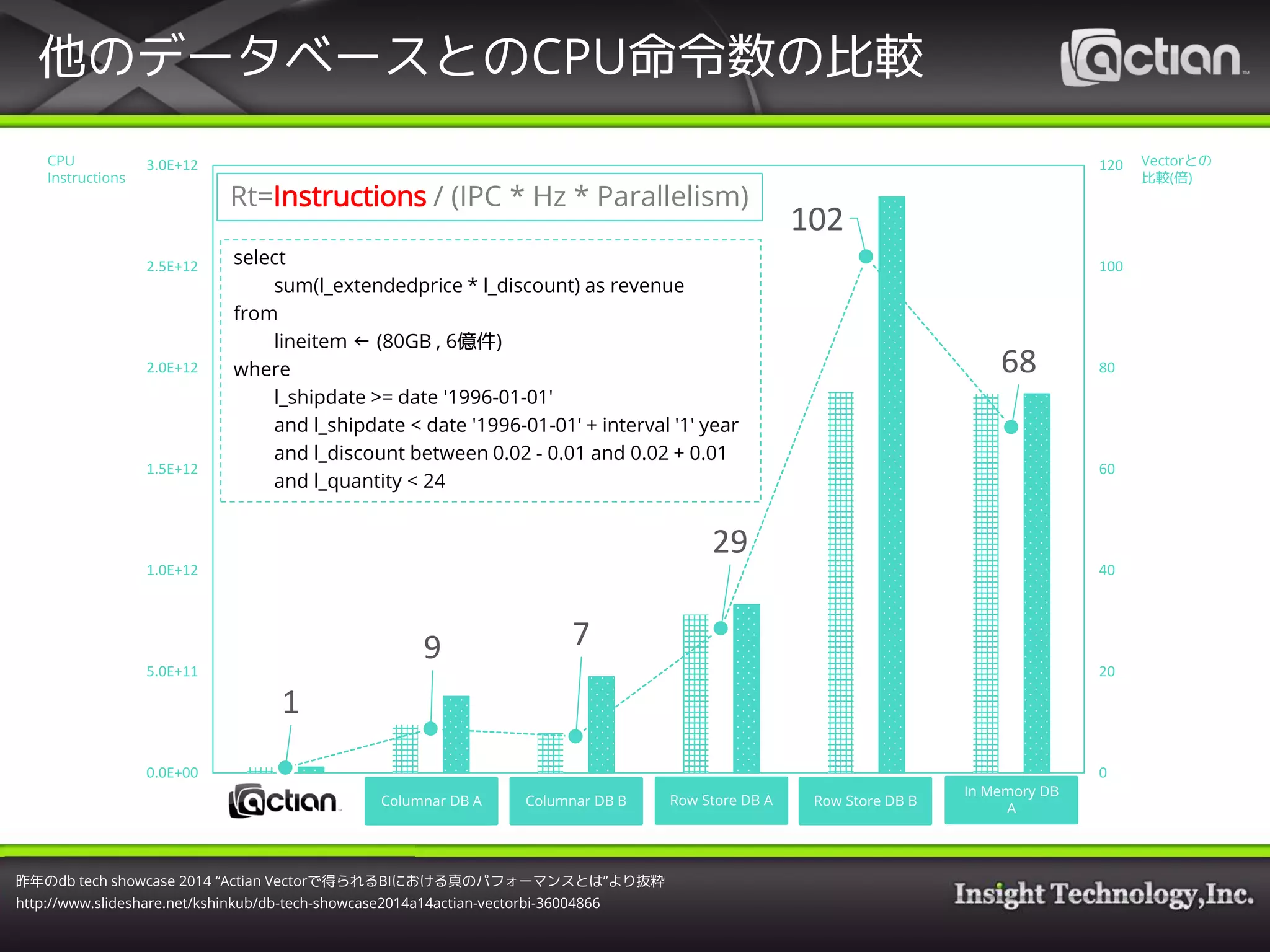
7. 8. 9. 他のデータベースとのCPU命令数の比較
1
9 7
29
102
68
0
20
40
60
80
100
120
0.0E+00
5.0E+11
1.0E+12
1.5E+12
2.0E+12
2.5E+12
3.0E+12
Columnar DB A Columnar DB B
In Memory DB
A
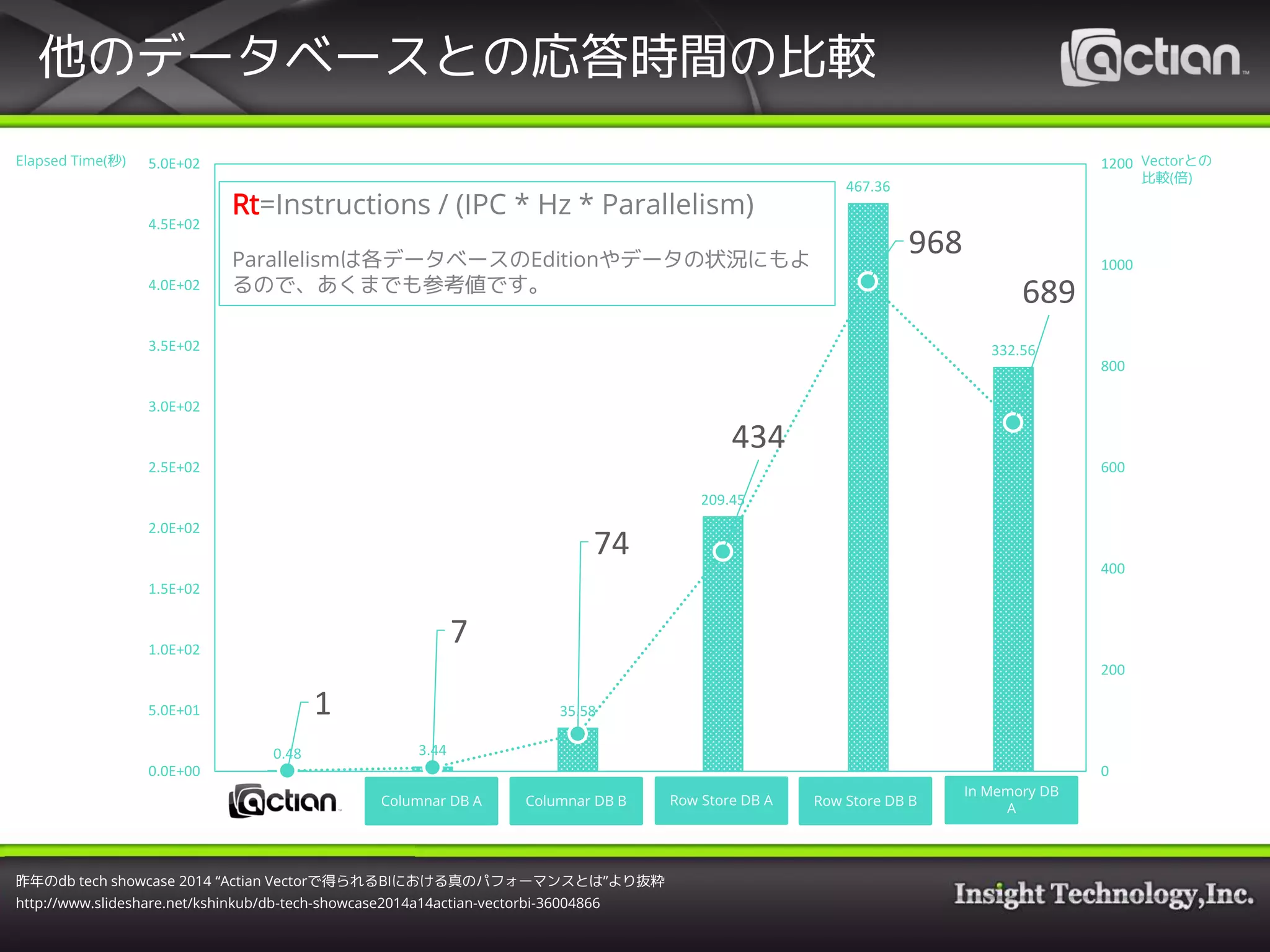
Rt=Instructions / (IPC * Hz * Parallelism)
Row Store DB A Row Store DB B
CPU
Instructions
Vectorとの
比較(倍)
昨年のdb tech showcase 2014 “Actian Vectorで得られるBIにおける真のパフォーマンスとは”より抜粋
http://www.slideshare.net/kshinkub/db-tech-showcase2014a14actian-vectorbi-36004866
select
sum(l_extendedprice * l_discount) as revenue
from
lineitem ← (80GB , 6億件)
where
l_shipdate >= date '1996-01-01'
and l_shipdate < date '1996-01-01' + interval '1' year
and l_discount between 0.02 - 0.01 and 0.02 + 0.01
and l_quantity < 24
10. 11. 12. Vector Hadoop SQL Editionの構成
HDFS
Name Node Data Node Data Node Data Node
YARN
SQL on
Hadoop
Engine
MapReduce Tez Spark … 3rd パーティー
HDFS
Name Node Data Node Data Node Data Node
YARN
3rd パーティー
Vector Hadoop SQL Editionの場合、YARNは必須ではない
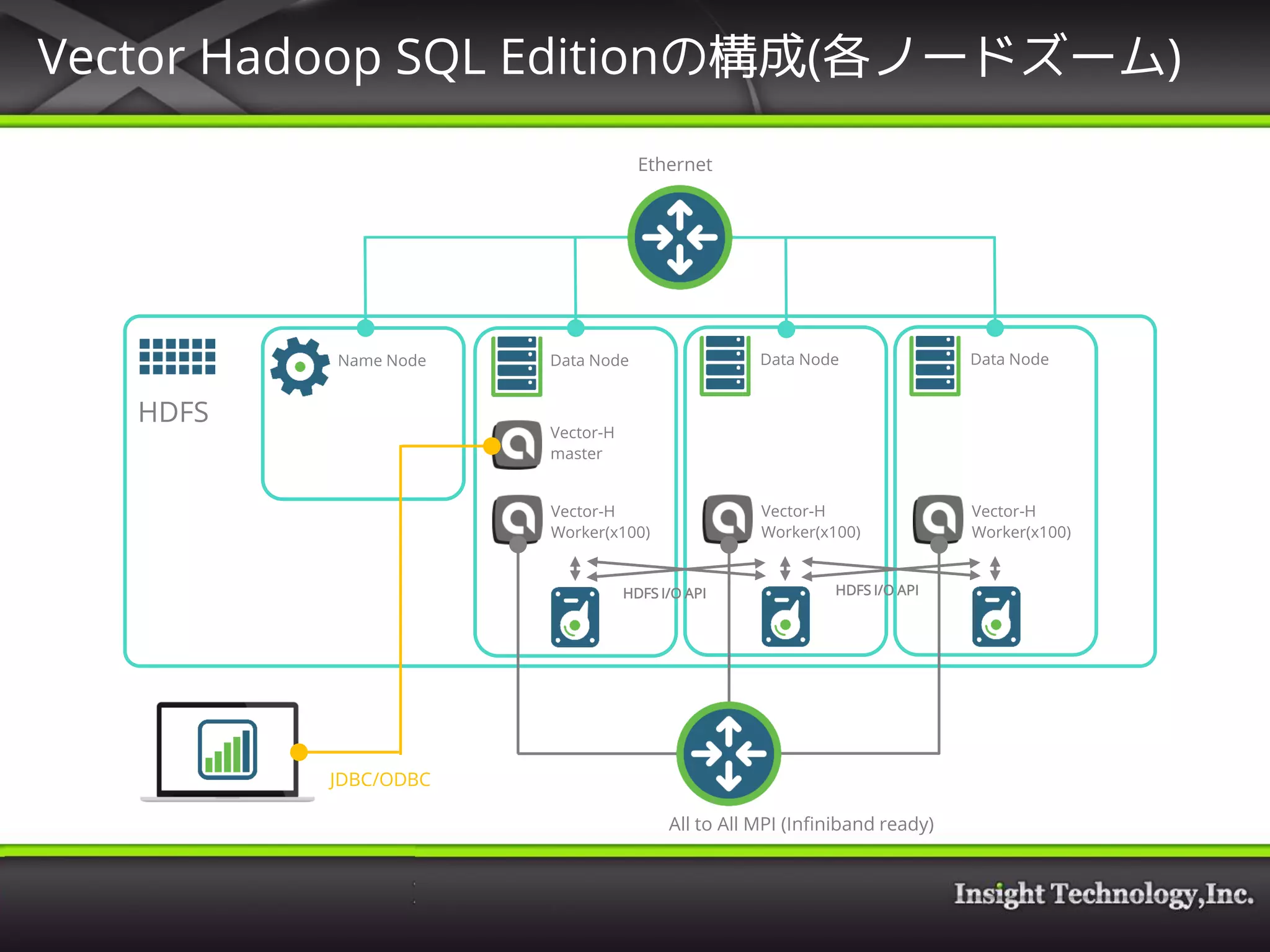
13. Vector Hadoop SQL Editionの構成(各ノードズーム)
HDFS
Name Node Data Node Data Node Data Node
Vector-H
master
Vector-H
Worker(x100)
Vector-H
Worker(x100)
Vector-H
Worker(x100)
HDFS I/O APIHDFS I/O API
JDBC/ODBC
All to All MPI (Infiniband ready)
Ethernet
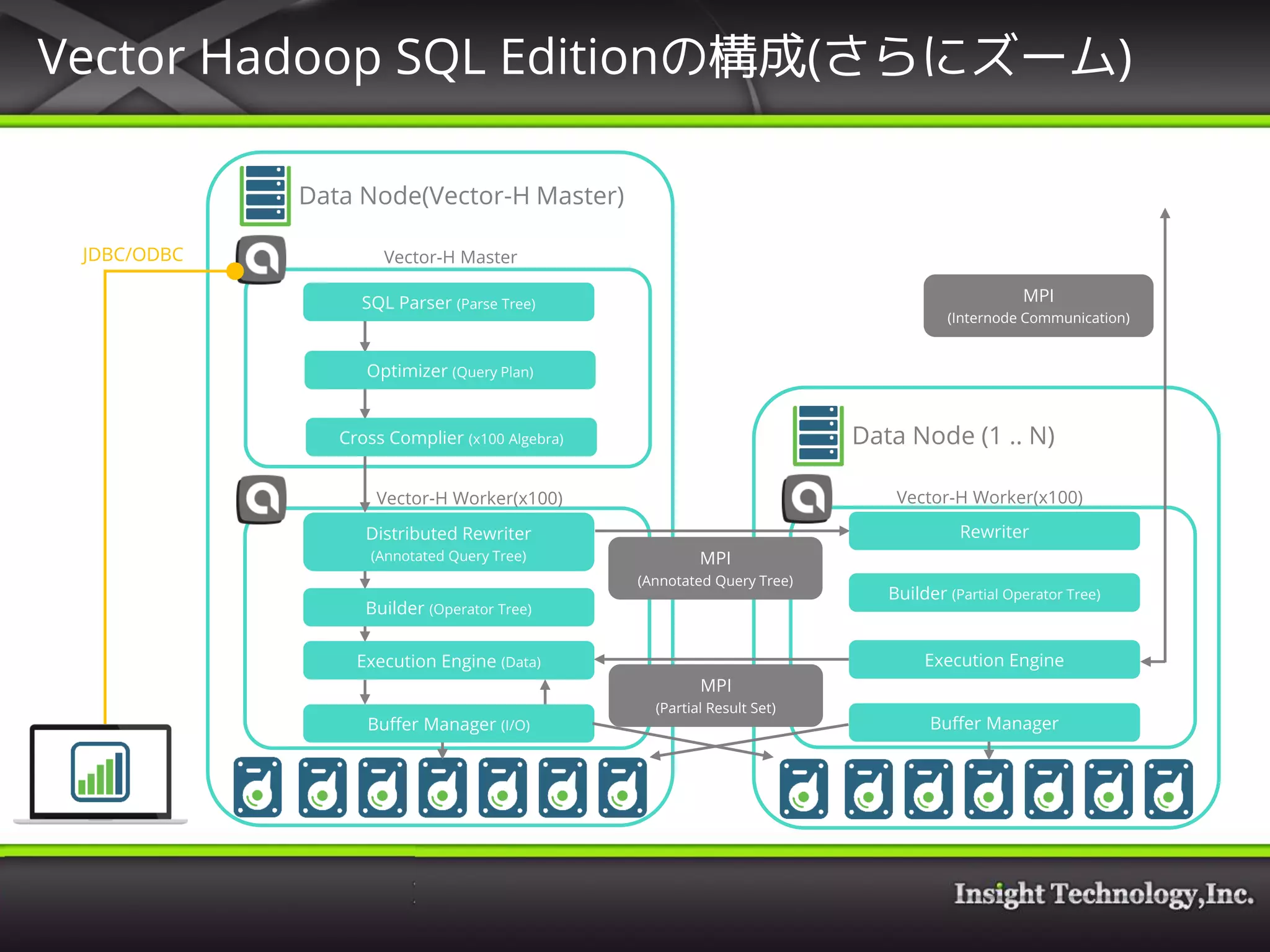
14. Vector Hadoop SQL Editionの構成(さらにズーム)
Data Node(Vector-H Master)
JDBC/ODBC
Data Node (1 .. N)
Vector-H Master
Vector-H Worker(x100) Vector-H Worker(x100)
SQL Parser (Parse Tree)
Optimizer (Query Plan)
Cross Complier (x100 Algebra)
Distributed Rewriter
(Annotated Query Tree)
Builder (Operator Tree)
Execution Engine (Data)
Rewriter
Builder (Partial Operator Tree)
Execution Engine
MPI
(Annotated Query Tree)
MPI
(Partial Result Set)
MPI
(Internode Communication)
Buffer Manager (I/O) Buffer Manager
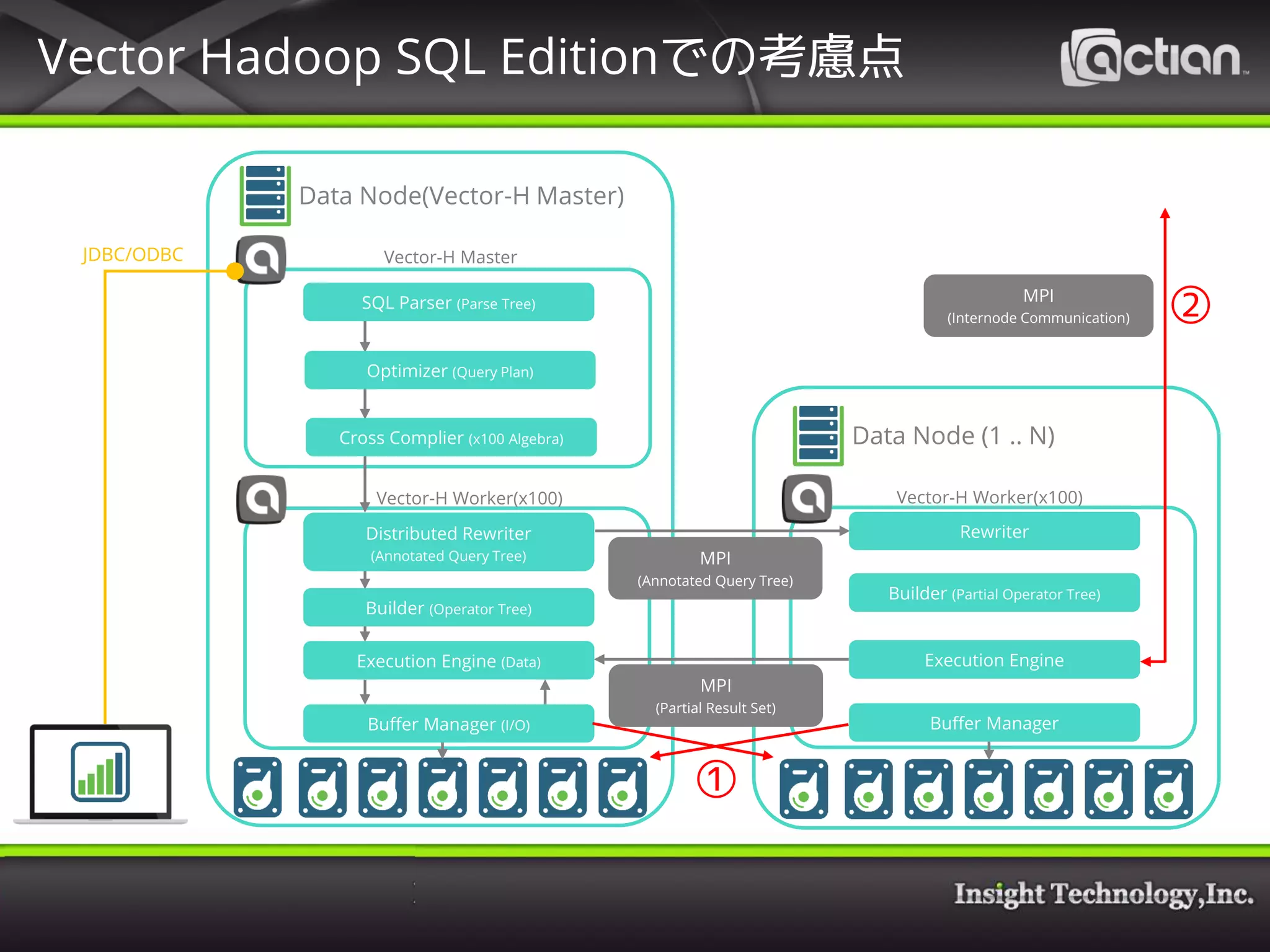
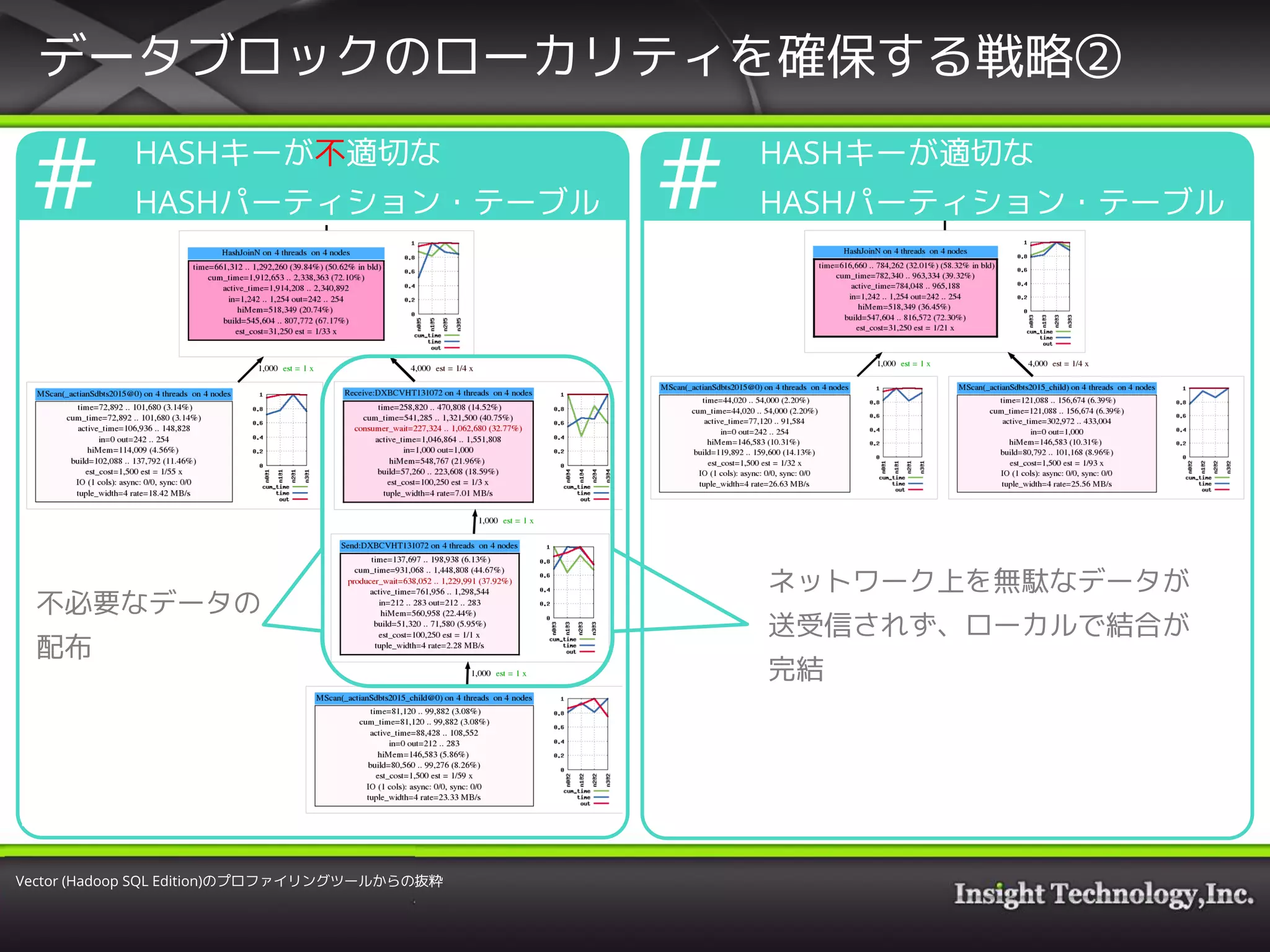
15. 16. Vector Hadoop SQL Editionのアーキテクチャー上、全ノードのCPUは非常に効
率良く使われるが、以下のポイントを考慮する必要がある。
① HDFSへのI/O性能は大丈夫か?
• HDFSのデータのローカリティを確保できるのか?
(I/Oがネットワーク越しになる可能性が高くパフォーマンスへのペナルティが大きい)
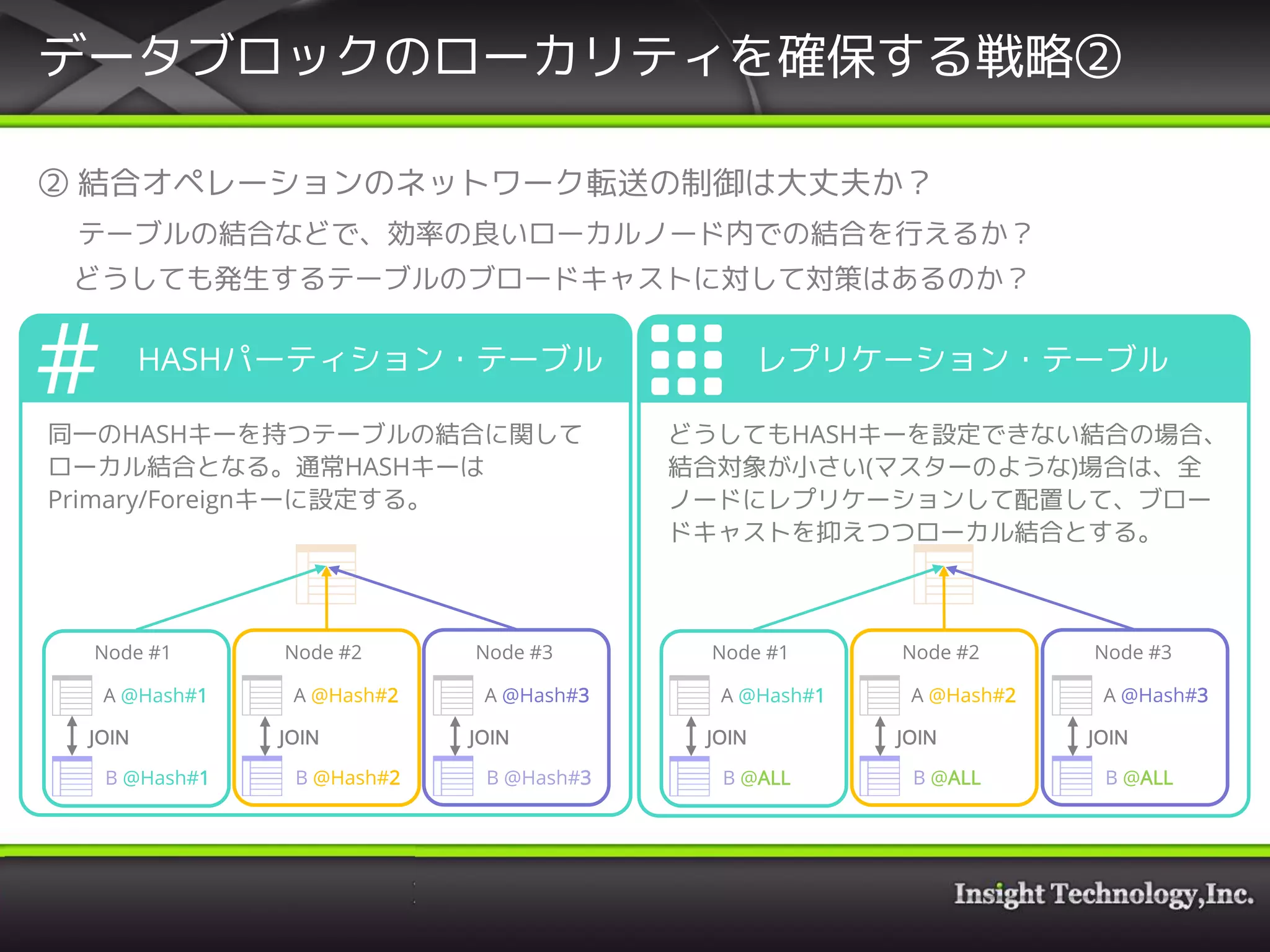
② 結合オペレーションのネットワーク転送の制御は大丈夫か?
• テーブルの結合などで、効率の良いローカルノード内での結合を行えるか?
• どうしても発生するテーブルのブロードキャストに対して対策はあるのか?
(どうしてもInternode Communicationが避けられない場合、MPI通信はNative InfiniBand
という奥の手もあるが…)
Vector Hadoop SQL Editionでの考慮点
YES
YES
17. Vector Hadoop SQL Editionでの考慮点
Data Node(Vector-H Master)
JDBC/ODBC
Data Node (1 .. N)
Vector-H Master
Vector-H Worker(x100) Vector-H Worker(x100)
SQL Parser (Parse Tree)
Optimizer (Query Plan)
Cross Complier (x100 Algebra)
Distributed Rewriter
(Annotated Query Tree)
Builder (Operator Tree)
Execution Engine (Data)
Rewriter
Builder (Partial Operator Tree)
Execution Engine
MPI
(Annotated Query Tree)
MPI
(Partial Result Set)
MPI
(Internode Communication)
Buffer Manager (I/O) Buffer Manager
①
②
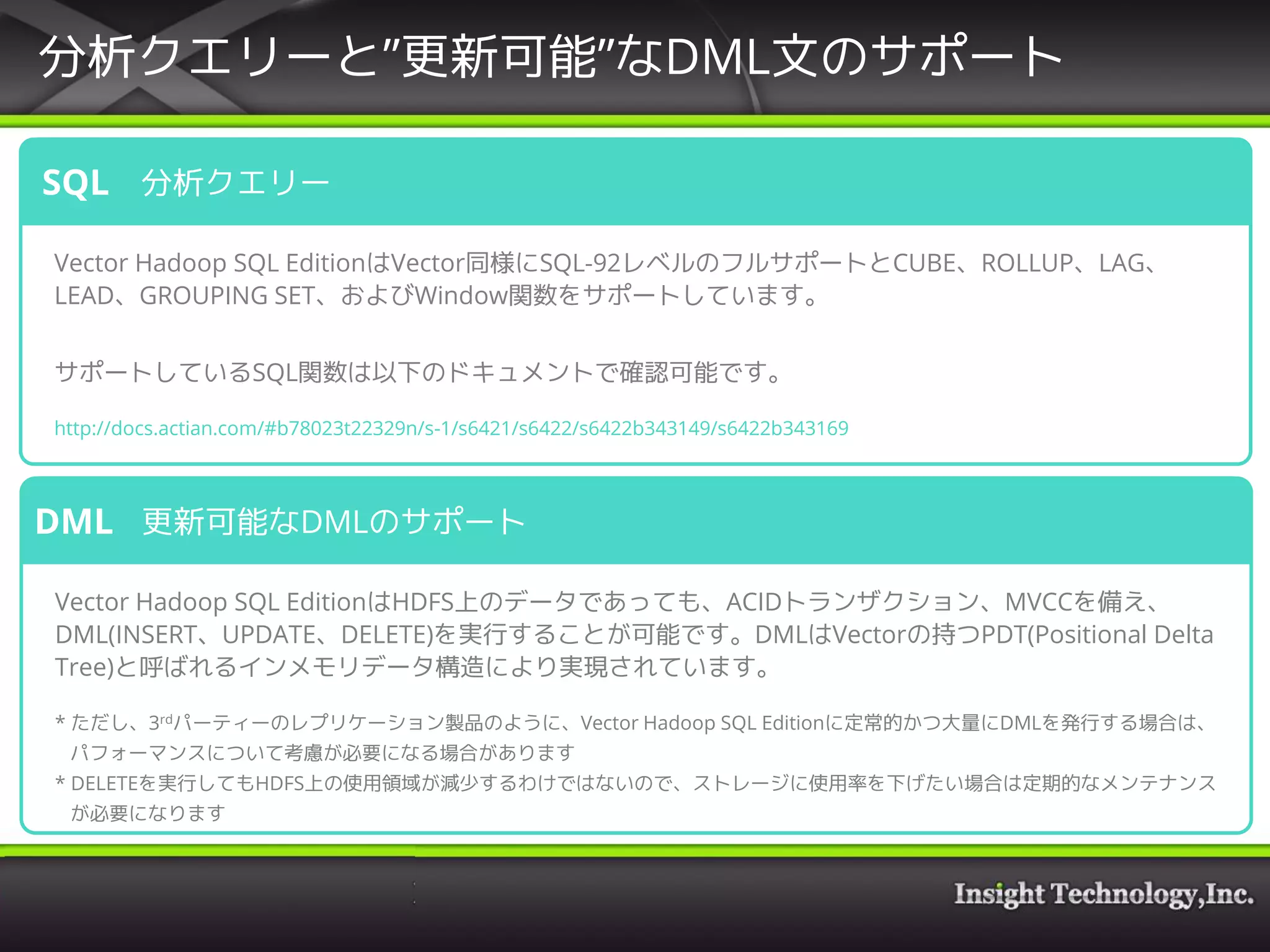
18. 19. 20. 21. 22. 23. 分析クエリーと”更新可能”なDML文のサポート
分析クエリー
Vector Hadoop SQL EditionはVector同様にSQL-92レベルのフルサポートとCUBE、ROLLUP、LAG、
LEAD、GROUPING SET、およびWindow関数をサポートしています。
サポートしているSQL関数は以下のドキュメントで確認可能です。
http://docs.actian.com/#b78023t22329n/s-1/s6421/s6422/s6422b343149/s6422b343169
SQL
更新可能なDMLのサポート
Vector Hadoop SQL EditionはHDFS上のデータであっても、ACIDトランザクション、MVCCを備え、
DML(INSERT、UPDATE、DELETE)を実行することが可能です。DMLはVectorの持つPDT(Positional Delta
Tree)と呼ばれるインメモリデータ構造により実現されています。
* ただし、3rdパーティーのレプリケーション製品のように、Vector Hadoop SQL Editionに定常的かつ大量にDMLを発行する場合は、
パフォーマンスについて考慮が必要になる場合があります
* DELETEを実行してもHDFS上の使用領域が減少するわけではないので、ストレージに使用率を下げたい場合は定期的なメンテナンス
が必要になります
DML
24. Positional Delta Tree(PDT)
Positional Delta Tree(PDT)の仕組み
Vectorの更新には、2つのタイプが存在します。
- BULK更新処理
- BATCH更新処理
BULK更新処理とはローダーにより一括データ投入や、
INSERT … SELECT * FROM xのような処理を意味します。
BATCH更新処理とは、一件ごとのINSERT、UPDATEや
DELETEを意味します。
BATCH処理の場合は、PDTと呼ばれるメモリー上のデータス
トアにて処理され、永続的なストレージ(この場合はHDFS上)
には、非同期で書き出されます。
HDFSは追記のみ可能ですので、Vectorも更新データは追記
のみ行い。追記時にマージ処理が行われます。
PDT
HDFS DATA LOG
READ
PDT
WRITE
PDT
① commit
② PDTと同時に
Transactionログに書
き出し
③ WRITE PDTのしき
い値によりREAD
PDTに移動
④ READ PDTのしき
い値によりHDFS上の
ファイルにマージ
読み取り時は、各
レイヤーをマージ
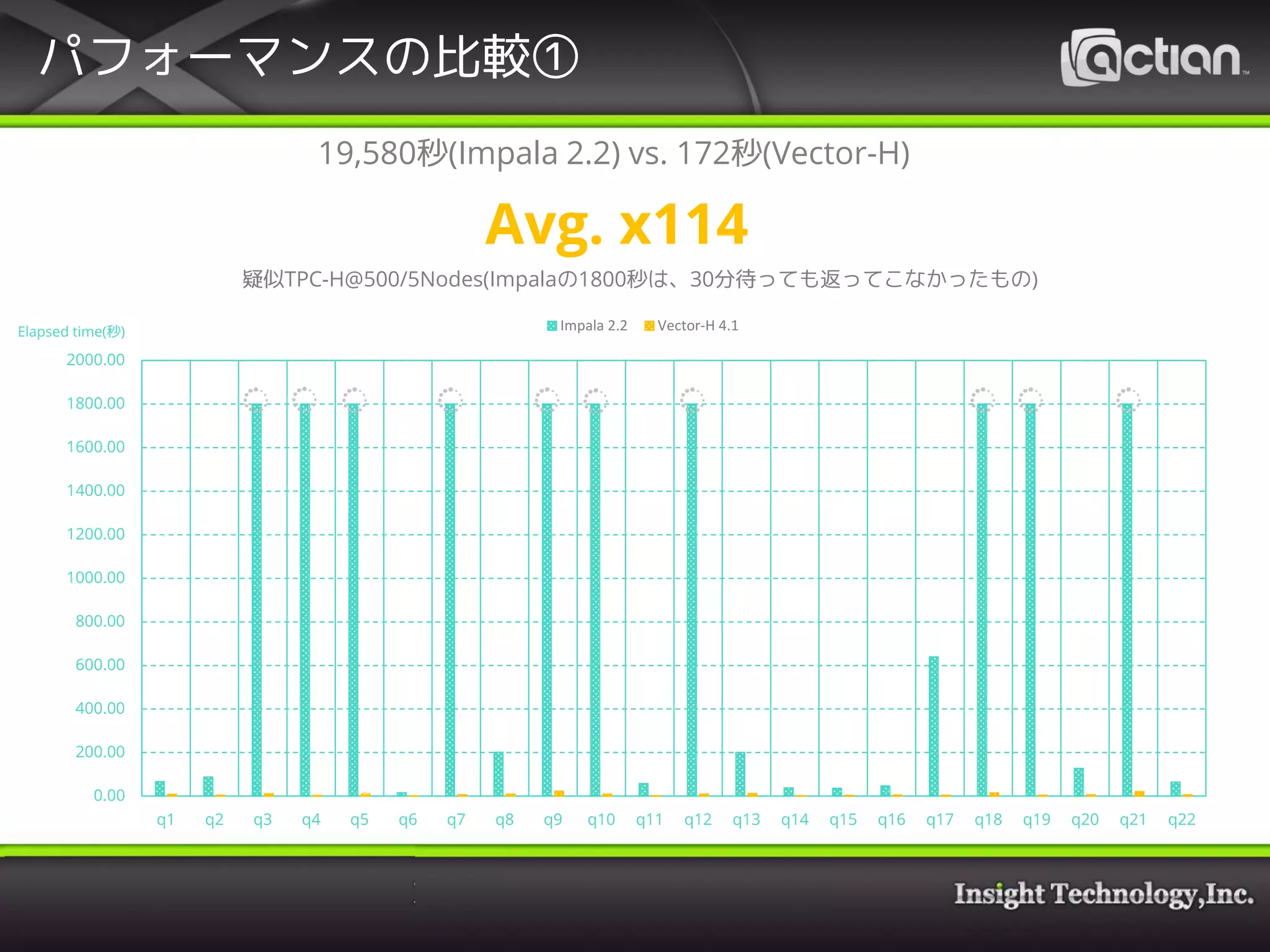
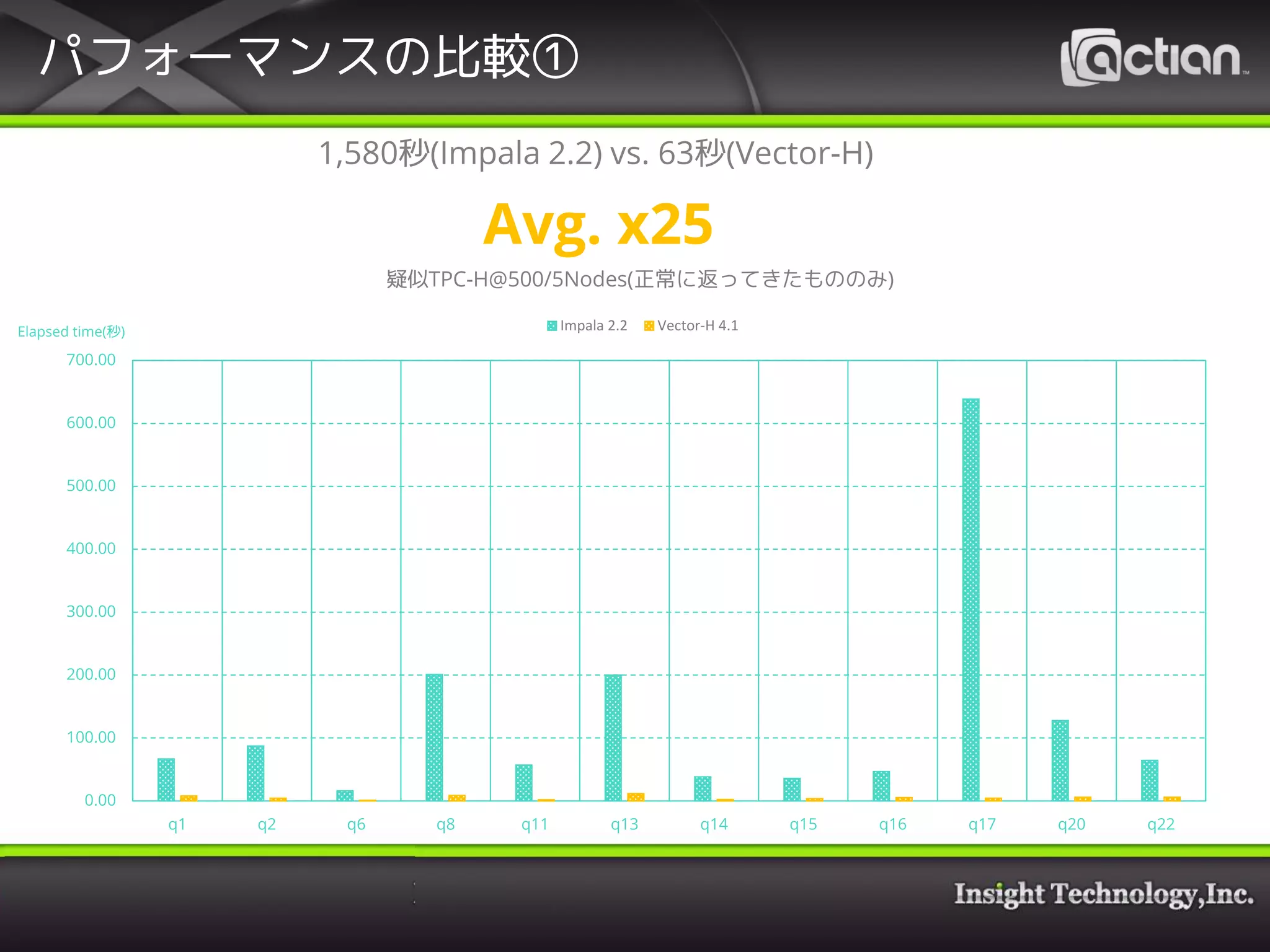
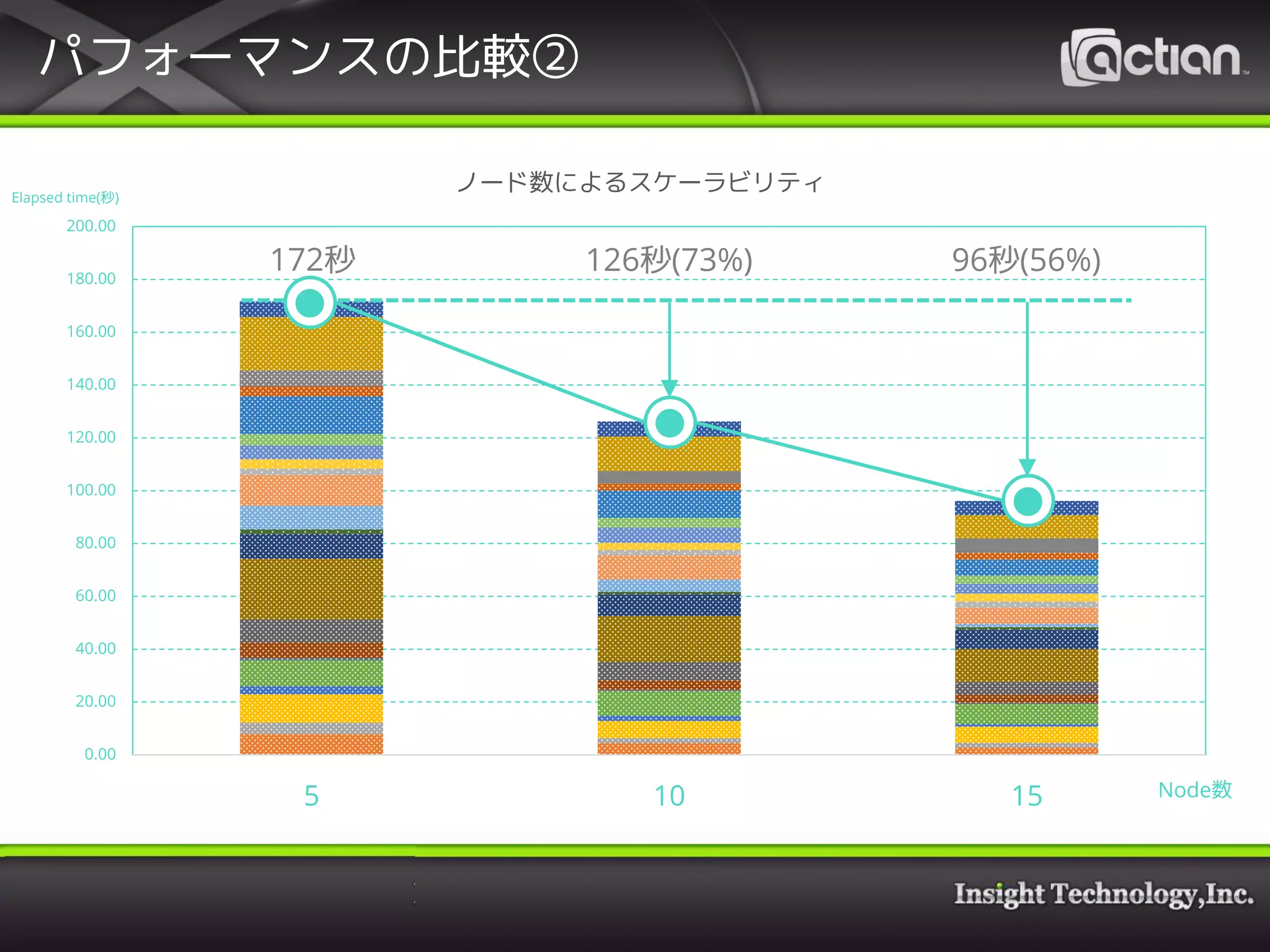
25. 26. 27. パフォーマンスの比較①
1,580秒(Impala 2.2) vs. 63秒(Vector-H)
Avg. x25
0.00
100.00
200.00
300.00
400.00
500.00
600.00
700.00
q1 q2 q6 q8 q11 q13 q14 q15 q16 q17 q20 q22
疑似TPC-H@500/5Nodes(正常に返ってきたもののみ)
Impala 2.2 Vector-H 4.1Elapsed time(秒)
28. 29. Vector Hadoop SQL Edition のロードマップ①
パフォーマンスの最適化
・さらなるクエリー速度の向上
・I/O効率の最適化(外部表)
DataFlowのより密な統合
外部表のサポート
YARNのより密な最適化
セキュリティの向上
Hadoop管理の統合
・ソート処理の効率化
・DataFlow処理の効率化
・DataFlowのロード処理の高速化
(現在のようなHDFS上への一時データ作成を廃止)
・Flat file(TEXT), SequenceFile, ORCFile or Parquet
フォーマットを外部表としてサポート
・YARNのリソース使用率の最適化
・動的なノードのバランシング(ノード障害時など)
・カラムレベルの暗号化(AES 128,192,256)
・クエリーレベルの監査
・デプロイ作業におけるAmbariとの統合
2015年 上半期 (Version 4.2)
30. Vector Hadoop SQL Edition のロードマップ②
ベンチマークの公表
・VectorおよびVector-HにてTPCベンチマークの公表
クラウドでの動作・管理
Vectorブロックフォーマット
の公開
ユーザー定義関数のサポート
セキュリティの向上
さらなるパフォーマンス向上
・Private Cloud(OpenStack & vCloud)への最適化
(合わせてPublic Cloudへの最適化も予定 – Phase2)
・直接Vectorのデータファイルにアクセス可能なAPIを
提供予定(Phase1->Read, Phase2 -> Read/Write)
・Phase1としてSpark
・Phase2としてMatrixのようなC++
・粒度を指定可能な監査(例 ユーザー別、テーブル別)
・Hadoopのセキュリティ(Knox, Sentry)の統合
・パフォーマンスの継続的な向上
・同時実行性の継続的な向上
2015年 下半期
TPC UDF
31. EMR上でVector-Hをインストールする際のTips
- sshの設定を変更
- Vector Hadoop SQL Editionでは、Workerの自動インストール時にsshを使用します。
- その際、パスワード認証のみですので、sshd_configをパスワード認証可能に設定しておいてください。
- また、sshd_configでrootユーザーのssh接続(パスワード認証)を有効にしておいてください。
- rootのパスワードを設定すべし
- 上記のssh接続(WorkerノードでOSユーザーの作成等)のために、rootのパスワードを設定しておいてください。
- EMRの場合、Installerの自動並列度は1になってしまうので、手動で変えるべし
- Installerではほぼ、デフォルトで問題ないですが、EMRの場合max_parallelismの値が1と取得されるため、
手動で、Install画面で、インスタンス内のコア数を入れるようにしてください。
- YARN enableでインストールした場合は、以下のパーミッションを変えるべし
- YARNをenable(デフォルト:disable)に設定した際は以下のディレクトリに起動ユーザーで書き込み権限が必要です。
/mnt/var/lib/hadoop/tmp 、 /mnt/var/em/raw
- 言い忘れましたが…
- EMRは、Actian社の推奨Hadoopディストリビューションには入っていません!
(どうしても、EMRでの正式な動作保障を確認したい場合は、弊社までご連絡ください!)
32. 33. セミナーの紹介
2015年6月30日 14:00 – 17:30
@EBiS 303カンファレンスルーム(恵比寿)
参加費: 無料
URL: http://www.insight-tec.com/events-seminars/20150630_bpa.html
プログラム
[キーノート] ビッグデータプロジェクトを加速させるための仕組みと運用
-米国の最新フレームワーク動向とデータアドミニストレータの役割の変化-
特定非営利活動法人ヘルスケアクラウド研究会理事 博士(医薬学) 笹原英司様
[ユーザ事例] 1000万人規模の医療ビッグデータ活用までの道のり
メディカル・データ・ビジョン株式会社 EBM事業部長 中村正樹様
データ分析に最適な基盤とは?
-コスト/スピードでビジネスバリューを得るために-
株式会社インサイトテクノロジー CTO 石川雅也
BigData Project Accelerator
医療業界の最先端事例から学ぶプロジェクトを加速させる要因
2015年6月30日(火) 14:00 – 17:30
@ EBiS303 カンファレンスルーム (in 恵比寿)
お申込みはお手元のアンケートで!
34.


















![セミナーの紹介
2015年6月30日 14:00 – 17:30
@EBiS 303カンファレンスルーム(恵比寿)
参加費: 無料
URL: http://www.insight-tec.com/events-seminars/20150630_bpa.html
プログラム
[キーノート] ビッグデータプロジェクトを加速させるための仕組みと運用
-米国の最新フレームワーク動向とデータアドミニストレータの役割の変化-
特定非営利活動法人ヘルスケアクラウド研究会理事 博士(医薬学) 笹原英司様
[ユーザ事例] 1000万人規模の医療ビッグデータ活用までの道のり
メディカル・データ・ビジョン株式会社 EBM事業部長 中村正樹様
データ分析に最適な基盤とは?
-コスト/スピードでビジネスバリューを得るために-
株式会社インサイトテクノロジー CTO 石川雅也
BigData Project Accelerator
医療業界の最先端事例から学ぶプロジェクトを加速させる要因
2015年6月30日(火) 14:00 – 17:30
@ EBiS303 カンファレンスルーム (in 恵比寿)
お申込みはお手元のアンケートで!](https://image.slidesharecdn.com/dbts2015tokyovectorinhadoopvortex-150611093207-lva1-app6891/75/Dbts2015-tokyo-vector_in_hadoop_vortex-33-2048.jpg)

![[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d16verticahp-150619081330-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c15mysqlkakaku-150618053752-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b24nonstop-sqlhp-150619075240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D35:高トランザクションを実現するスケーラブルRDBMS技術 by 日本電気株式会社 並木悠太](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d35infoframe-relational-storenec-150616022508-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a32amazon-redshiftamazondataservicejapan-150623010123-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B17:PostgreSQLで動的にスケールアウト可能な負荷分散DBクラスタを作ろう! by ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b17postgresqlsraoss-150616021919-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告](https://cdn.slidesharecdn.com/ss_thumbnails/20140117rdsforpgsqlbenchreport-140216194106-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d21hppostgresplusadvancedserverv9-141120232610-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015e26couchbaseandjbossdatavirtualization-150616073132-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2014] L34: そのデータベース 5年後大丈夫ですか by 日本ヒューレット・パッカード株式会社 後藤宏](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l34hp5-141120233511-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] A12:DBAが知っておくべき最新テクノロジー: フラッシュ, ストレージ, クラウド b...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015a12oraclesqlserverinsighttechnology-150918013852-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E34: データベース・サービスを好きなところで動かそう Db2 Warehouse by 日...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017e34-170911070313-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2017] B14: 4年連続No.1リーダー評価のストレージでDBクローンするとどんな感じ?瞬時のクロー...](https://cdn.slidesharecdn.com/ss_thumbnails/20180905oracleonpurebackuprecoveryv1-170912014552-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...](https://cdn.slidesharecdn.com/ss_thumbnails/b37dbtechshowcasetokyo2015haclusteringsoftware20150612-150611165311-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c25hpfacebook-141120232027-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d13hardwareflashhgst-150629025827-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d32in-memorysap-hanahp-150619092635-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A33:Amazon DynamoDB Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a33amazon-dynamodbamazondataservicejapan-150623010315-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D33:Superdome X 上の SQL Server 2014 OLTP 検証結果と S...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d33sql-servermicrosoft-150619092854-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E27: Neo4jグラフデータベース by クリエーションライン株式会社 李昌桓](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e27neo4jcreationline-150623051314-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c27mysqlrakuten-150617022225-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C32:「データ一貫性にこだわる日立のインメモリ分散KVS~こだわりの理由と実現方法とは~」 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c32kvshitachi-150619110419-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C33:ビッグデータ・IoT時代のキーテクノロジー、CEPの「今」を掴む! by 株式会社日立...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c33bigdatahitachi-150619110610-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E15:Hadoop大量データ処理技術と日立匿名化技術によるプライバシー保護とデータ活用 by...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015e15hadoophitachi-solutions-150721062250-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] C14:30万のユーザ部門を抱える日立、情シスの「理想と現実」 by 株式会社日立製作所 情報...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c14it-infrastructurehitachi-150619110309-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B27:インメモリーDBとスケールアップマシンによりBig Dataの課題を解決する by S...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b27sap-hanasap-japan-150618080033-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D23:MySQLはドキュメントデータベースになり、HTTPもしゃべる - MySQL Lab...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d23mysqloracle-mysqlgbu-150619101210-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] C25:HP NonStop SQLはなぜグローバルに分散DBを構築できるのか、 データの整合...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c25nonstop-sqlhp-150619092435-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう](https://cdn.slidesharecdn.com/ss_thumbnails/e35cassandra-150624022814-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D25:The difference between logical and physical...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d25oracledbvisit-software-150619090737-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Japan Tech summit 2017] DAL 002](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfdal002-171115033147-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db analytics showcase Sapporo 2018] B25 Hadoop上で動く世界最速のAnalytic DBをSparkと一緒に...](https://cdn.slidesharecdn.com/ss_thumbnails/dbassapporo2018b25-180628051851-thumbnail.jpg?width=640&height=640&fit=bounds)

















