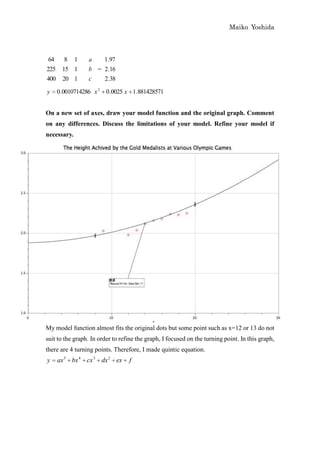
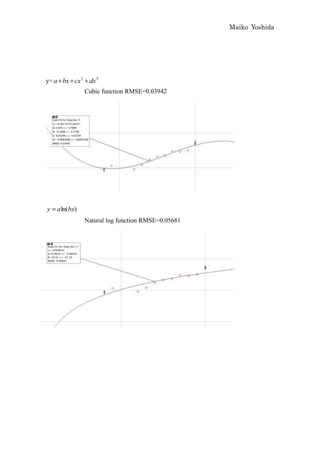
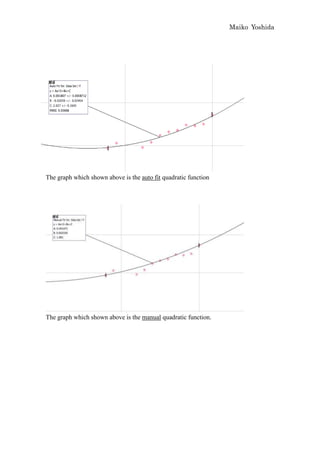
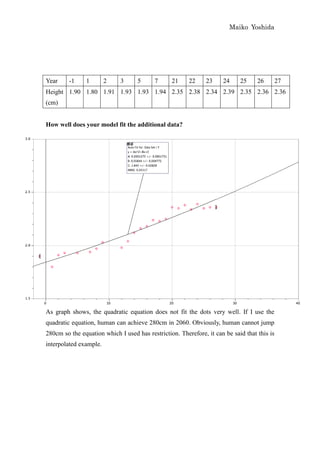
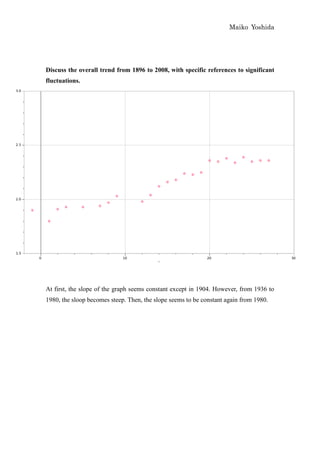
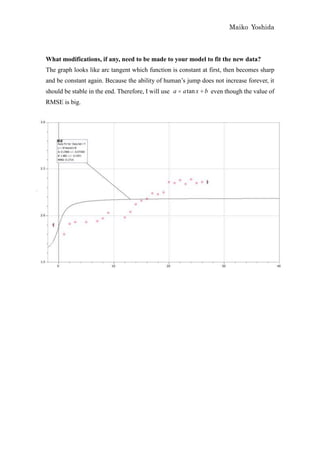
This document discusses modeling the winning heights of Olympic gold medalists from 1932 to 2008 using various functions. The data is initially scaled and a quadratic function is fit manually and automatically. While the quadratic function fits the original data well, it does not extrapolate reasonably to future years. When additional data from 1984 to 2008 is added, the quadratic function is no longer a good fit. An arc tangent function is proposed to better model the leveling off of heights over time.