Downloaded 45 times






















![Department of Computer
Science and Engineering
IIT Kharagpur
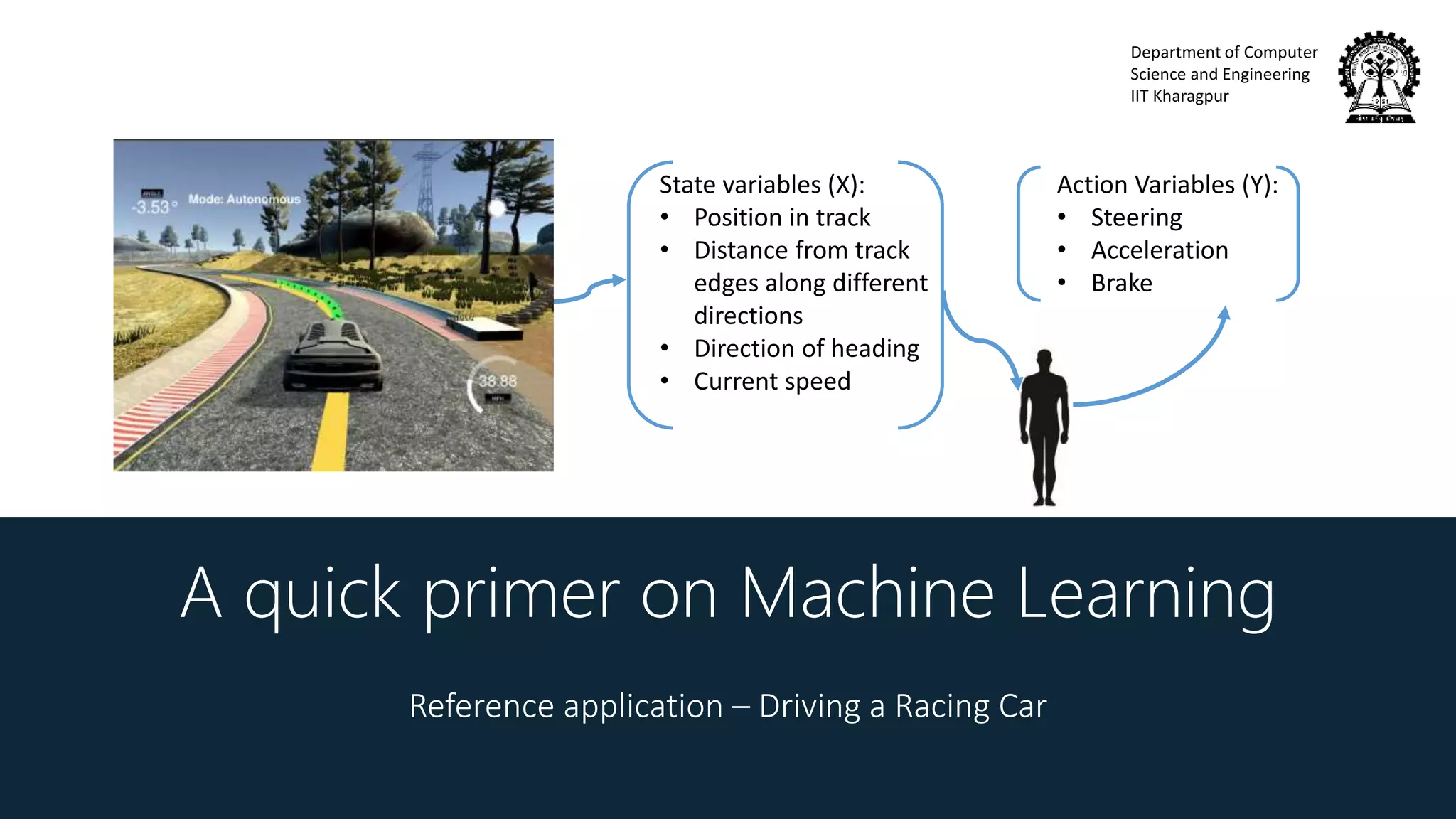
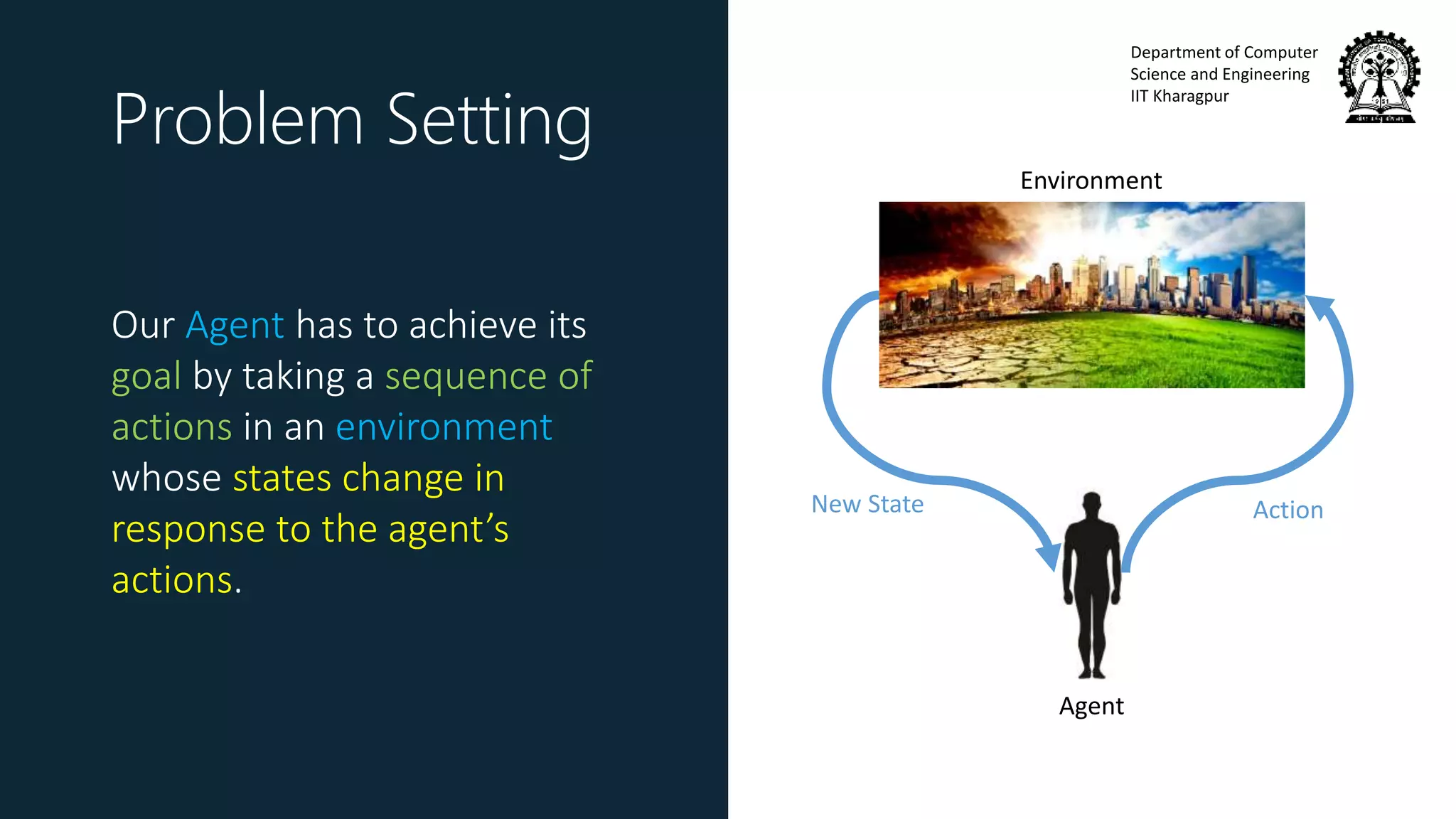
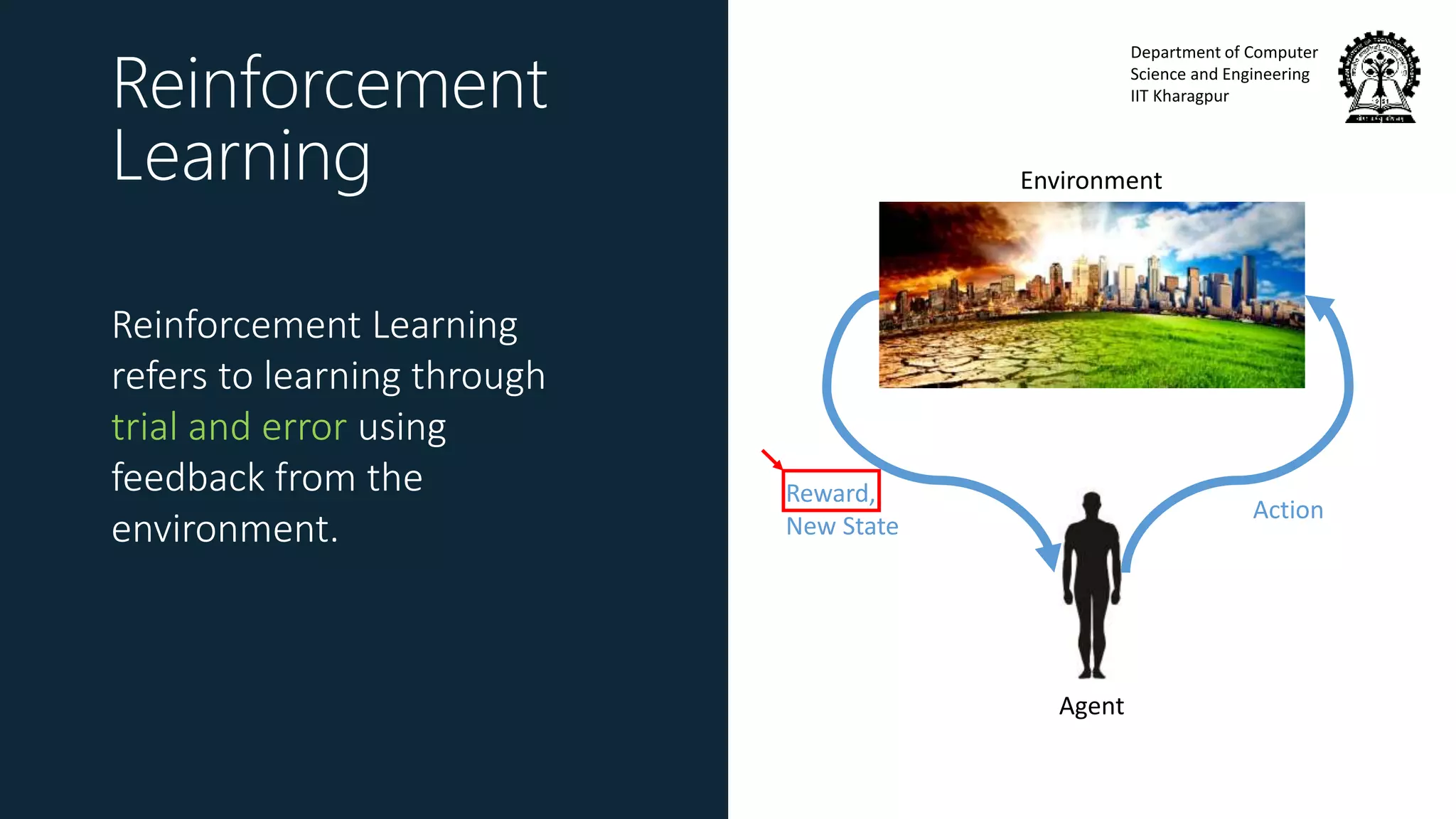
Goal of RL
Find a policy 𝜋∗that
maximizes the expectation of
the reward function 𝑅 𝜏
over trajectories 𝜏
𝜋∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝜋 Ε 𝜏[𝑅(𝜏)]
Reward of a trajectory 𝑅 𝜏 is a
function of all the rewards
received in a trajectory
e.g. 𝑅 𝜏 = 𝑡 𝑟𝑡 , 𝑅 𝜏 = 𝑡 𝛾 𝑡 𝑟𝑡](https://image.slidesharecdn.com/invitedtalkssncollege-171211080345/75/Imitation-Learning-26-2048.jpg)




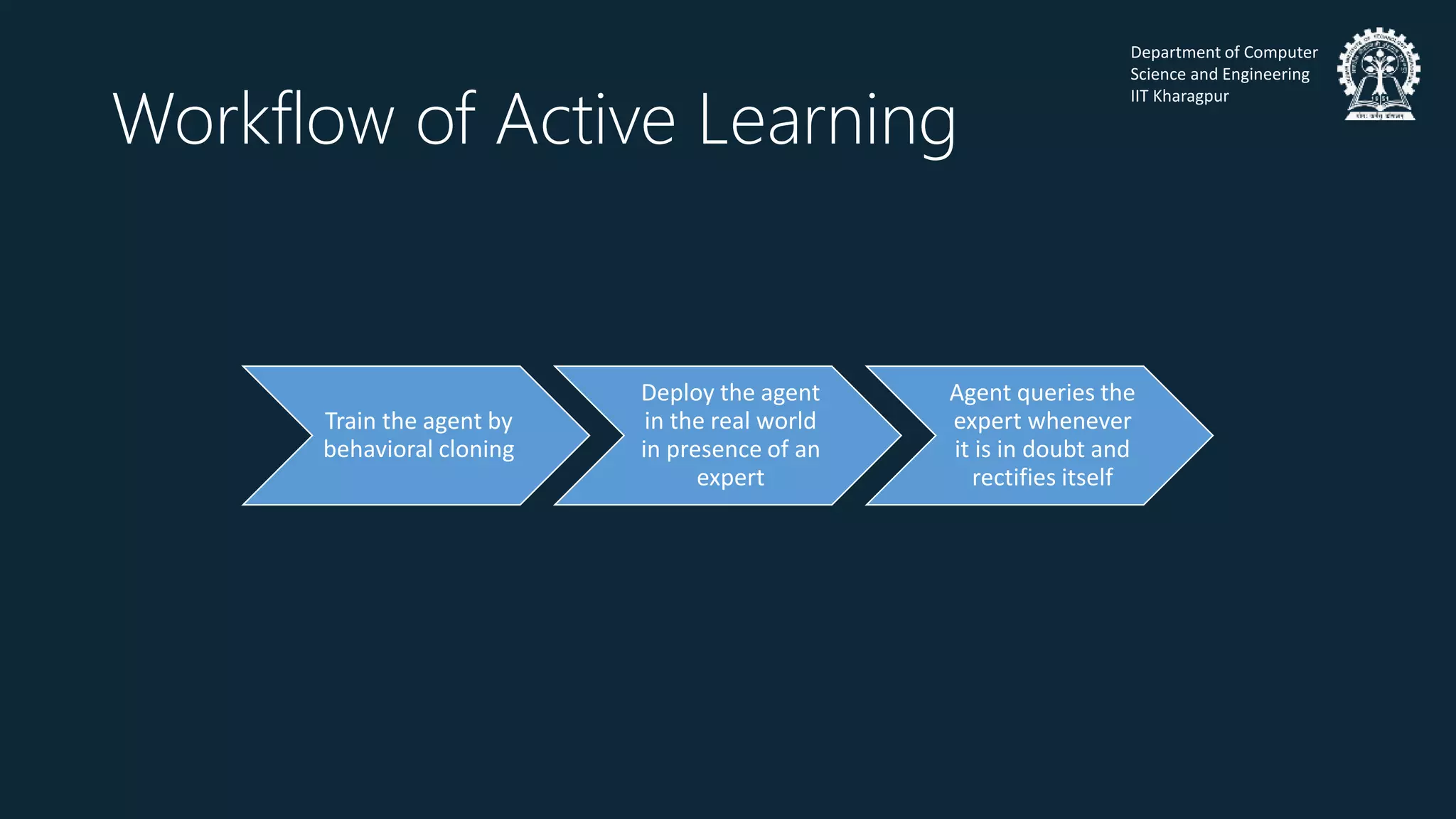











This document summarizes an upcoming talk on imitation learning techniques. Imitation learning aims to mimic human behavior at a given task by learning from human demonstrations. The document outlines different approaches to imitation learning, including behavioral cloning, apprenticeship learning, and active learning. It also discusses issues of safety when applying imitation learning and different techniques for ensuring safety, such as risk-averse exploration and modifying the optimization criterion. As an example, it describes how the RAIL algorithm makes the existing GAIL algorithm safer by optimizing for conditional value at risk of trajectory risk.







































![Machine learning[1]](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearning1-200817054911-thumbnail.jpg?width=640&height=640&fit=bounds)



























