Downloaded 12 times





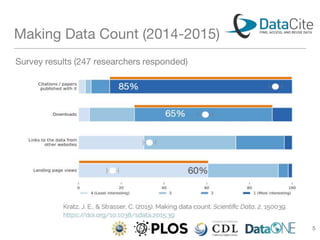




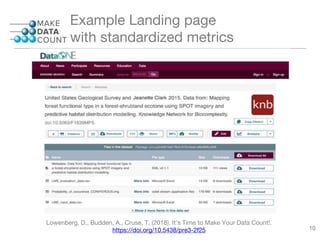







DataCite and CrossRef enhance research data sharing by providing persistent identifiers and facilitating connections between research institutions, publications, and datasets. The document discusses the challenges of data citation, including inconsistent attribution practices and the lack of stated policies on research data in many journals. Future efforts focus on improving data citation visibility and integrating citation information into publishing workflows to streamline access and recognition of research outputs.

















































































