More Related Content

PDF
Swagger ではない OpenAPI Specification 3.0 による API サーバー開発 
PPTX
Apache Avro vs Protocol Buffers 
PDF

PDF
分散トレーシング技術について(Open tracingやjaeger) 
PDF

PPTX

PDF

PPTX
What's hot

PDF
高い並列性能と耐障害性を持つElixirとNervesでIoTの新しいカタチを切り拓く 
PDF
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc... 
PDF
組織の問題も解決するアーキテクチャ BackendsForFrontends 
PDF
Apache tinkerpopとグラフデータベースの世界 
PDF

PDF
AWSでDockerを扱うためのベストプラクティス 
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug 
PDF

PDF

PDF

PDF

PPTX

PDF

PDF

PPTX
kubernetes初心者がKnative Lambda Runtime触ってみた(Kubernetes Novice Tokyo #13 発表資料) 
PDF

PDF
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話 
PDF

PDF
イマドキ!ユースケース別に見るAWS IoT への接続パターン 
PDF
ホットペッパービューティーにおけるモバイルアプリ向けAPIのBFF/Backend分割 Viewers also liked

PDF
今日から使えるCouchbaseシステムアーキテクチャデザインパターン集 
PDF
The Graph Traversal Programming Pattern 
PDF
「GraphDB徹底入門」〜構造や仕組み理解から使いどころ・種々のGraphDBの比較まで幅広く〜 
PDF

PPTX
Neo4j の「データ操作プログラミング」から 「ビジュアライズ」まで 
PPTX

PDF

PPTX

PDF
Similar to SQLまで使える高機能NoSQLであるCouchbase Serverの勉強会資料

PDF

PDF
Couchbase introduction-20150611 
PPTX
Introduce couchbase server 
PPTX
What's new in Couchbase Server 4.0 ja 
PDF

PDF
db tech showcase 東京 2014 - Couchbase Serverを用いた大規模データ収集基盤 ![Couchbase meetup20140225[Release Note 2.5]](https://cdn.slidesharecdn.com/ss_thumbnails/couchbasemeetup20140225-140301064950-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
Couchbase meetup20140225[Release Note 2.5] 
PPT

PDF

PDF
Elasticsearch 2014/04/21 勉強会資料 「Couchbase と Elasticsearch が手を結んだら」 
PPTX

PDF

PPTX
米GEのIoT基盤「Predix」を支えるNoSQL Couchbaseモバイルソリューション 
PPTX
クラウドで運用するCouchbase Server ![20150831 Couchbase Tokyo 2015 [Mobile] 端末の位置情報をフル活用でSFAはモバイルベースに!](https://cdn.slidesharecdn.com/ss_thumbnails/20150831couchbasetokyo2015mobilemobilesfascsk-150908054122-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
20150831 Couchbase Tokyo 2015 [Mobile] 端末の位置情報をフル活用でSFAはモバイルベースに! 
PDF

PDF
Couchbase Serverのサーバ移管と2.1から3.0.1へのバージョンアップ ![[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015e26couchbaseandjbossdatavirtualization-150616073132-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[db tech showcase Tokyo 2015] E26 Couchbaseの最新情報/JBoss Data Virtualizationで仮想... 
PDF

PDF
SQLまで使える高機能NoSQLであるCouchbase Serverの勉強会資料
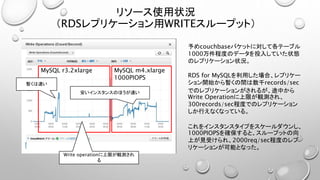
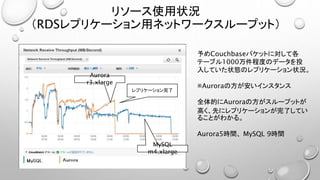
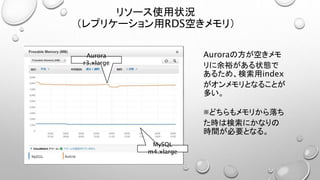
- 1.
- 2.
- 3.
- 4.
- 5.
Couchabe 3.x系
• NoSQL
•他のNoSQL製品と比べても速いよ
• ノード追加でどこまでもスケールするよ
• データ量
• CPU資源・メモリー資源
• データ冗長度を高く設定できるよ。(AZ間で持てるのでZone障害でデータロストしない)
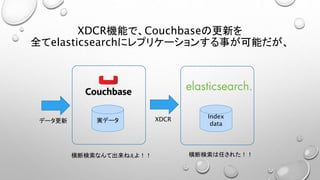
• XDCRという機能があって、リージョン感で双方向レプリケーションできるよ。(海外に待機系シス
テムを構築すれば東京リージョン全滅でも大丈夫)
• elasticsearch連携すれば横断検索も出来る
• SDKの完成度が高くて信頼性があるよ。
• WebConsoleの出来が異様にいいよ。
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
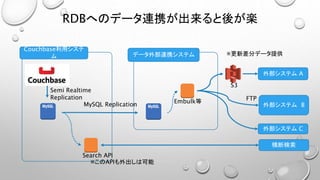
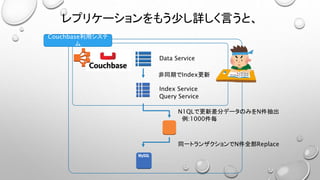
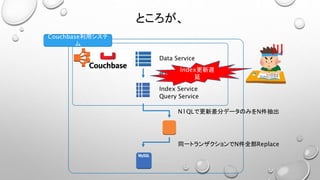
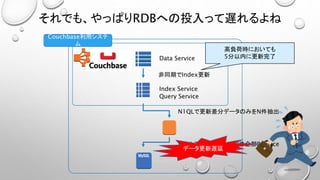
• N1QLを使うなら、1テーブル =1バケットの考え方で実装しておきたい。
• JOINが面倒、コストが高い(JOIN先は必ず別のドキュメントのキーである必要がある)
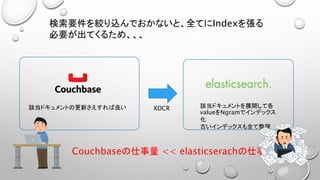
• 検索要件に合わせてIndexを増やすと、物理メモリを大量に消費するので高コストとなる。
• Selectされる結果セットが数万件以上になると異様に遅くなり実用に耐えない。
• すぐにタイムアウトする
• Index更新が非同期でSelect条件と得られる結果がズレたりする
• 大量データのExportには向かない。
(巨大なJSONドキュメントとして結果が得られる。落ちる、ページングしてる間にデータが更新される。)
• N1QLのご利用は計画的に
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.