Download to read offline




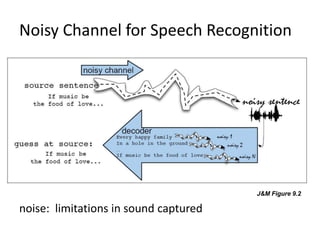
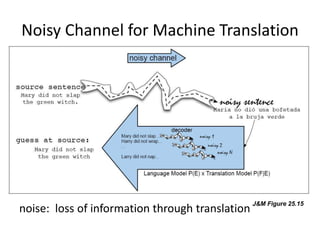
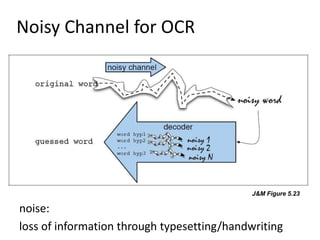



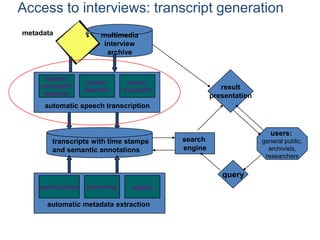


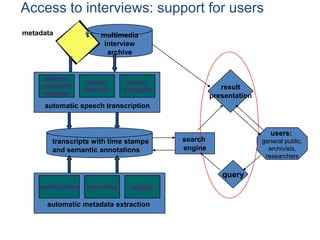















This document discusses indexing and searching noisy data. Part I provides examples of noisy data from spelling corrections, speech recognition, machine translation and optical character recognition where information is lost. Part II discusses emerging scenarios for scholarly use of noisy metadata including discovery and exploration of large digital collections. Part III argues that metadata mining can enhance accessibility and understanding by integrating different annotation types from manual, automatic and community sources.






























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










