Download as PDF, PPTX












![®
© 2014 MapR Technologies 13
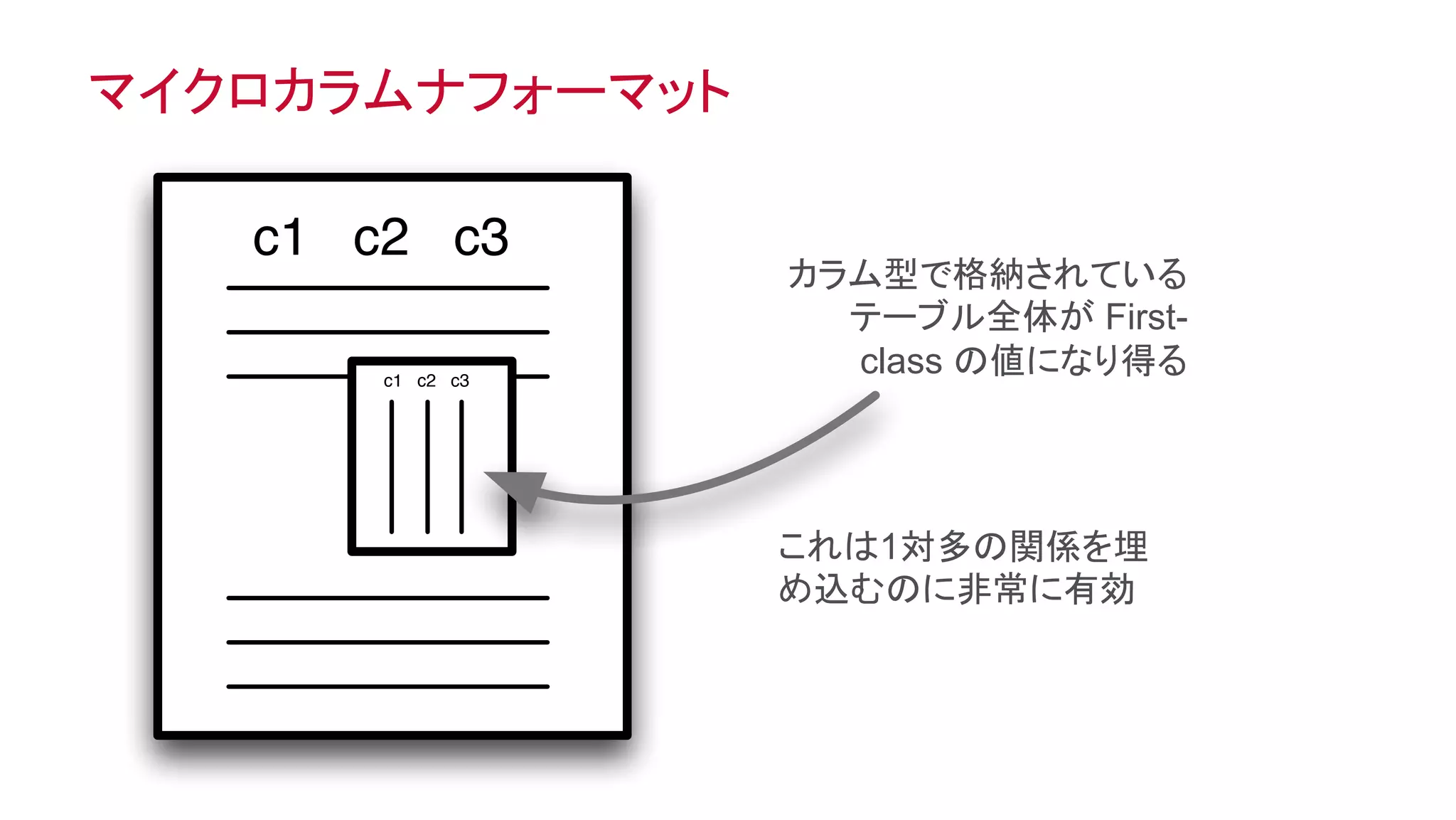
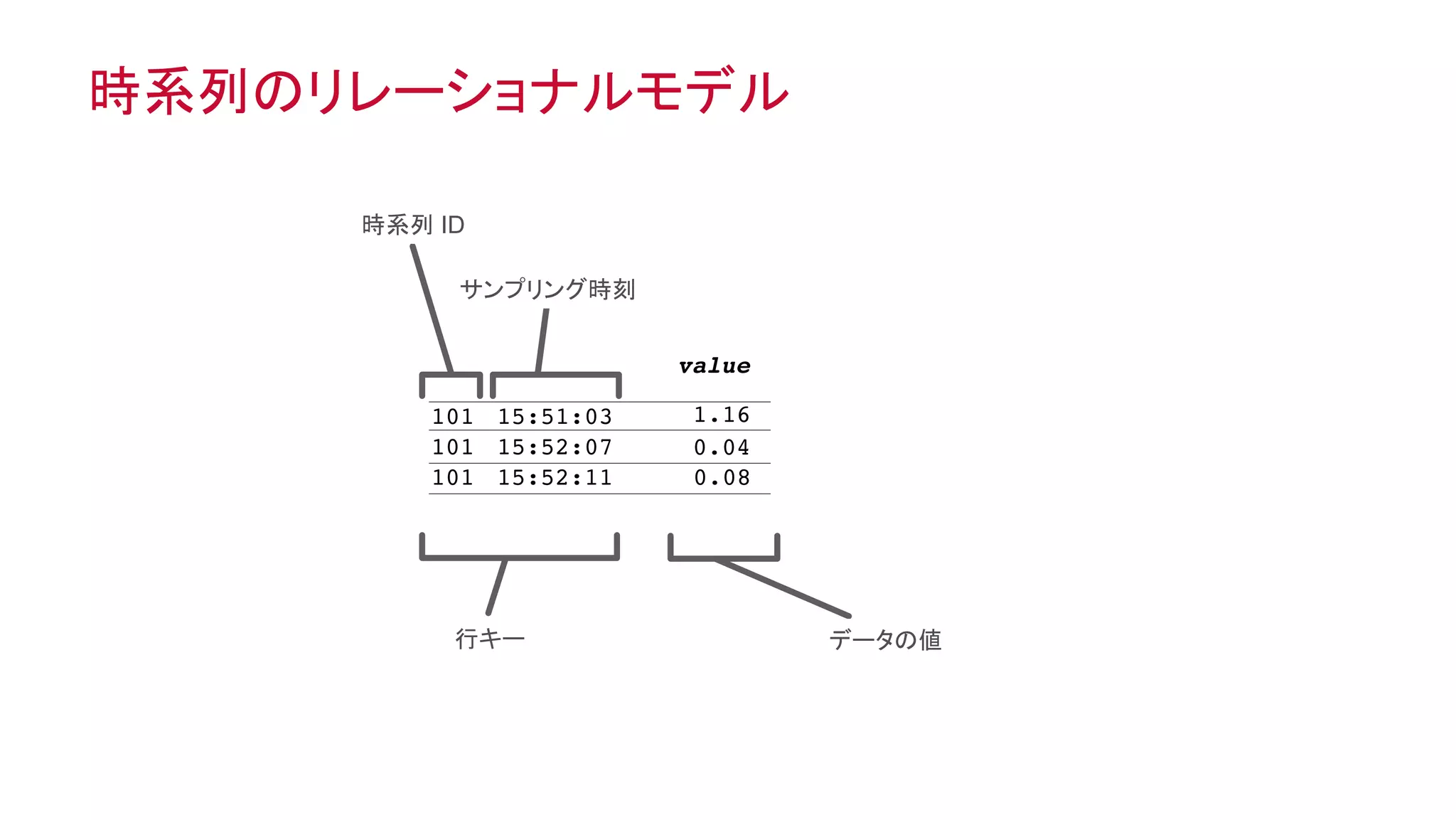
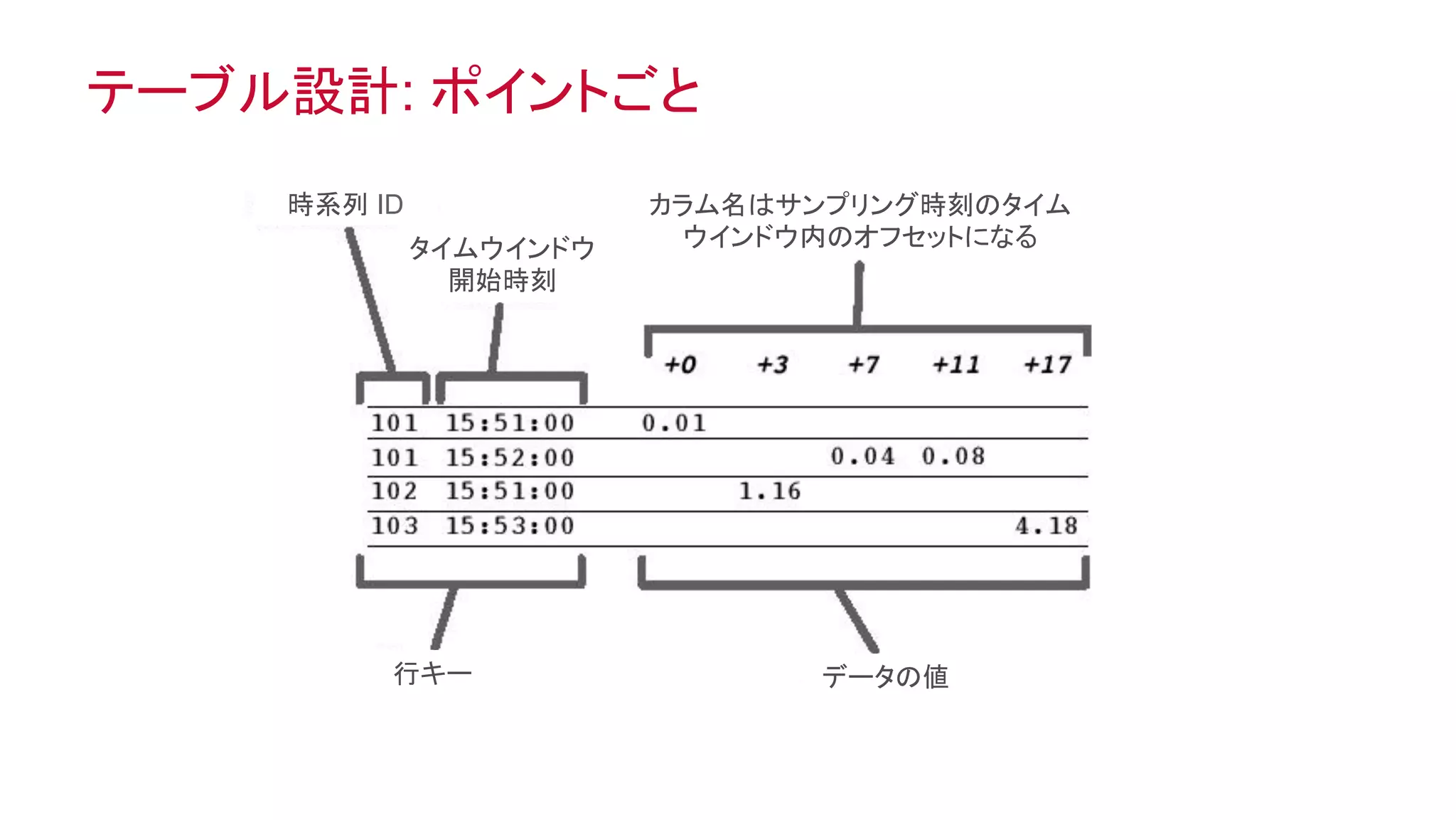
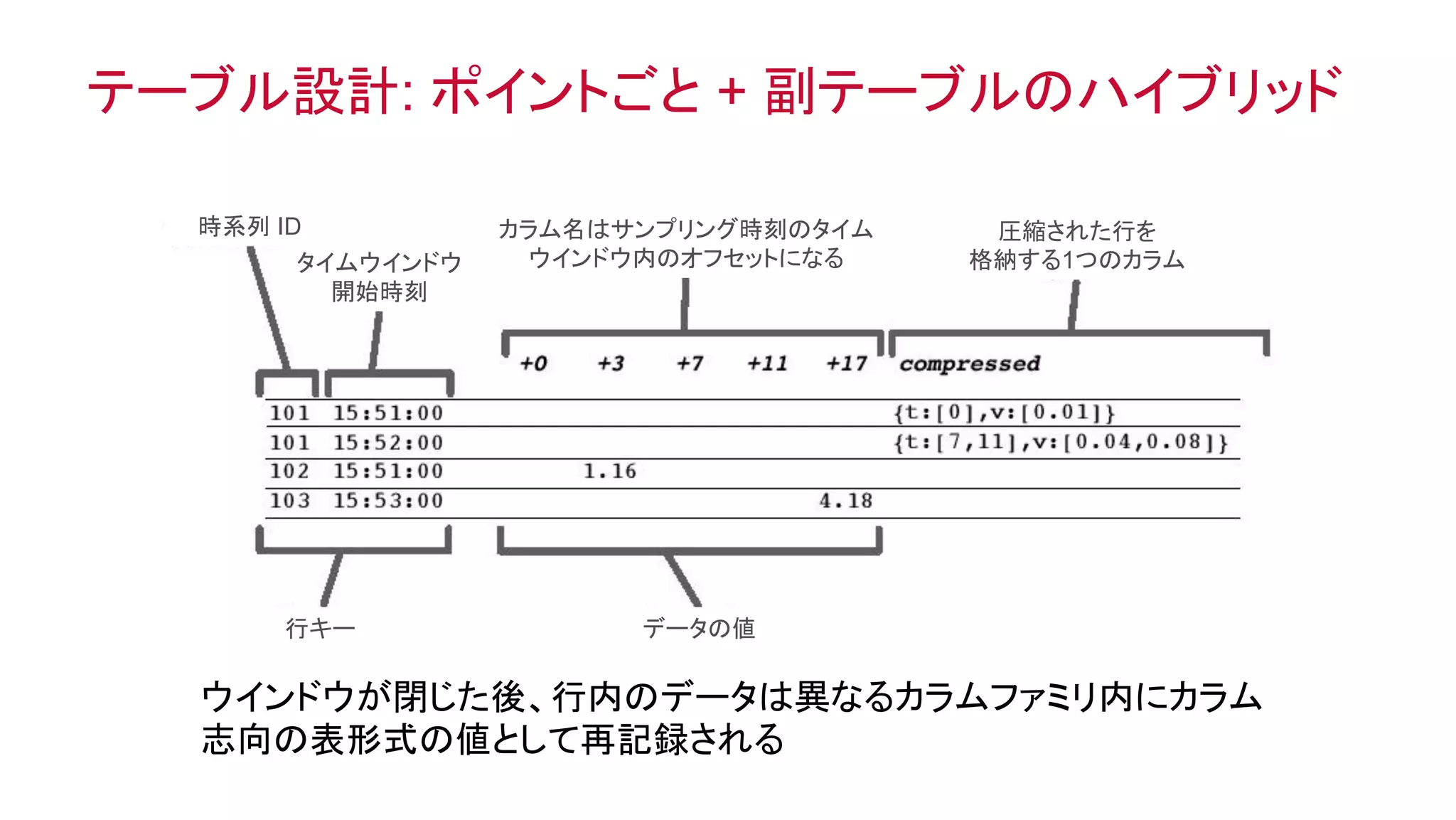
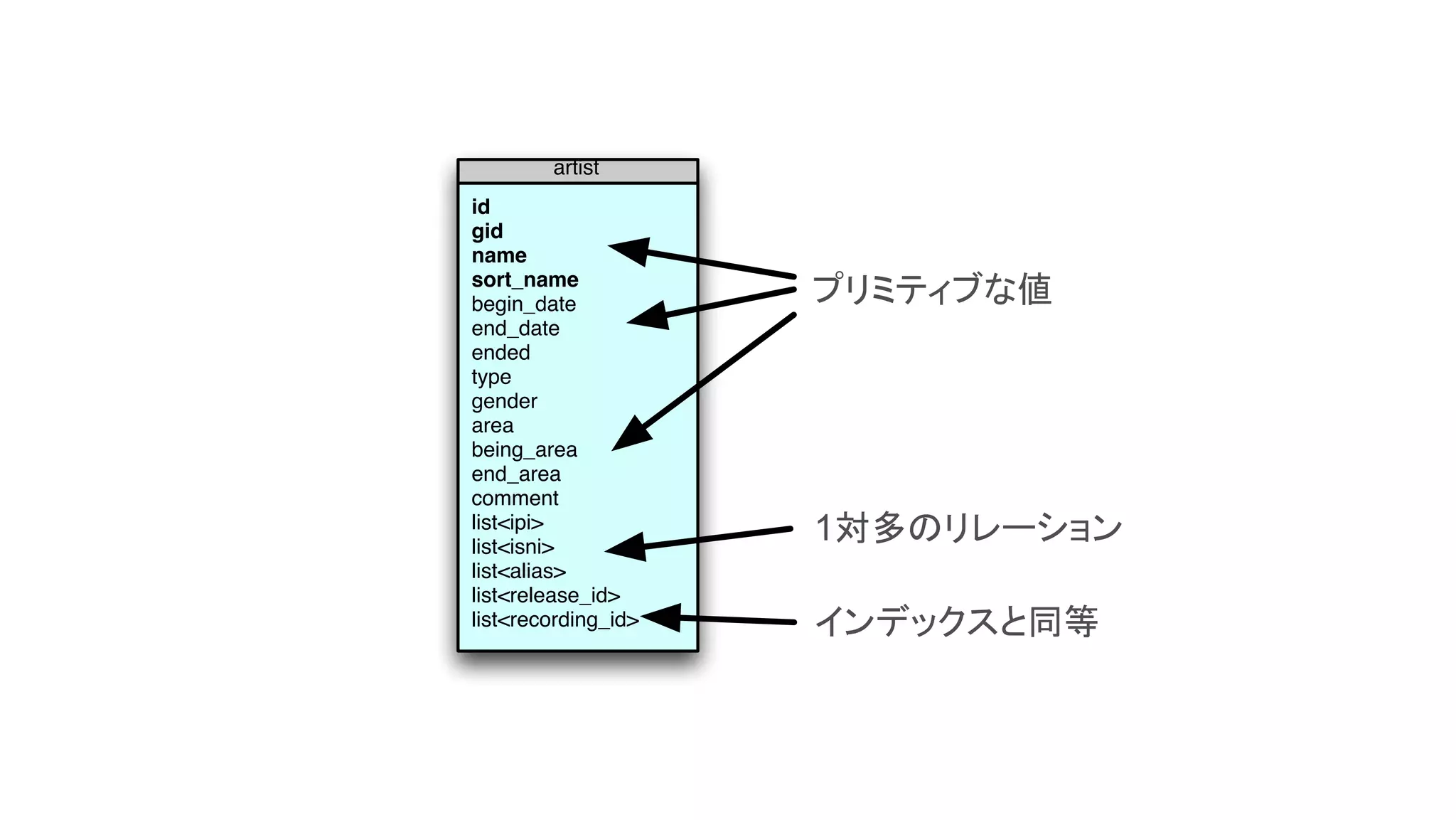
オブジェクトとしてのテーブル、テーブルとしてのオブジェクト
c1 c2 c3
行志向の形式
c1 c2 c3
列志向の形式
[ { c1:v1, c2:v2, c3:v3 },
{ c1:v1, c2:v2, c3:v3 },
{ c1:v1, c2:v2, c3:v3 } ]
複数オブジェクトのリスト
{ c1:[v1, v2, v3],
c2:[v1, v2, v3],
c3:[v1, v2, v3] }
複数リストを含むオブジェクト](https://image.slidesharecdn.com/how-loosely-typed-sql-is-ideal-for-nosql-ja-150918085458-lva1-app6891/75/HBase-Drill-SQL-NoSQL-13-2048.jpg)



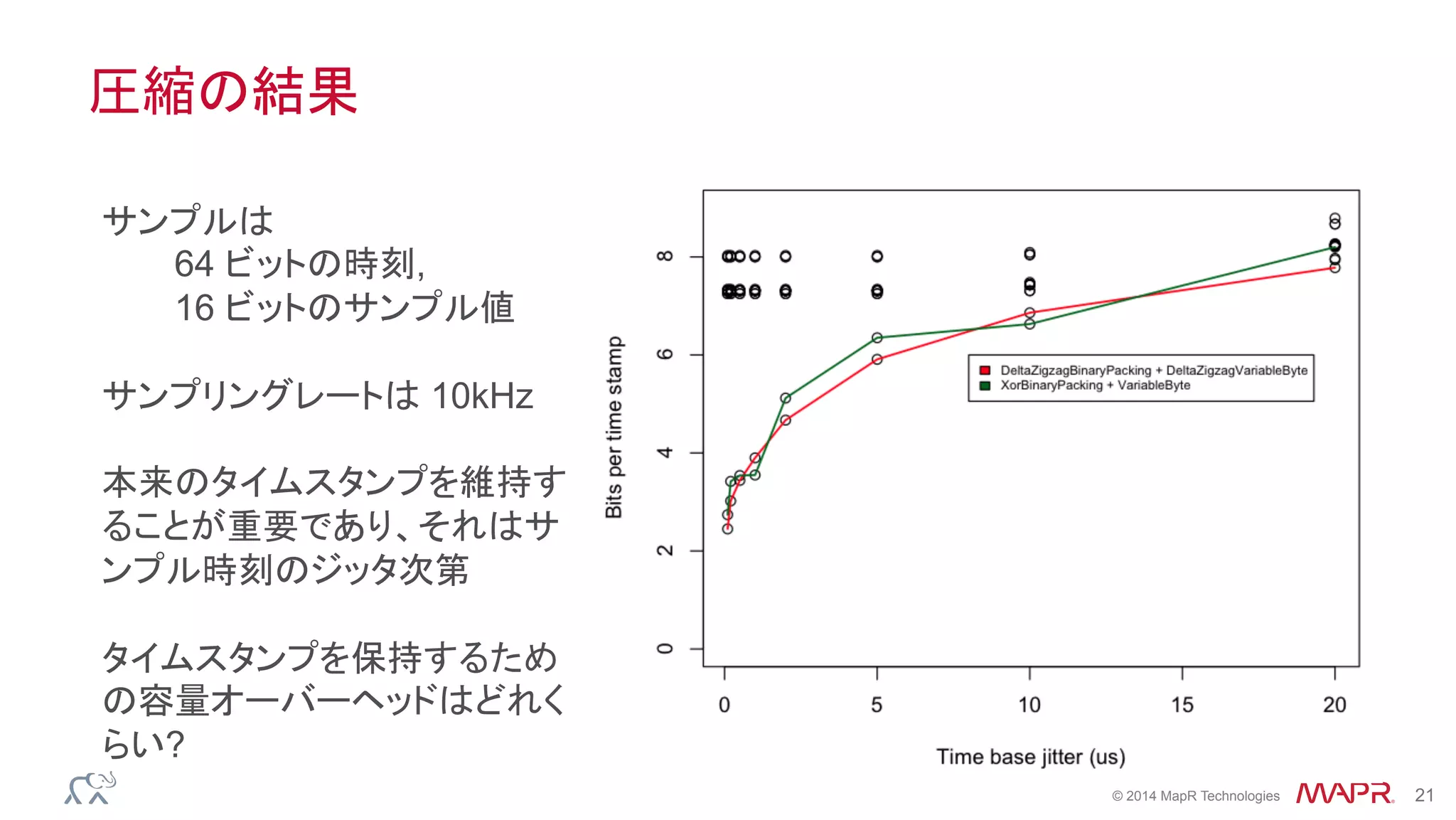



















Apache HBaseのデータへのアプローチは、非リレーショナルプログラムがNoSQL型の表現をするための大きな潜在能力を備えています。一方、Apache Drillは非リレーショナルデータに対するSQLをサポートします。逆説的ですが、このNoSQLをこのSQLツールと組み合わせることでよりよい結果が導き出せるのです。時系列データにアクセスしたり、高性能なセカンダリインデックスをサポートしたりするために、HBaseとDrillをどのように組み合わせるかを説明します。Ted DunningによるHadoop Summit 2015の講演より。























































![[D36] Michael Stonebrakerが生み出した列指向データベースは何が凄いのか? ~Verticaを例に列指向データベースのアーキテクチャ...](https://cdn.slidesharecdn.com/ss_thumbnails/d36verticakomori-131125025044-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Sapporo 2015] B16:ビッグデータには、なぜ列指向が有効なのか? by 日本ヒューレット・パッカード株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b16bigdataverticahewletpackard-150918014205-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









