1. The document analyzes the winning heights of men's high jump gold medalists at the Olympic Games from 1896 to 2008. Various mathematical models are tested to fit the data, including linear, logarithmic, cubic, and Gaussian functions.
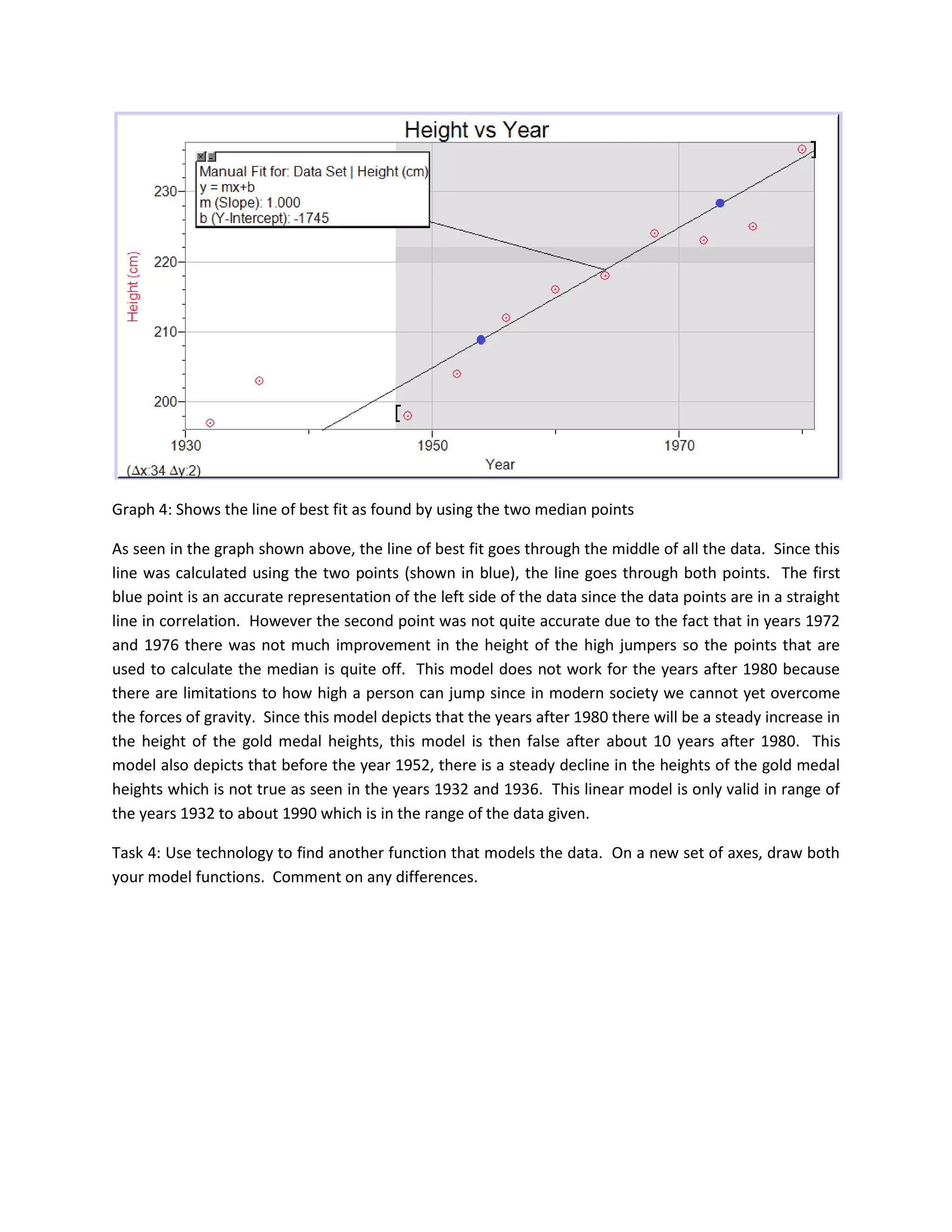
2. The initial linear model is found to fit the data reasonably from 1932 to around 1990 but fails outside this range. A modified logarithmic model provides a better fit overall but still has limitations.
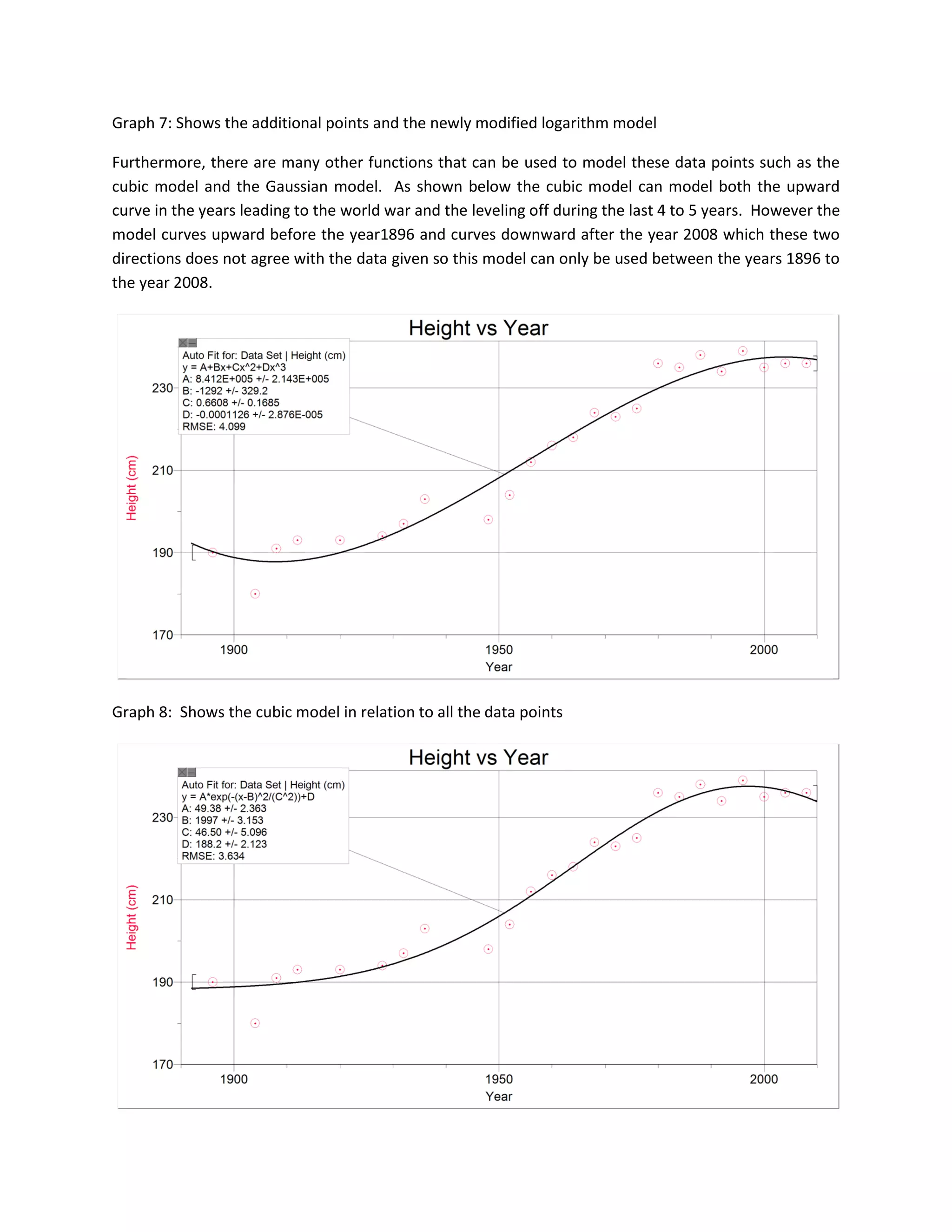
3. Cubic and Gaussian models also show good fits for parts of the data trend but cannot fully represent fluctuations throughout the entire data set from 1896 to 2008. Further refinement of models is needed to accurately capture the entire trend over time.