Download as PDF, PPTX




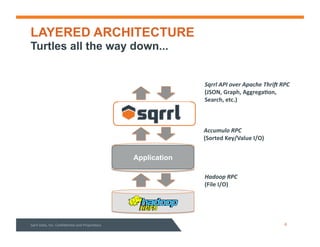

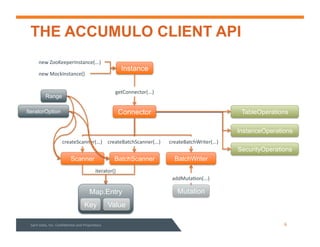
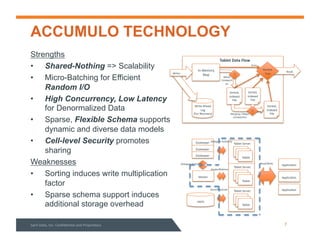

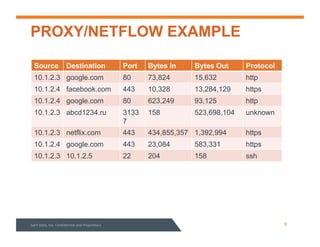
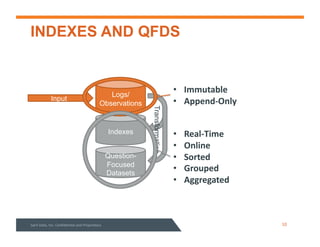

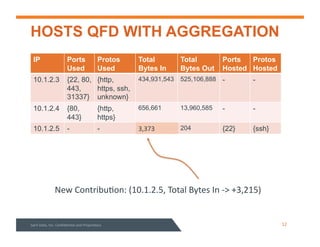
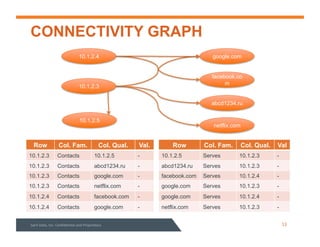
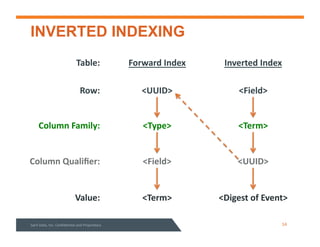
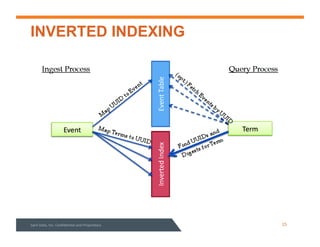
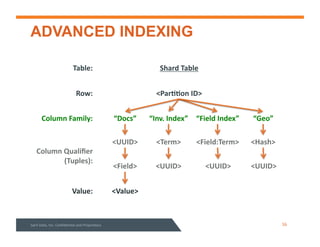





This document summarizes a webinar about data modeling and indexing for Apache Accumulo using Sqrrl. It discusses Accumulo and Sqrrl technology, including table designs for dynamic documents, graphs and inverted indexes. It also describes how Sqrrl Enterprise allows building advanced indexes and the real-time operational applications it enables.




















![[Scup] Tutorial #9 Facebook: Cómo monitorizar Facebook en Scup](https://cdn.slidesharecdn.com/ss_thumbnails/scupfacebookenscuptutorial9-131107071853-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


































































