Download as PDF, PPTX







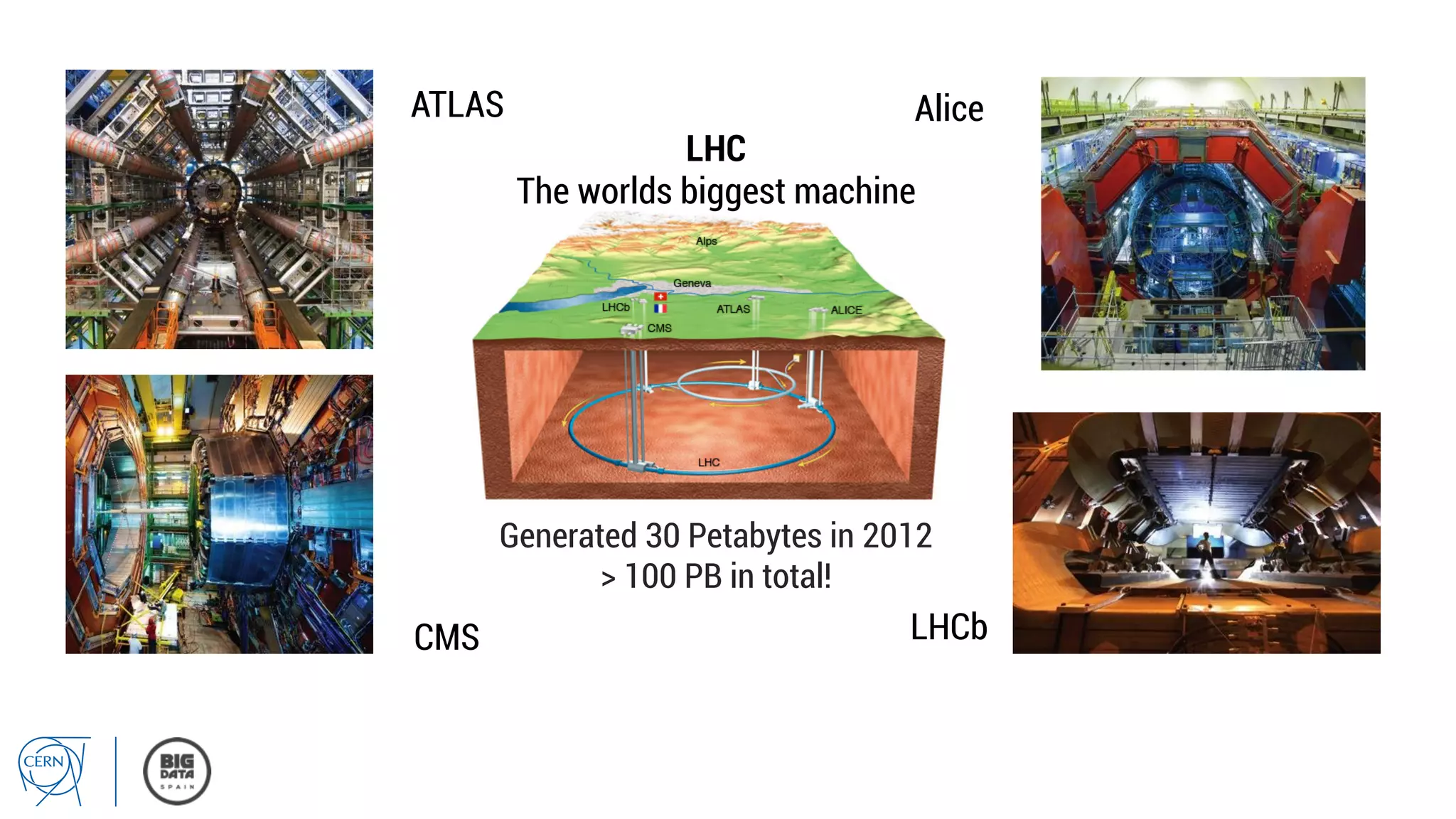


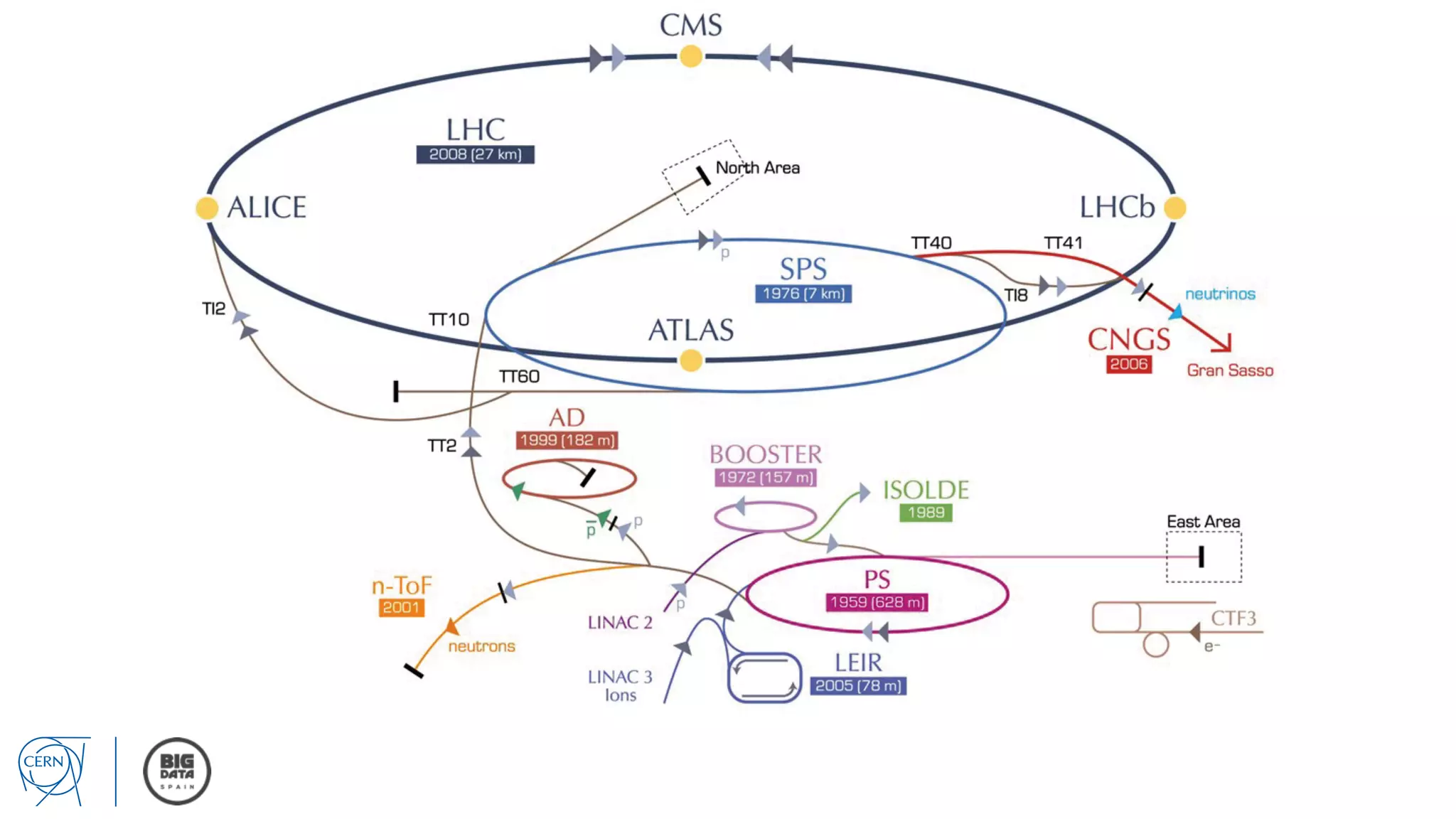















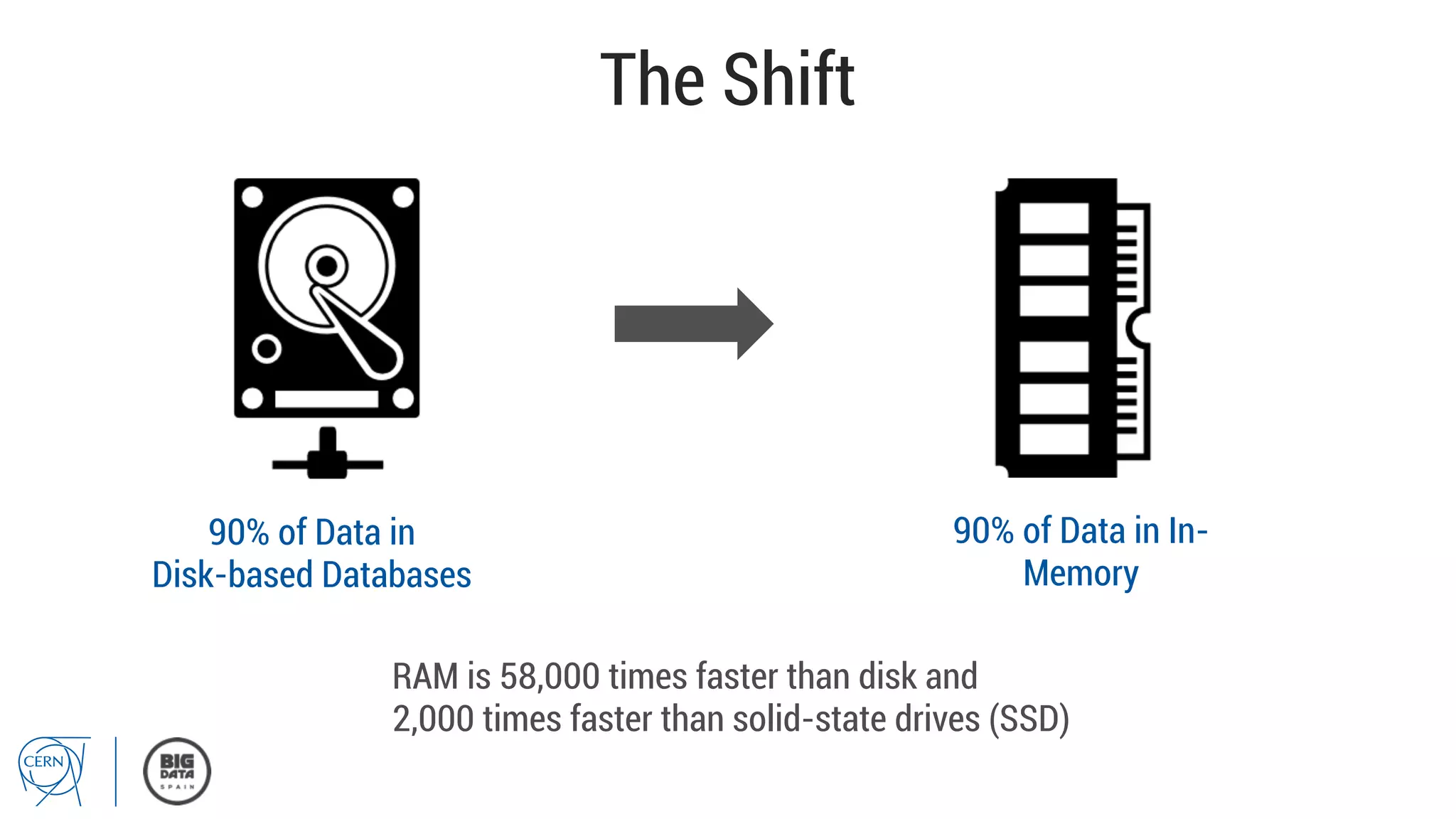
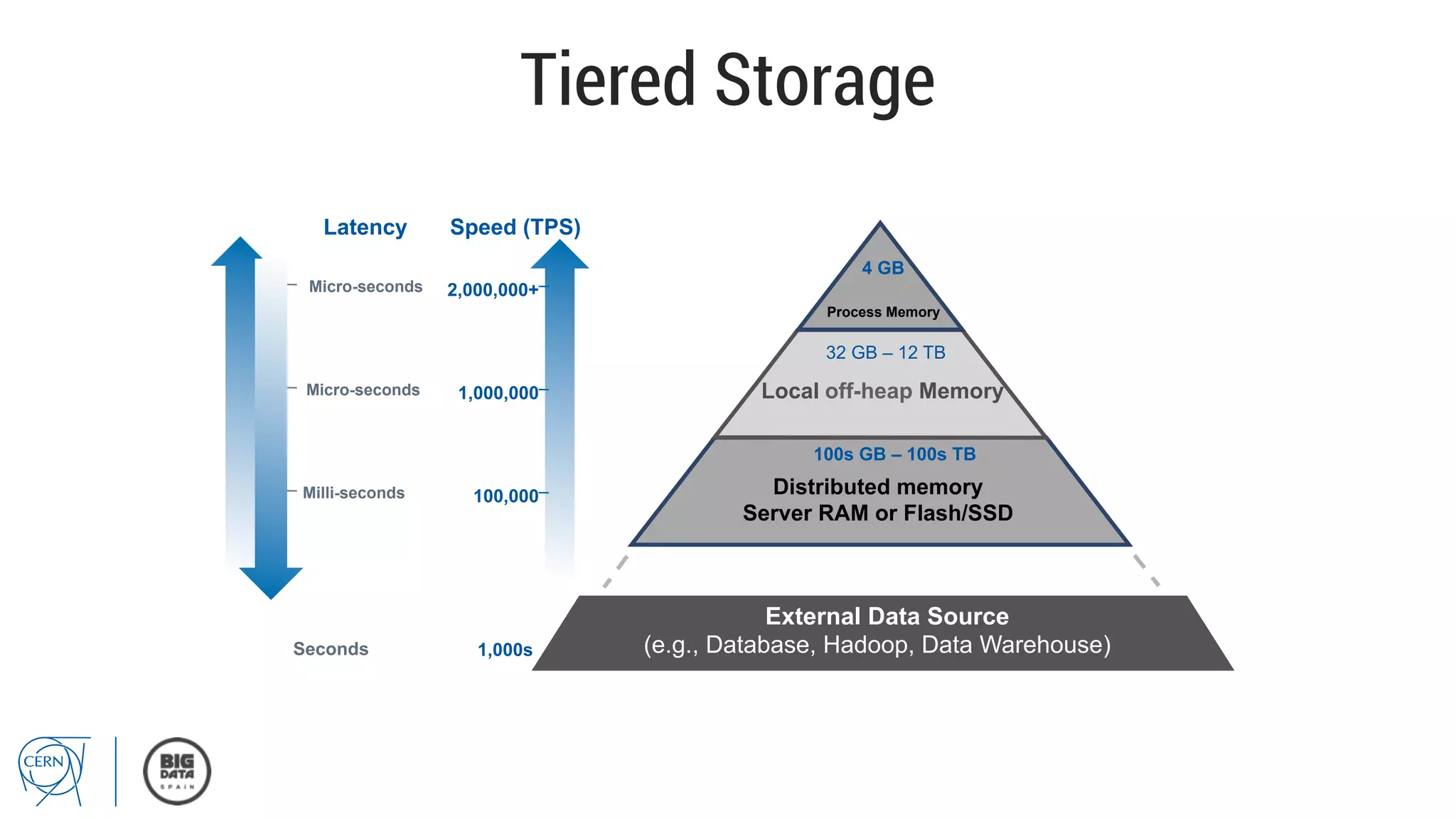
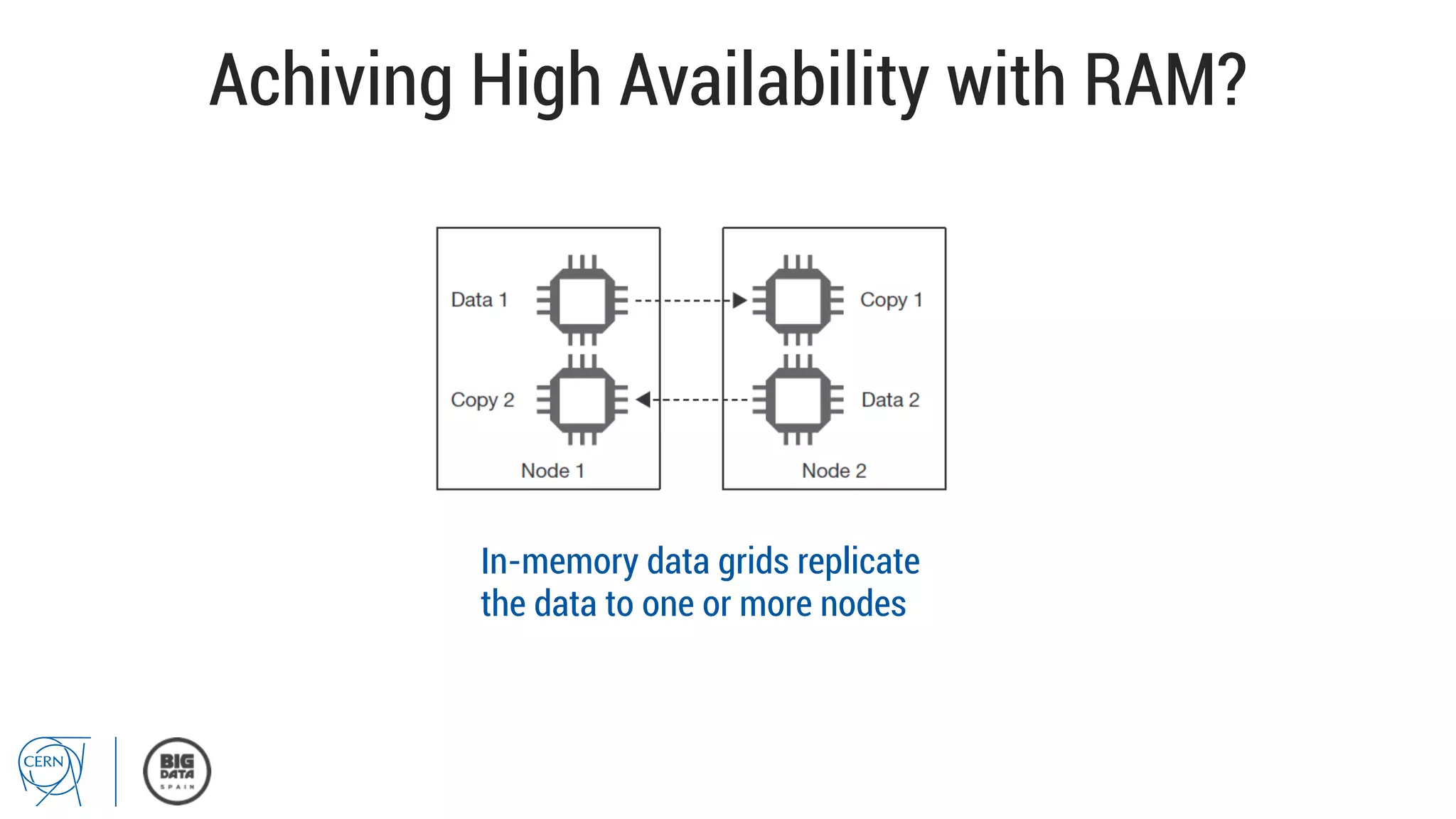


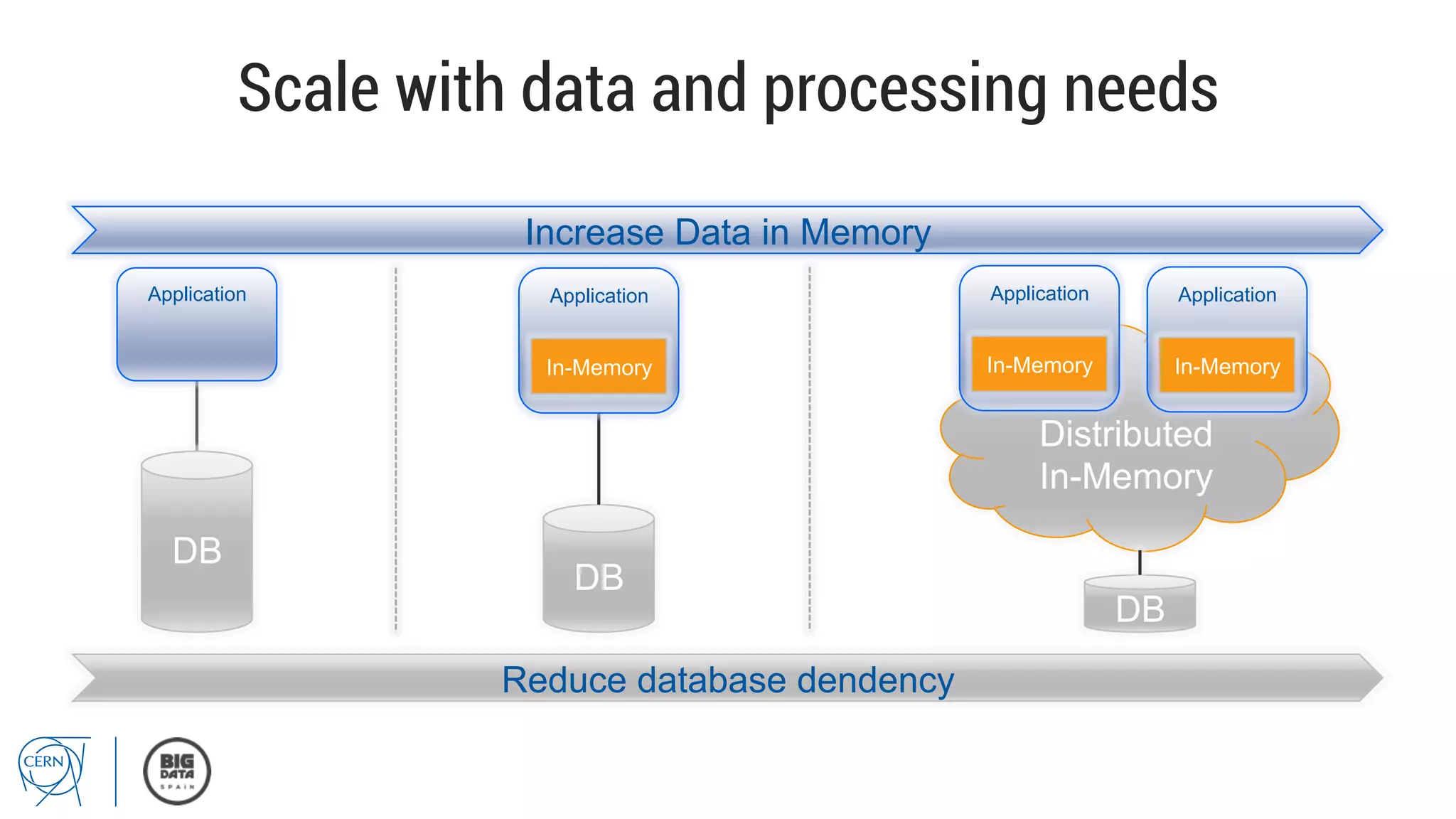

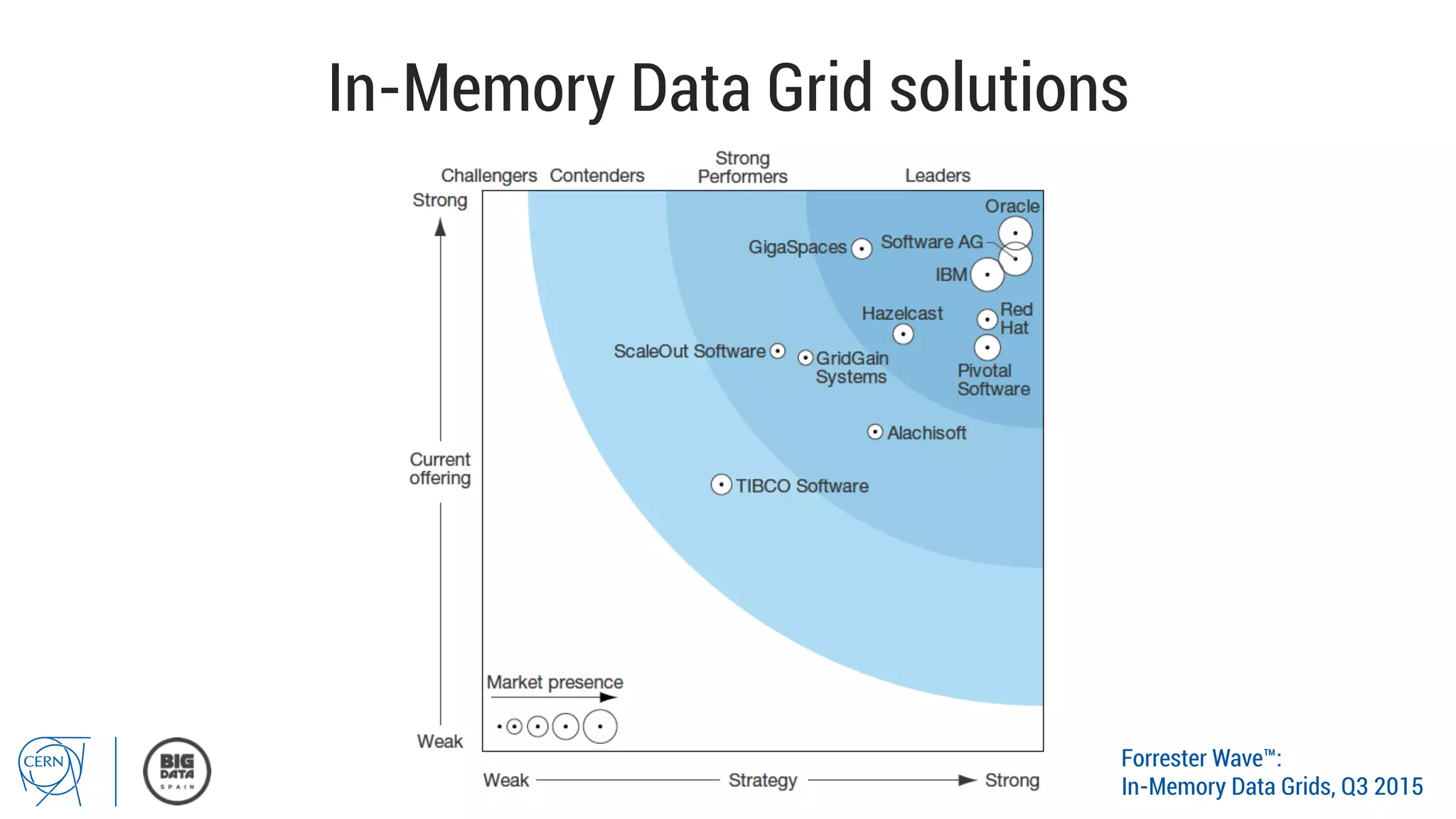
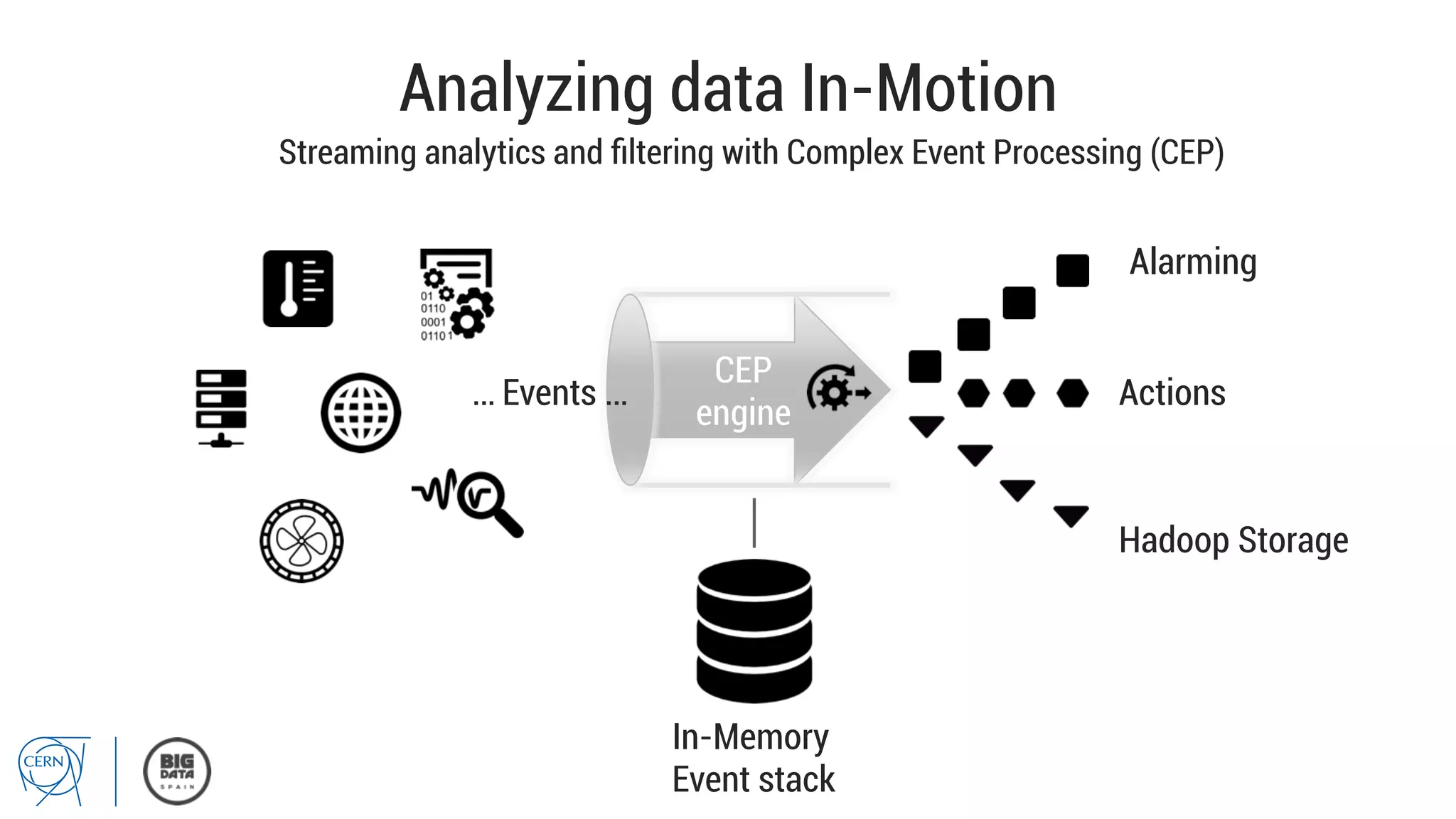








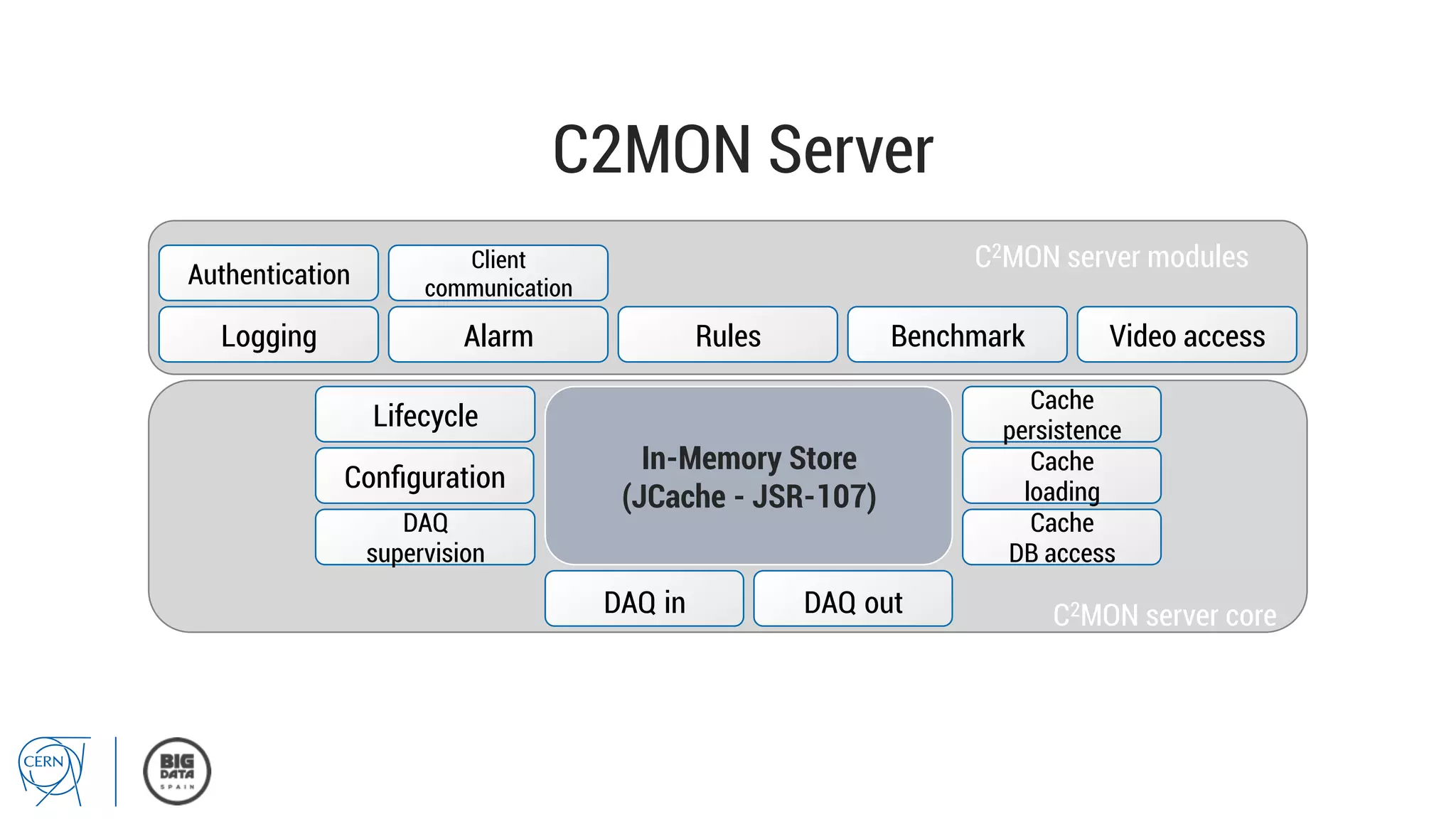

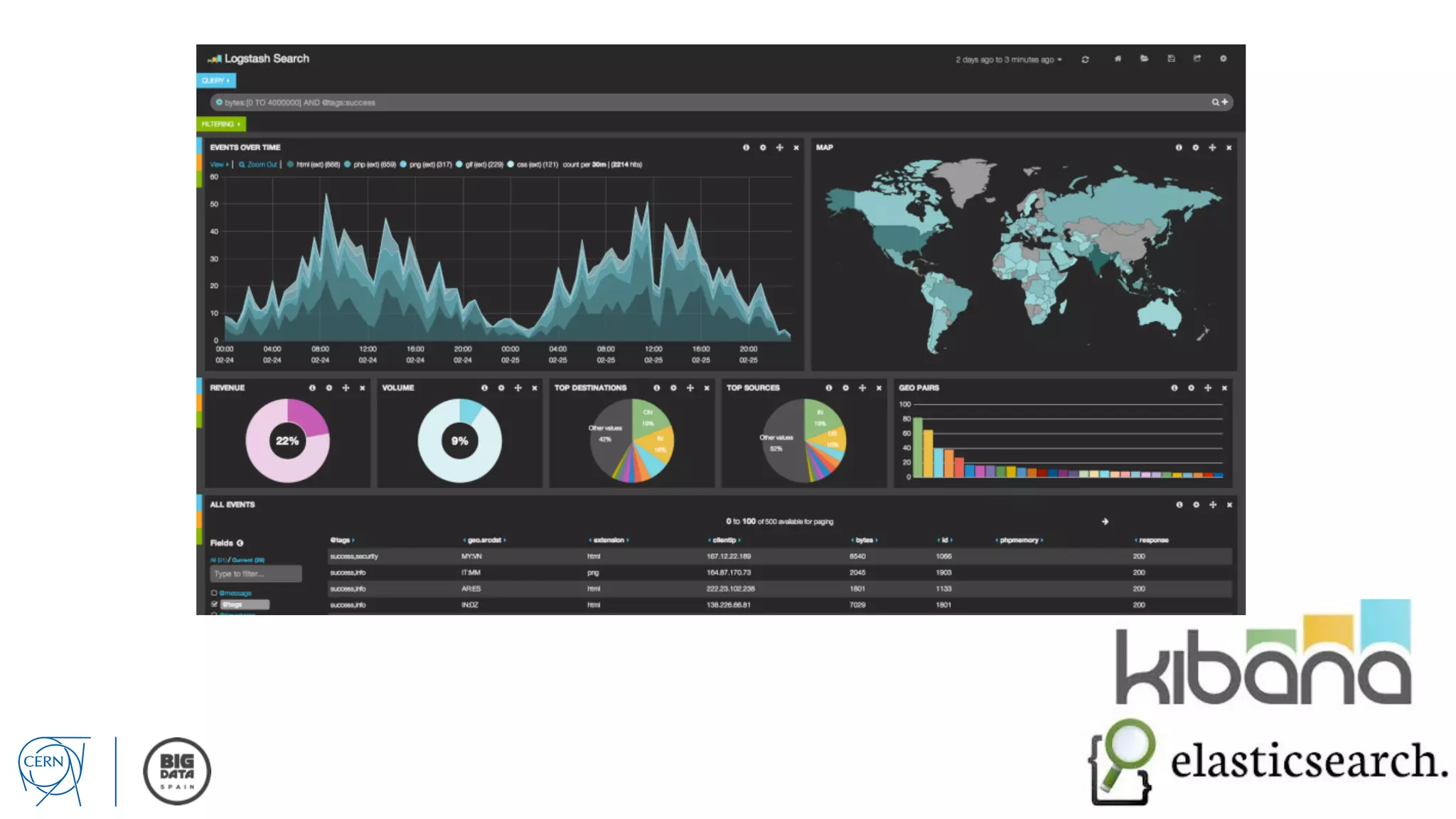
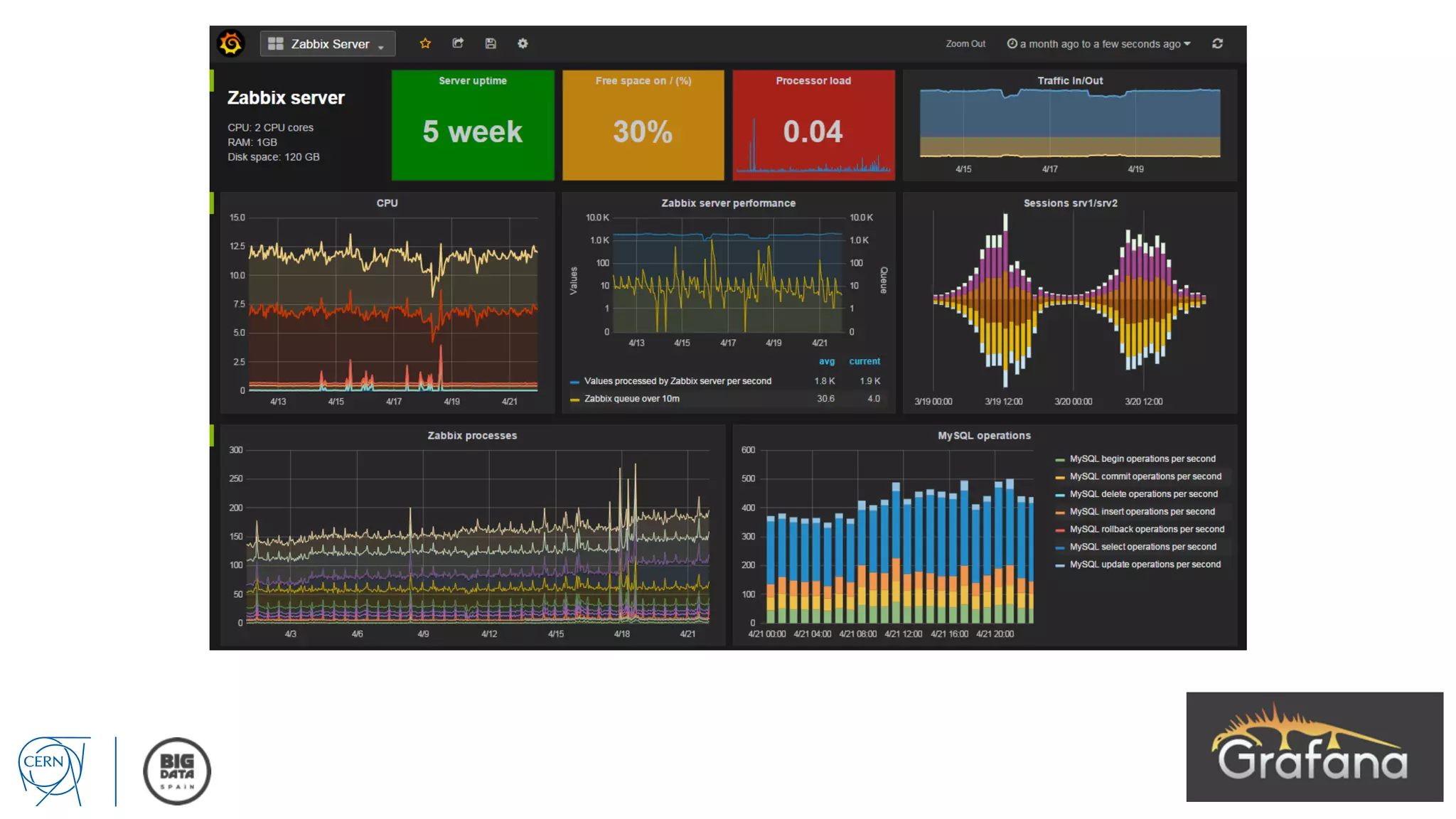
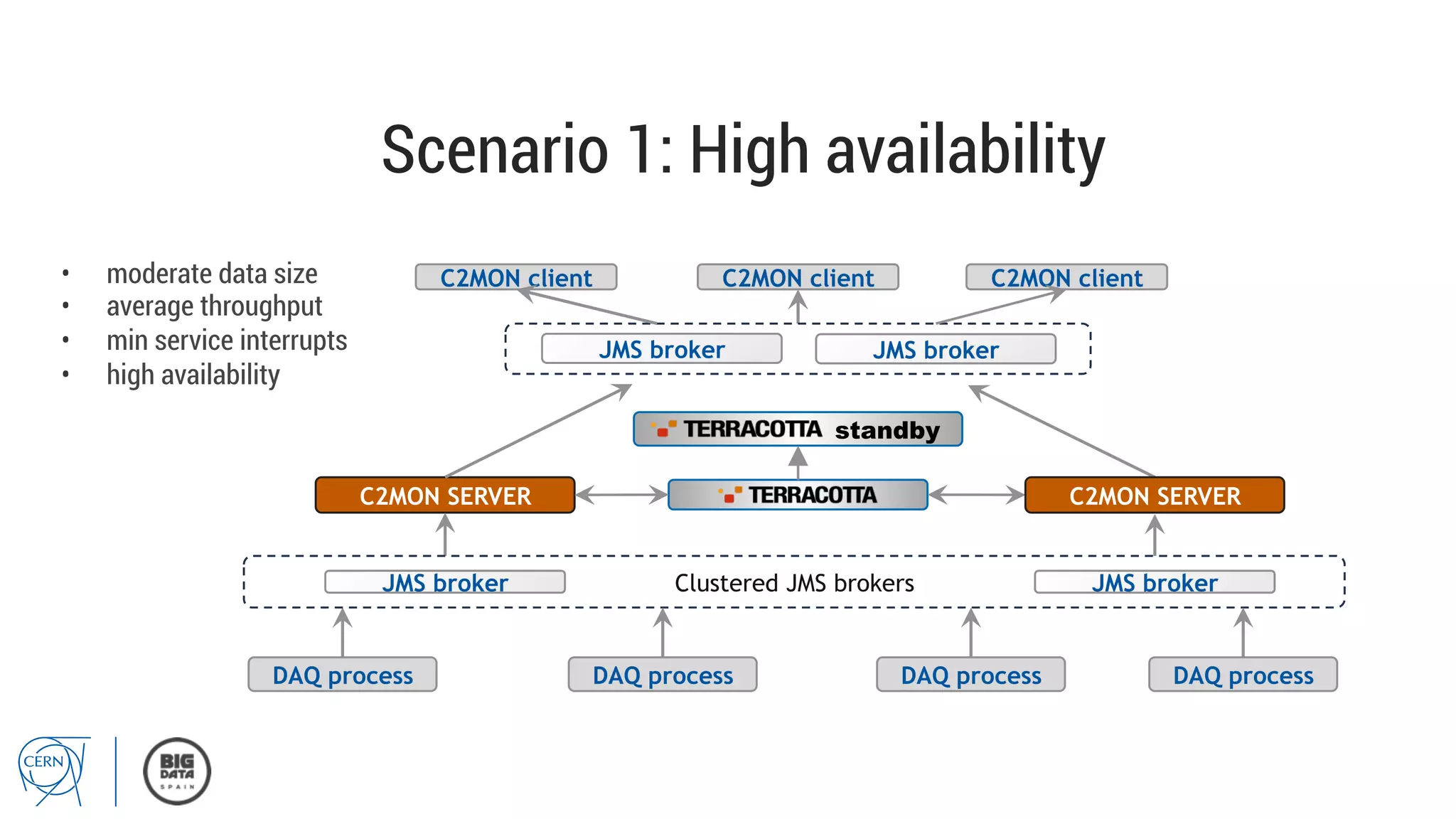
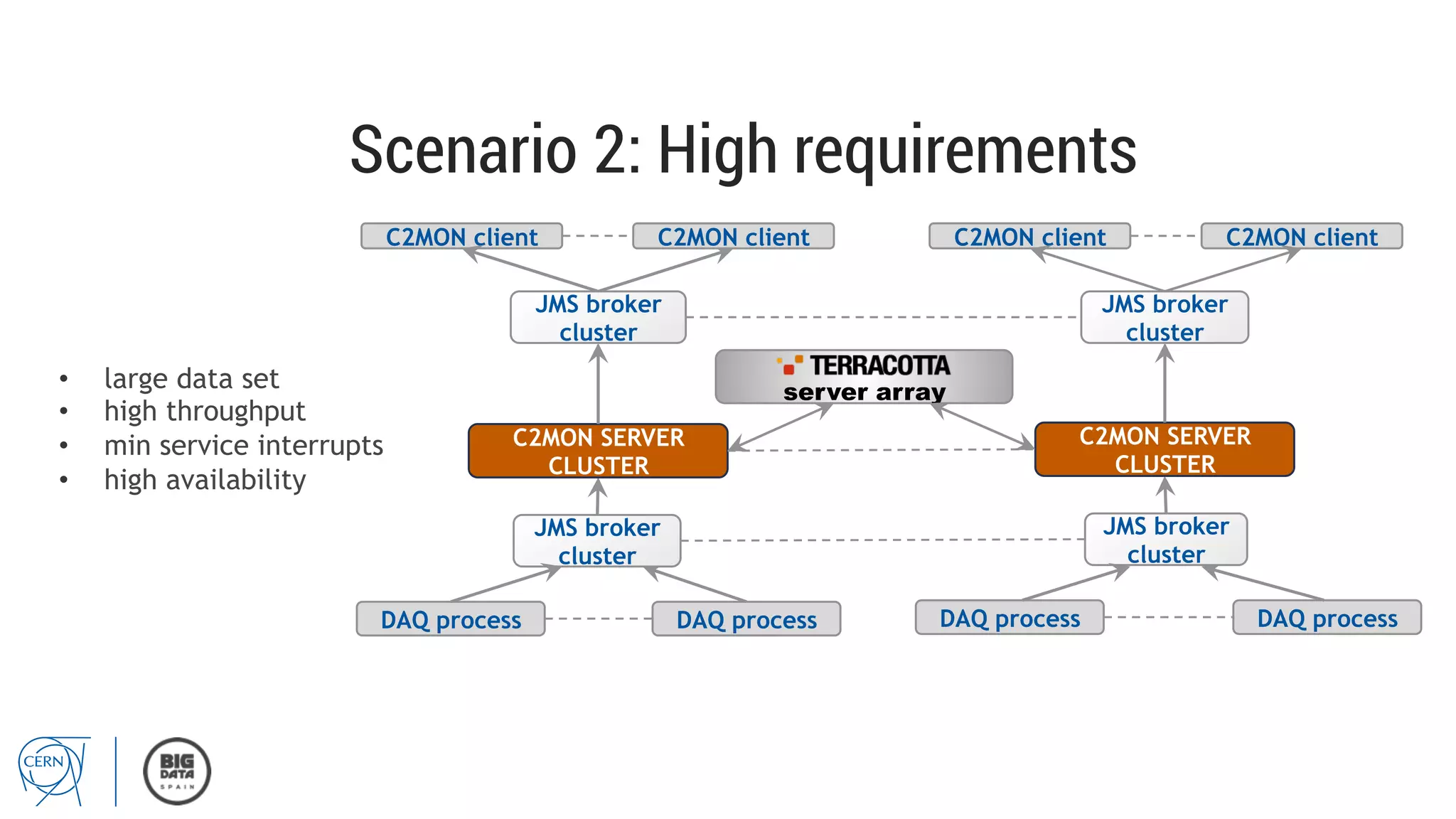







Matthias Bräger from CERN discusses the management of large infrastructure monitoring and big data analytics at CERN, emphasizing the significance of in-memory data grids and complex event processing. He highlights the operational capabilities of CERN's monitoring systems, including the C2MON platform which facilitates real-time data collection and analysis. The document outlines key challenges in data storage, processing speed, and the importance of integrating various data sources to maximize operational efficiency.











































































































