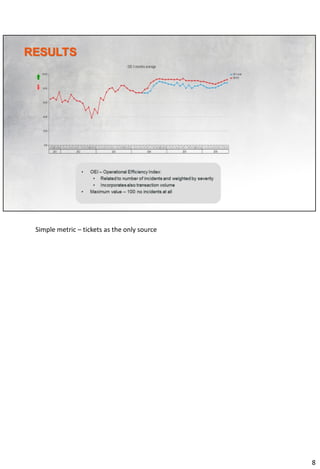
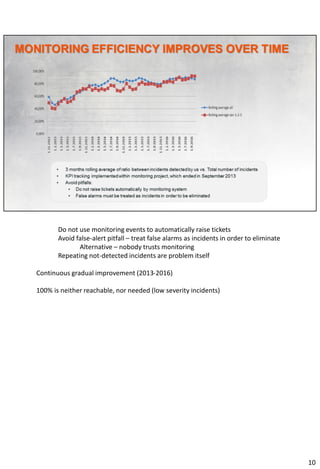
The document discusses improvements made to IT service management at a mid-sized card processing company in Croatia over 7 years. It began with typical startup issues like lack of resources and firefighting. Initiatives included defining a service catalog and SLAs, maturing incident and change management processes, implementing monitoring of critical services, embracing a culture of continuous improvement, and empowering the role of the service desk. Results included problems being resolved, Gartner metrics in the best-in-class range, and SLAs matching Gartner's outstanding levels for similar services. Further improvements could include fully utilizing a CMDB within key processes.

















![[ I B M] Ibm Banking Overview Final Version For F T U](https://cdn.slidesharecdn.com/ss_thumbnails/ibm-ibm-banking-overview-final-version-for-ftu-1304790992-phpapp01-110507131611-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































![開源 x 節流:企業導入實例分享 (二) [2016/03/31] 文件自由日研討會](https://cdn.slidesharecdn.com/ss_thumbnails/20160321x-jasoncheng-160331145235-thumbnail.jpg?width=640&height=640&fit=bounds)
























