Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Hiroaki Kubota
2,029 views
Db tech showcase2015 how to replicate between clusters
話す前提だから、コレだけ見ても伝わらないだろうな・・・
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Downloaded 10 times
1
/ 41
2
/ 41
3
/ 41
4
/ 41
5
/ 41
6
/ 41
7
/ 41
8
/ 41
9
/ 41
10
/ 41
11
/ 41
12
/ 41
13
/ 41
14
/ 41
15
/ 41
16
/ 41
17
/ 41
18
/ 41
19
/ 41
20
/ 41
21
/ 41
22
/ 41
23
/ 41
24
/ 41
25
/ 41
26
/ 41
27
/ 41
28
/ 41
29
/ 41
30
/ 41
31
/ 41
32
/ 41
33
/ 41
34
/ 41
35
/ 41
36
/ 41
37
/ 41
38
/ 41
39
/ 41
40
/ 41
41
/ 41
More Related Content
PDF
DB tech showcase: 噂のMongoDBその用途は?
by
Hiroaki Kubota
PDF
初めてのMongo db
by
Ryuji Tamagawa
PDF
RDB経験者に送るMongoDBの勘所(db tech showcase tokyo 2013)
by
Ryuji Tamagawa
PDF
MongoDB〜その性質と利用場面〜
by
Naruhiko Ogasawara
PPTX
Mongo dbを知ろう
by
CROOZ, inc.
PDF
Introduction to MongoDB
by
moai kids
PPTX
Mongo db勉強会の補足
by
CROOZ, inc.
PDF
MongoDBざっくり解説
by
知教 本間
DB tech showcase: 噂のMongoDBその用途は?
by
Hiroaki Kubota
初めてのMongo db
by
Ryuji Tamagawa
RDB経験者に送るMongoDBの勘所(db tech showcase tokyo 2013)
by
Ryuji Tamagawa
MongoDB〜その性質と利用場面〜
by
Naruhiko Ogasawara
Mongo dbを知ろう
by
CROOZ, inc.
Introduction to MongoDB
by
moai kids
Mongo db勉強会の補足
by
CROOZ, inc.
MongoDBざっくり解説
by
知教 本間
What's hot
PPTX
がっつりMongoDB事例紹介
by
Tetsutaro Watanabe
PPTX
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
PPT
MongoDB
by
あしたのオープンソース研究所
PDF
データベース勉強会 In 広島 mongodb
by
Ryuji Tamagawa
PPTX
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
PPTX
MongoDB World 2014に行ってきた!
by
Tetsutaro Watanabe
PDF
後悔しないもんごもんごの使い方 〜アプリ編〜
by
Masakazu Matsushita
PPTX
MongoDBの監視
by
Tetsutaro Watanabe
PDF
WiredTigerストレージエンジン楽しい
by
Akihiro Kuwano
PDF
Case study to use MongoDB in middle-class SIer / (中規模) SIerだってMongoDBできたよ!
by
Naruhiko Ogasawara
PPT
ザ・ドキュメント~うまくいかないNoSQL~
by
Akihiro Kuwano
PPTX
日本語:Mongo dbに於けるシャーディングについて
by
ippei_suzuki
PDF
MongoDB very basic (Japanese) / MongoDB基礎の基礎
by
Naruhiko Ogasawara
ODP
Mongo dbを半年ちょっと運用してみた
by
htty_hasumi
PPTX
MongoDB on EC2 #mongodbcasual
by
Yasuhiro Matsuo
PDF
ソーシャルゲームにおけるMongoDB適用事例 - Animal Land
by
Masakazu Matsushita
PPTX
MongoDB3.2の紹介
by
Tetsutaro Watanabe
PDF
MongoDBではじめるカジュアルなタイムラインシステム
by
Hitoshi Asai
PPTX
Node.js×mongo dbで3年間サービス運用してみた話
by
leverages_event
PDF
NoSQLデータベースと位置情報
by
Koji Ichiwaki
がっつりMongoDB事例紹介
by
Tetsutaro Watanabe
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
MongoDB
by
あしたのオープンソース研究所
データベース勉強会 In 広島 mongodb
by
Ryuji Tamagawa
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
MongoDB World 2014に行ってきた!
by
Tetsutaro Watanabe
後悔しないもんごもんごの使い方 〜アプリ編〜
by
Masakazu Matsushita
MongoDBの監視
by
Tetsutaro Watanabe
WiredTigerストレージエンジン楽しい
by
Akihiro Kuwano
Case study to use MongoDB in middle-class SIer / (中規模) SIerだってMongoDBできたよ!
by
Naruhiko Ogasawara
ザ・ドキュメント~うまくいかないNoSQL~
by
Akihiro Kuwano
日本語:Mongo dbに於けるシャーディングについて
by
ippei_suzuki
MongoDB very basic (Japanese) / MongoDB基礎の基礎
by
Naruhiko Ogasawara
Mongo dbを半年ちょっと運用してみた
by
htty_hasumi
MongoDB on EC2 #mongodbcasual
by
Yasuhiro Matsuo
ソーシャルゲームにおけるMongoDB適用事例 - Animal Land
by
Masakazu Matsushita
MongoDB3.2の紹介
by
Tetsutaro Watanabe
MongoDBではじめるカジュアルなタイムラインシステム
by
Hitoshi Asai
Node.js×mongo dbで3年間サービス運用してみた話
by
leverages_event
NoSQLデータベースと位置情報
by
Koji Ichiwaki
Viewers also liked
PPT
Pharmacy Assistants
by
browncowdesign
PPTX
My Favorite Movie
by
cecil52
PPTX
Cordovaコトハジメ( Html5fun×senchUG )
by
Masayuki Abe
PDF
Office and Retail Projects
by
imolnar72
PDF
Services & Products of Optimal Management
by
Andrey Sukhobokov
PPT
Education Focus Area
by
serviceresources
PPTX
My life project
by
yessicavd
PPT
Copyright crash course part 3
by
gsalas10
PPT
Copyright crash course part 5
by
gsalas10
XLS
Ejercicios 2
by
joslis12
PPT
Heroku shdh
by
Sandra_Daniela
PPTX
Nlbelgrade415
by
lpendse
PPTX
CNCS VOI Methodology Overview
by
serviceresources
PPT
Copyright crash course part 2
by
gsalas10
PDF
การติดตั้ง appserv และ การติดตั้ง wordpress บน appserv
by
Chahoemsid Hutacharoen
PPT
презентация элективного курса по биологии
by
loksal
PPTX
Bucerias
by
Galaxsaviajes
PPT
Hist 141 panama & los angeles
by
flip7rider
PPT
Subject pronouns and present simple be
by
teacherhector
PPTX
Onco Care Pharmaceuticals
by
Hamza Khan
Pharmacy Assistants
by
browncowdesign
My Favorite Movie
by
cecil52
Cordovaコトハジメ( Html5fun×senchUG )
by
Masayuki Abe
Office and Retail Projects
by
imolnar72
Services & Products of Optimal Management
by
Andrey Sukhobokov
Education Focus Area
by
serviceresources
My life project
by
yessicavd
Copyright crash course part 3
by
gsalas10
Copyright crash course part 5
by
gsalas10
Ejercicios 2
by
joslis12
Heroku shdh
by
Sandra_Daniela
Nlbelgrade415
by
lpendse
CNCS VOI Methodology Overview
by
serviceresources
Copyright crash course part 2
by
gsalas10
การติดตั้ง appserv และ การติดตั้ง wordpress บน appserv
by
Chahoemsid Hutacharoen
презентация элективного курса по биологии
by
loksal
Bucerias
by
Galaxsaviajes
Hist 141 panama & los angeles
by
flip7rider
Subject pronouns and present simple be
by
teacherhector
Onco Care Pharmaceuticals
by
Hamza Khan
Similar to Db tech showcase2015 how to replicate between clusters
PDF
MongoDBのアレをアレする
by
Akihiro Kuwano
PDF
CasualなMongoDBのサービス運用Tips
by
Naoki Sega
PDF
[MongoDB勉強会 in 2017] MongoDB on AWS
by
Shuji Kikuchi
PDF
Developers.IO 2017 MongoDB on AWS Advance
by
Shuji Kikuchi
PDF
大規模化するピグライフを支えるインフラ ~MongoDBとChefについて~ (前編)
by
Akihiro Kuwano
PDF
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
PDF
CyberAgentにおけるMongoDB
by
Akihiro Kuwano
DOC
20110301 Mongo Tokyo
by
Kenichi Masuda
DOC
20110302 Mongo Tokyo
by
Kenichi Masuda
PDF
Mongodb 紹介
by
Ryo Matsumura
PPTX
PHPとMongoDBで学ぶ次世代データストア
by
Takuya Sato
MongoDBのアレをアレする
by
Akihiro Kuwano
CasualなMongoDBのサービス運用Tips
by
Naoki Sega
[MongoDB勉強会 in 2017] MongoDB on AWS
by
Shuji Kikuchi
Developers.IO 2017 MongoDB on AWS Advance
by
Shuji Kikuchi
大規模化するピグライフを支えるインフラ ~MongoDBとChefについて~ (前編)
by
Akihiro Kuwano
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
CyberAgentにおけるMongoDB
by
Akihiro Kuwano
20110301 Mongo Tokyo
by
Kenichi Masuda
20110302 Mongo Tokyo
by
Kenichi Masuda
Mongodb 紹介
by
Ryo Matsumura
PHPとMongoDBで学ぶ次世代データストア
by
Takuya Sato
More from Hiroaki Kubota
PDF
MongoDBで自然言語処理
by
Hiroaki Kubota
PDF
MongoDBJP 納涼もんご祭り
by
Hiroaki Kubota
PDF
Why mincore() returns different value of stat ?
by
Hiroaki Kubota
PDF
Mongo ghostsync and slaveDelay (Japanease)
by
Hiroaki Kubota
PDF
Mongo ghostsync and slaveDelay
by
Hiroaki Kubota
PDF
C10K on Mongo's sharding
by
Hiroaki Kubota
PPT
Cockatoo
by
Hiroaki Kubota
PPT
MongoTokyo
by
Hiroaki Kubota
PPT
Albatross
by
Hiroaki Kubota
MongoDBで自然言語処理
by
Hiroaki Kubota
MongoDBJP 納涼もんご祭り
by
Hiroaki Kubota
Why mincore() returns different value of stat ?
by
Hiroaki Kubota
Mongo ghostsync and slaveDelay (Japanease)
by
Hiroaki Kubota
Mongo ghostsync and slaveDelay
by
Hiroaki Kubota
C10K on Mongo's sharding
by
Hiroaki Kubota
Cockatoo
by
Hiroaki Kubota
MongoTokyo
by
Hiroaki Kubota
Albatross
by
Hiroaki Kubota
Db tech showcase2015 how to replicate between clusters
1.
MongoDB クラスター間レプリケーション MongoDB JP代表 窪田 博昭
@crumbjp
2.
Who are you
? MongoDBJP 代表 MongoDB歴4年 emin.co.jp 2014年10月∼
3.
ブログ活動
4.
仕事の話
7.
Emotion Intelligence 日本有数のMongoDBユーザ企業 ECのCV率を上げるサービスZenclerkを運営 Web閲覧中のユーザの行動を逐次解析し感情 を読み取る 月間10億PV程度を扱っている
8.
Zenclerk
9.
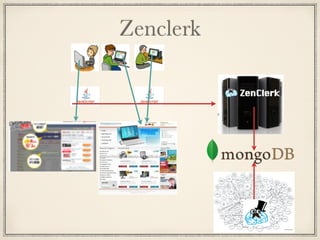
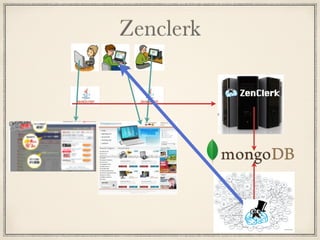
Zenclerk
10.
Zenclerk 毎月 PB 単位のデータを扱う 10TB単位のデータをMongoDBに保存 MainDB は
5 shard 構成(そんなにお高くないサーバ)
11.
困った
12.
困った それなりに複雑なシステムはステージング環境 が欲しいが、本番DBに向けてしまうと色々困る 機械学習で稼ぐビジネスなのに本番DBにカジュ アルにクエリーするとシステムが高負荷でダウ ンして危険 何らかの調査でtypoしたフィールドのクエリー 投げられて死ぬ
13.
Zenclerk
14.
それってStagingDB
15.
DummyデータでStaging ! 大きなデータがあるから発生する問題が多い 本番と同じデータが無いと機械学習が巧く行 く筈が無い (作った本人含めて)誰も使わない 全然意味なかった・・・
16.
でもMongoDBって・・・
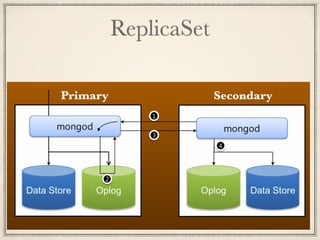
17.
MongoDBのレプリケーション ! ReplicaSet以外のデータ同期の仕組みは無い ReadOnlyでは不便極まりない 1日一回Secondaryを切り離して使う? フレッシュなデータが使いたいので却下された Sharding環境でそんな面倒な運用無理!
18.
でも困ってるんだよ・・・
19.
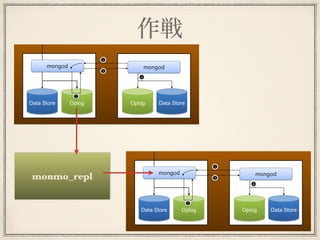
つい出来心で・・・ ! ある日ReplicaSetのoplogを生読みすればクエ リーベースのレプリケーションが組める事に 気付く 深い事考えずに『出来るわ!やろっか?』 『お願い!』という会話をしてしまう。 スーパー後悔・・・
20.
仕方が無い・・・ 面倒すぎて、1ヶ月放置した・・・ 『まだ∼?』『ゴメン!』を繰り返す。。 いい加減信用がヤバくなったので本腰入れた 即日nodeで書いたが速度がイマイチで mongo shellで書直し、色々問題直して賞味 1週間くらいかかった
21.
出来た!!
22.
https://github.com/zenclerk/monmo_repl 書き込み側のレイテンシーをクリアすれば 3TB/month までは間違く動く そこから先は頑張り次第
23.
技術的な説明
24.
ReplicaSet Primary Secondary
25.
作戦 monmo_repl
26.
性能1 MongoDBのレプリケーション周りはチューニ ングされており、とにかくoplogに追い着くの が大変 Bulkオペレーション必須 ns(collection)単位に分解して処理する
27.
性能2 シビアなので選択肢が少ない c++ driver →
流石にちょっと・・ node native driver → 少し遅かった mongo shell → 低機能だが高速
28.
性能3 mongo shell mongod, mongos
の mongo client を直接使う (本体だから)node native driver より チューニングが進んでいるっぽい Tailable cursorの不随意closeが検知できな い・・・つらい・・・
29.
oplogの注意点1 Tailable cursorは終端まで移動させるのに分単位 の時間が必要 レプリプログラムを再起動しても直ちに同期 を再開できない cursorは不随意に閉じる事がある oplogに負けてcursorの先端まで追いつめられる と上記のループに嵌って抜け出せない
30.
oplogの注意点2 oplogにはクエリーがそのまま保存されている訳 ではない 更新、削除系のクエリーは_id指定に展開される 例えばdb.remove({}) はドキュメント数のoplog にバラされ処理が膨れあがる レプリ先に独自に作ったドキュメントは範囲 更新などの影響を受けない
31.
oplogの注意点3 レプリ元と先の用途の違いを考慮 別々に運用したい場合関連オペレーション を塞き止める DB名、コレクション名を変えたい場合が ある データを選別して塞き止めたい(負荷が辛いが)
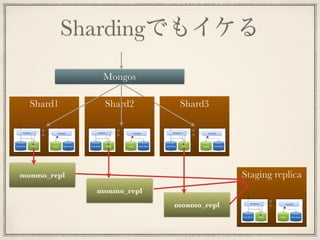
32.
Shardingでもイケる Mongos Shard3Shard1 Shard2 monmo_repl monmo_repl monmo_repl Staging replica
33.
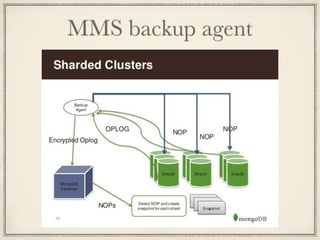
MMS backup agent
34.
Shardingでの工夫 Shardingのmigrationに伴うinsert/deleteは識別 して弾く
35.
嬉しい誤算
36.
Shardingでの嵌り所 Shardingのauto migrationはデータ量(chunk 数)の均一化をしてくれる 書き込み量の均一化は考慮してくれない 書き込み量が均一化されていないと特定 Shardのデータが膨れるのでmigrationを大量に 誘発してしまう
37.
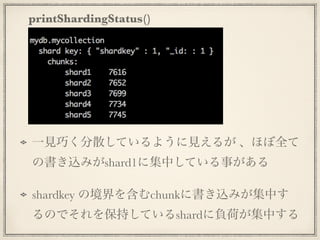
printShardingStatus() 一見巧く分散しているように見えるが 、ほぼ全て の書き込みがshard1に集中している事がある shardkey の境界を含むchunkに書き込みが集中す るのでそれを保持しているshardに負荷が集中する
38.
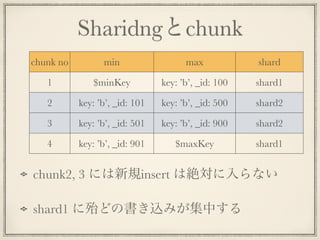
Sharidngとchunk chunk no min
max shard 1 $minKey key: ’b’, _id: 100 shard1 2 key: ’b’, _id: 101 key: ’b’, _id: 500 shard2 3 key: ’b’, _id: 501 key: ’b’, _id: 900 shard2 4 key: ’b’, _id: 901 $maxKey shard1 chunk2, 3 には新規insert は絶対に入らない shard1 に殆どの書き込みが集中する
39.
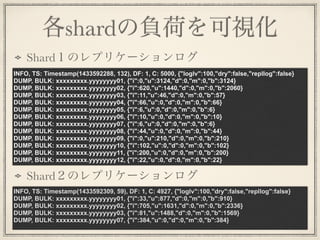
各shardの負荷を可視化 INFO, TS: Timestamp(1433592288,
132), DF: 1, C: 5000, {"loglv":100,"dry":false,"repllog":false} DUMP, BULK: xxxxxxxxx.yyyyyyyy01, {"i":0,"u":3124,"d":0,"m":0,"b":3124} DUMP, BULK: xxxxxxxxx.yyyyyyyy02, {"i":620,"u":1440,"d":0,"m":0,"b":2060} DUMP, BULK: xxxxxxxxx.yyyyyyyy03, {"i":11,"u":46,"d":0,"m":0,"b":57} DUMP, BULK: xxxxxxxxx.yyyyyyyy04, {"i":66,"u":0,"d":0,"m":0,"b":66} DUMP, BULK: xxxxxxxxx.yyyyyyyy05, {"i":6,"u":0,"d":0,"m":0,"b":6} DUMP, BULK: xxxxxxxxx.yyyyyyyy06, {"i":10,"u":0,"d":0,"m":0,"b":10} DUMP, BULK: xxxxxxxxx.yyyyyyyy07, {"i":6,"u":0,"d":0,"m":0,"b":6} DUMP, BULK: xxxxxxxxx.yyyyyyyy08, {"i":44,"u":0,"d":0,"m":0,"b":44} DUMP, BULK: xxxxxxxxx.yyyyyyyy09, {"i":0,"u":210,"d":0,"m":0,"b":210} DUMP, BULK: xxxxxxxxx.yyyyyyyy10, {"i":102,"u":0,"d":0,"m":0,"b":102} DUMP, BULK: xxxxxxxxx.yyyyyyyy11, {"i":200,"u":0,"d":0,"m":0,"b":200} DUMP, BULK: xxxxxxxxx.yyyyyyyy12, {"i":22,"u":0,"d":0,"m":0,"b":22} INFO, TS: Timestamp(1433592309, 59), DF: 1, C: 4927, {"loglv":100,"dry":false,"repllog":false} DUMP, BULK: xxxxxxxxx.yyyyyyyy01, {"i":33,"u":877,"d":0,"m":0,"b":910} DUMP, BULK: xxxxxxxxx.yyyyyyyy02, {"i":705,"u":1631,"d":0,"m":0,"b":2336} DUMP, BULK: xxxxxxxxx.yyyyyyyy03, {"i":81,"u":1488,"d":0,"m":0,"b":1569} DUMP, BULK: xxxxxxxxx.yyyyyyyy07, {"i":384,"u":0,"d":0,"m":0,"b":384} Shard1のレプリケーションログ Shard2のレプリケーションログ
40.
手で調整 問題のあるコレクションが解れば、shardkey の境界を含んだchunkを移動すれば良い monmo_replが仕掛けてあると調整の結果が リアルタイムで見える! chunk移動もスクリプト化しておくと楽(ま だ公開できない出来・・・)
41.
もうMongoDB怖くないよね
Download

















































































![[MongoDB勉強会 in 2017] MongoDB on AWS](https://cdn.slidesharecdn.com/ss_thumbnails/mongodb2017mongodbonaws-170912003504-thumbnail.jpg?width=640&height=640&fit=bounds)
















