Downloaded 23 times
















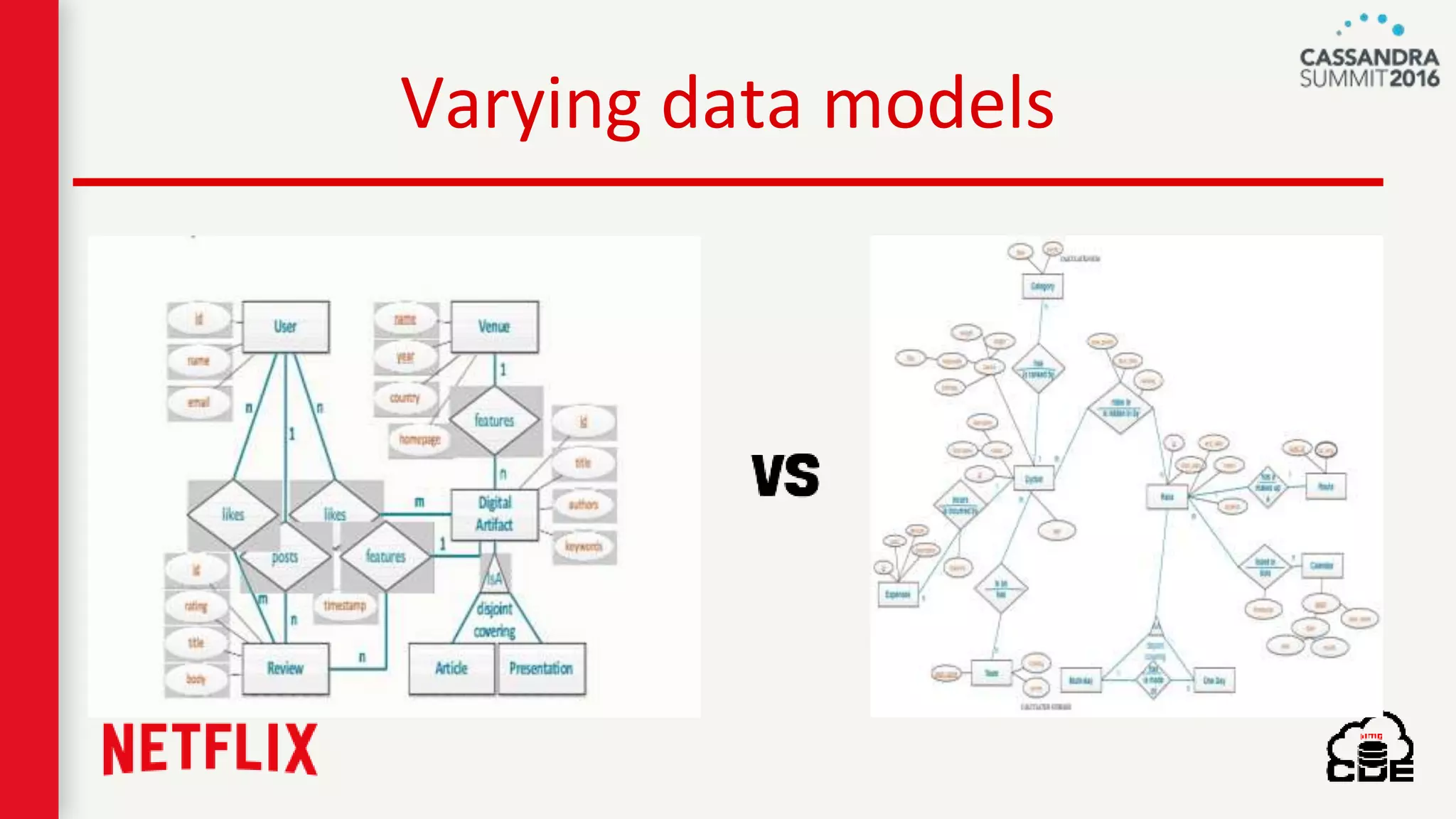



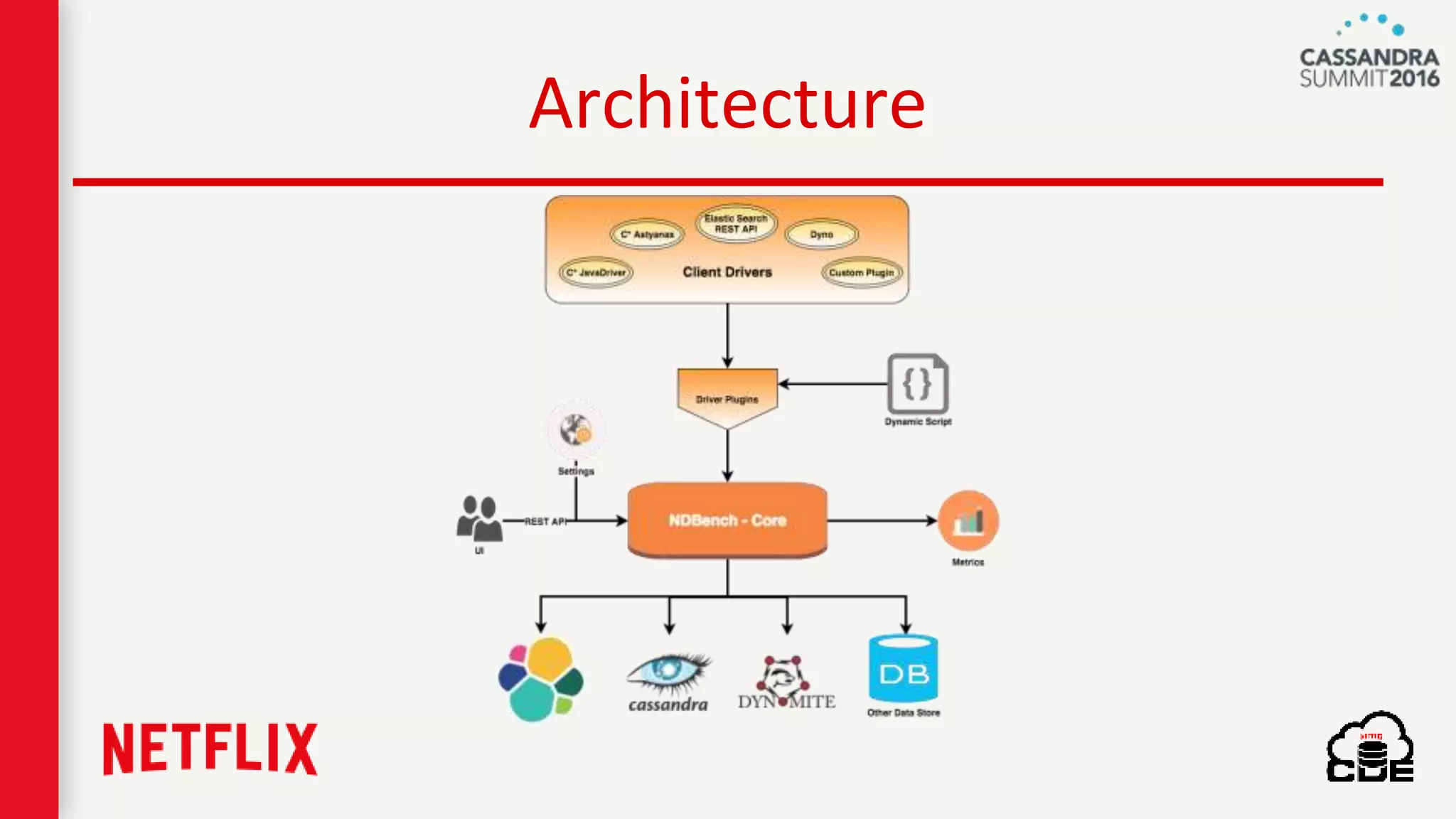








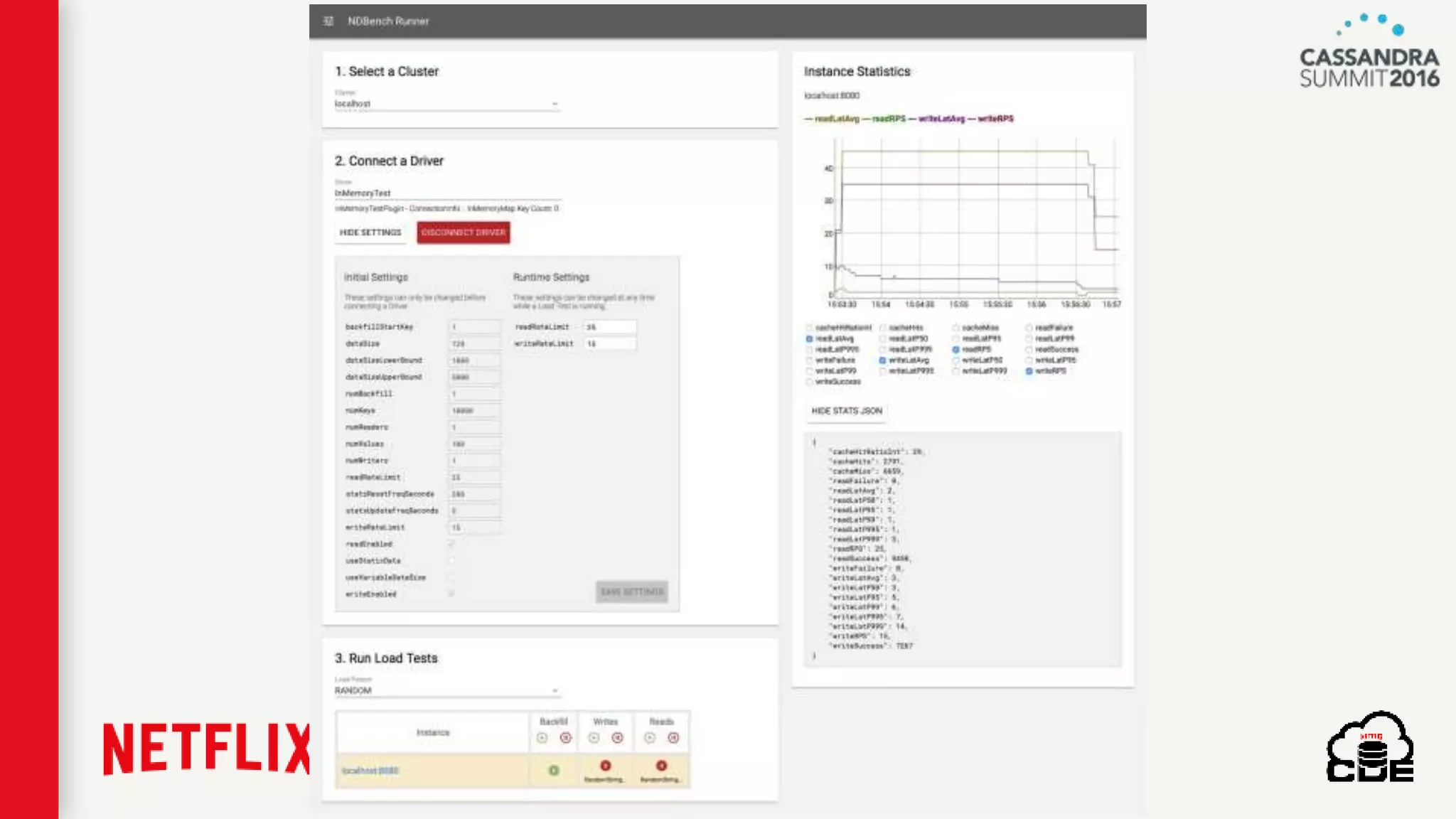


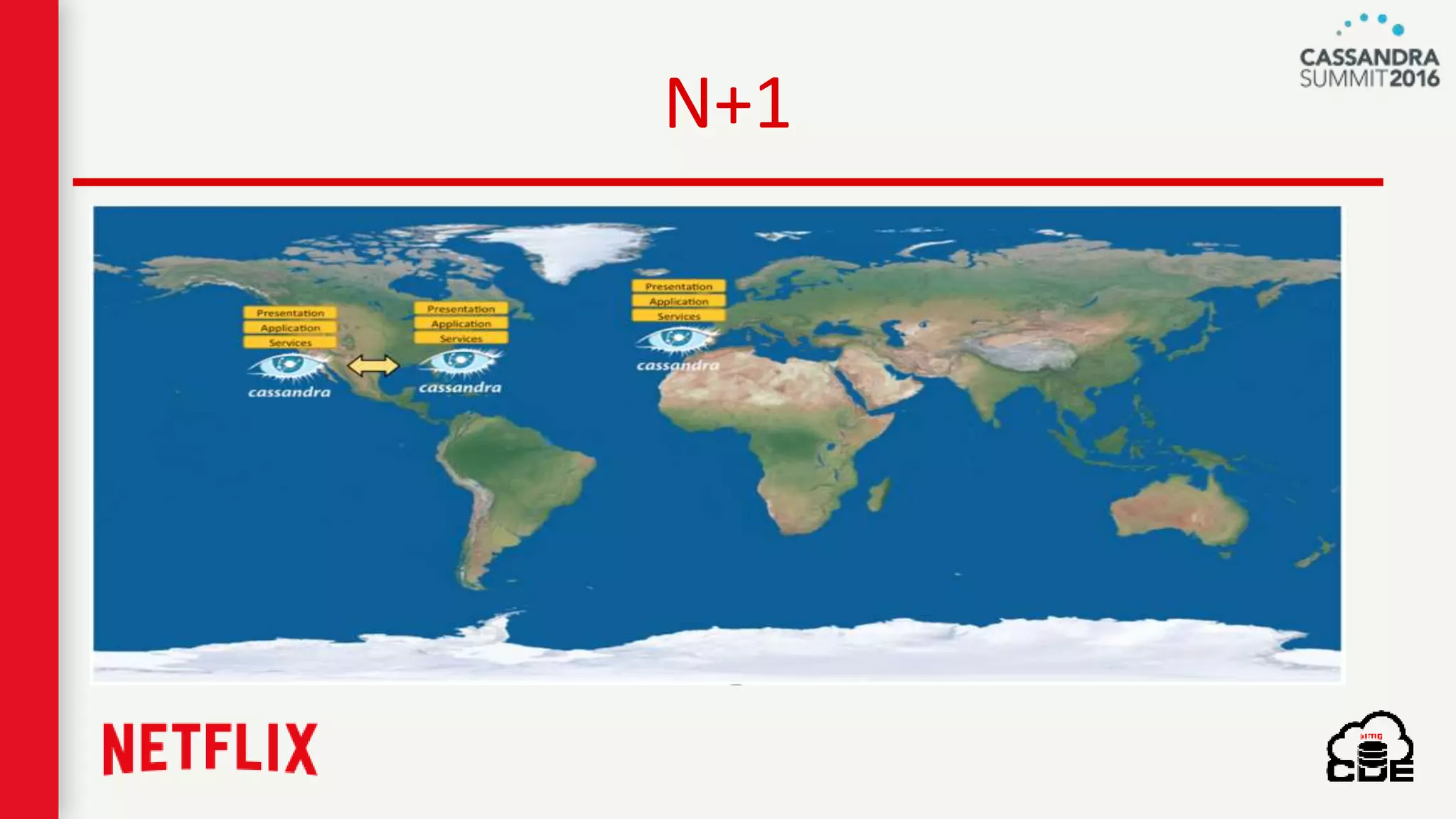
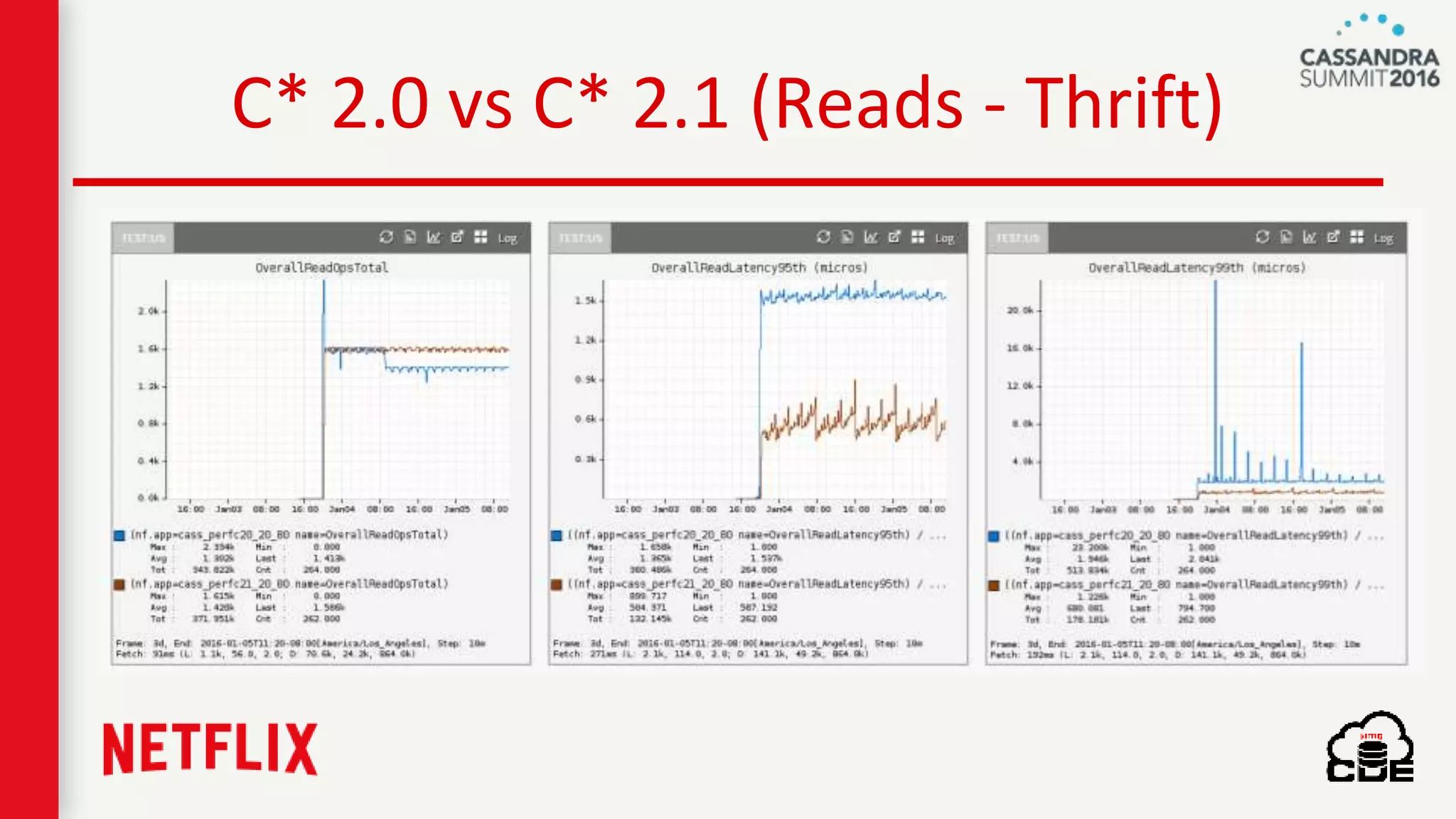
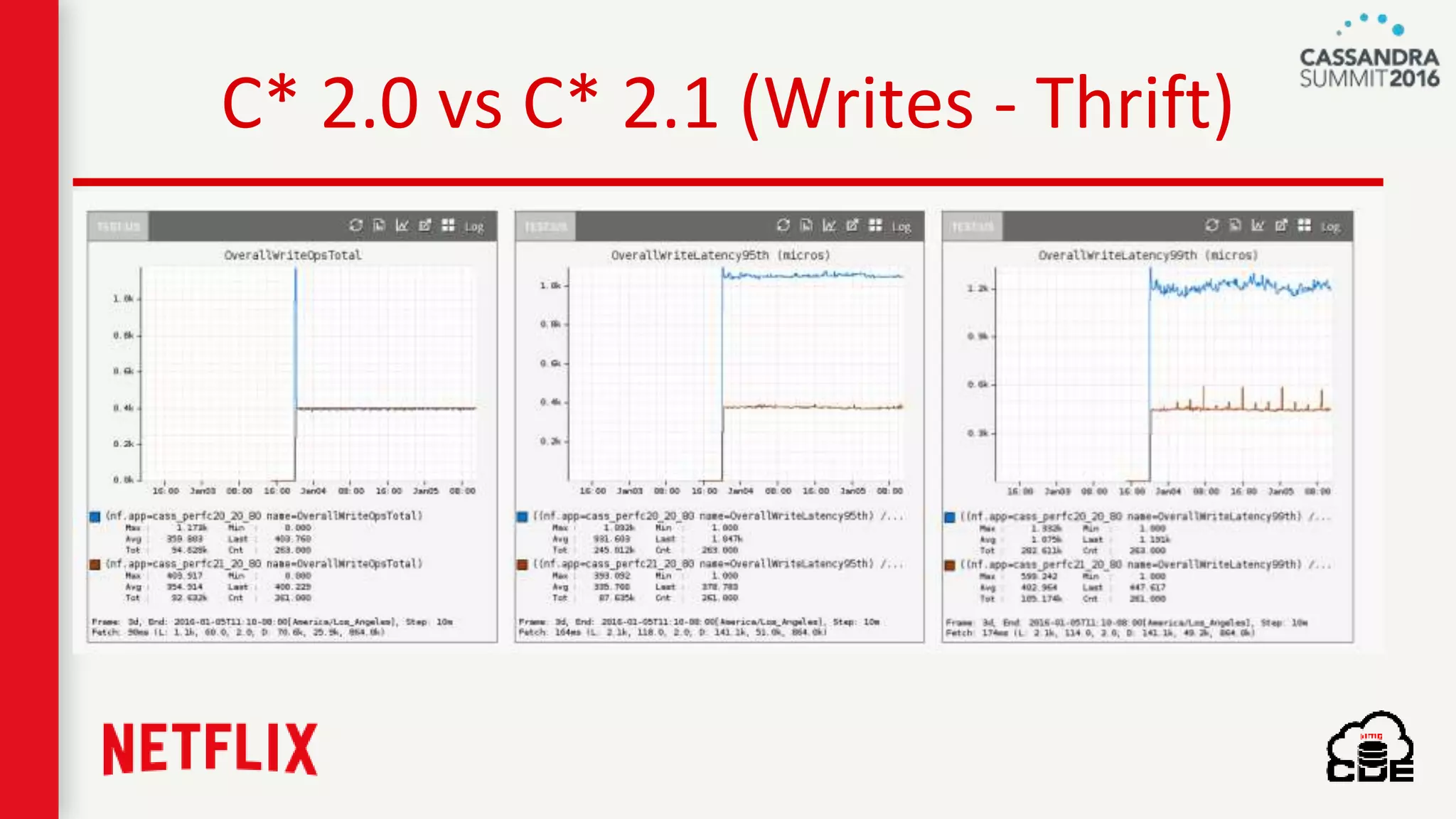
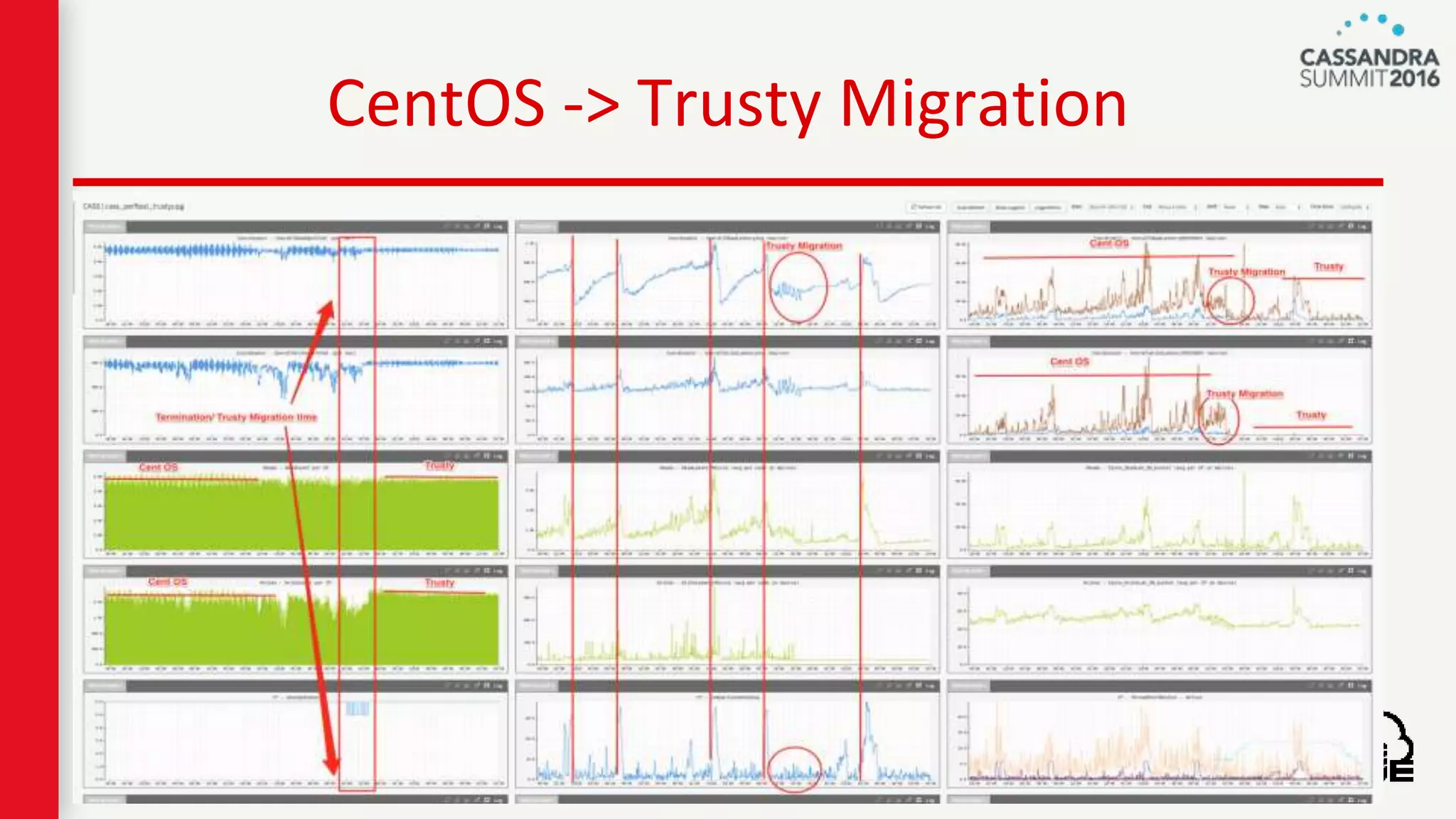
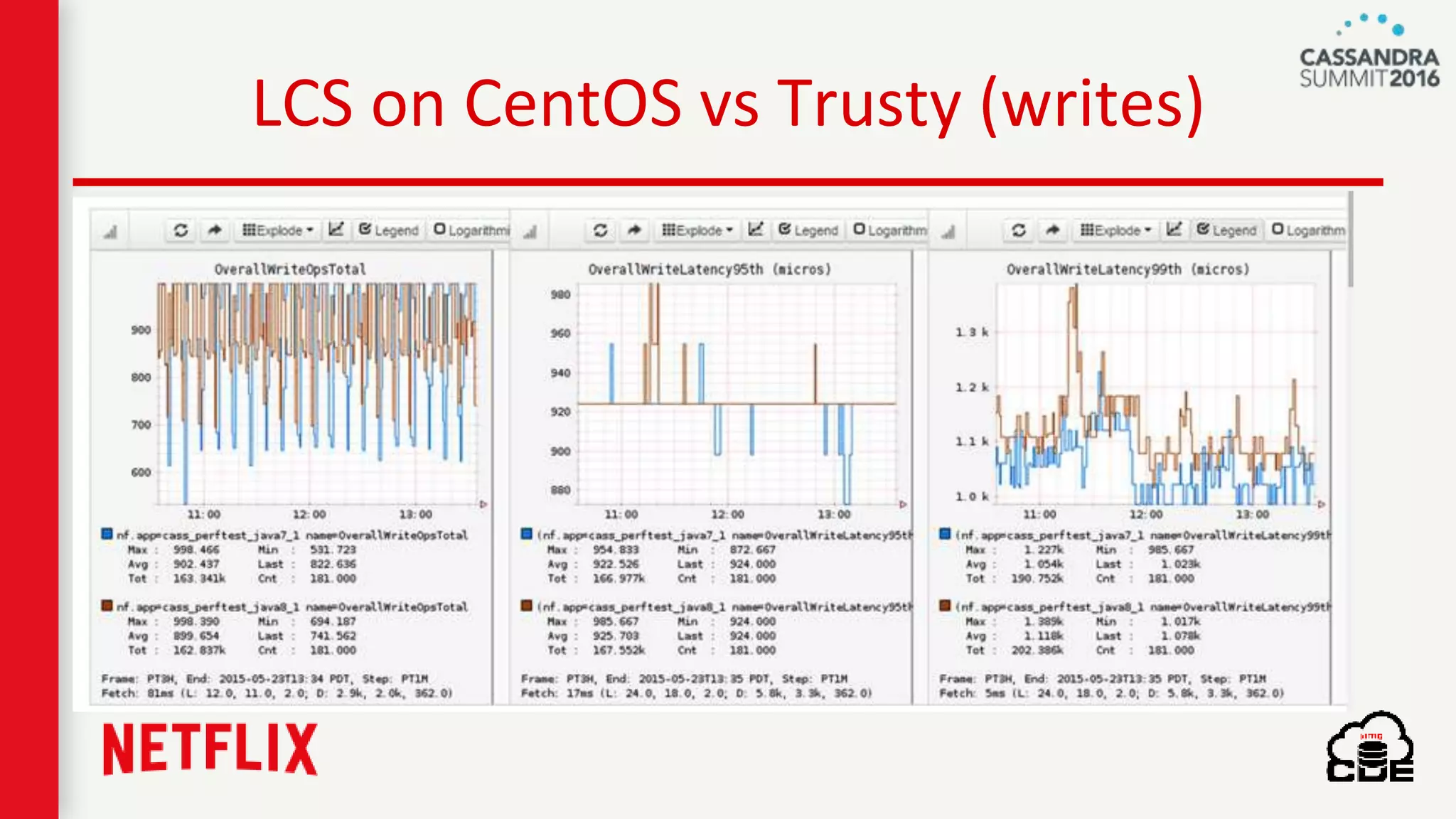
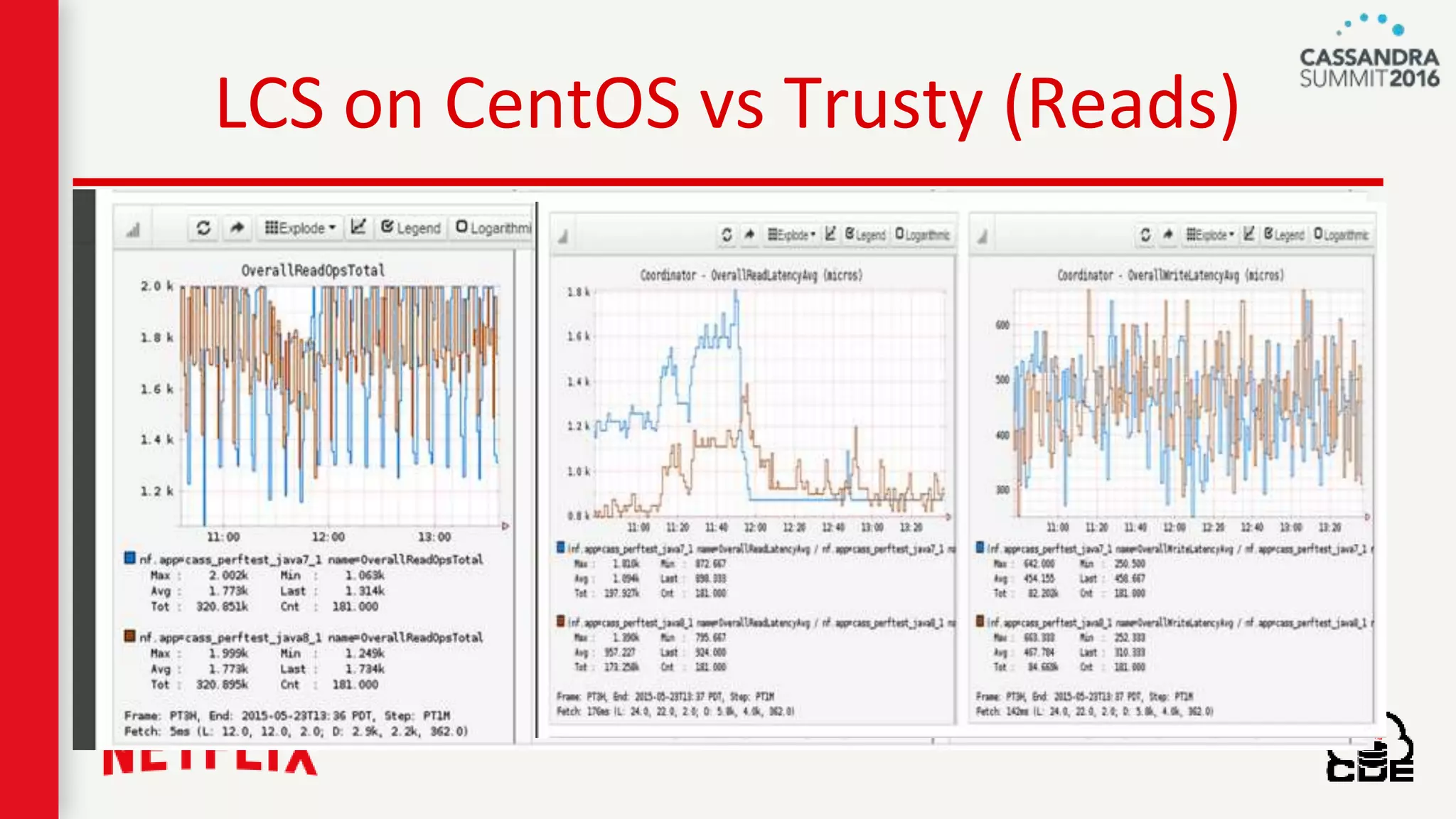
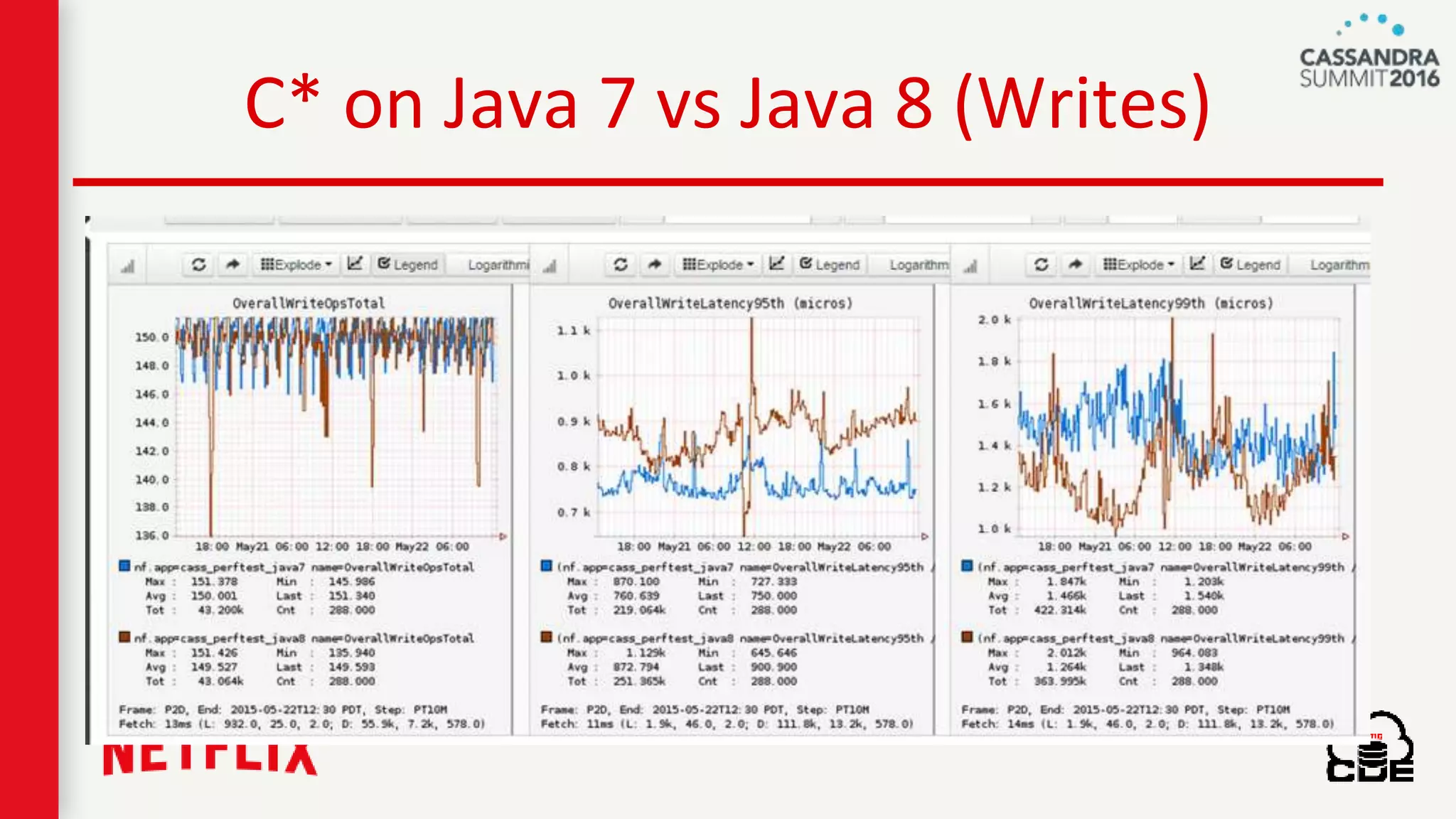
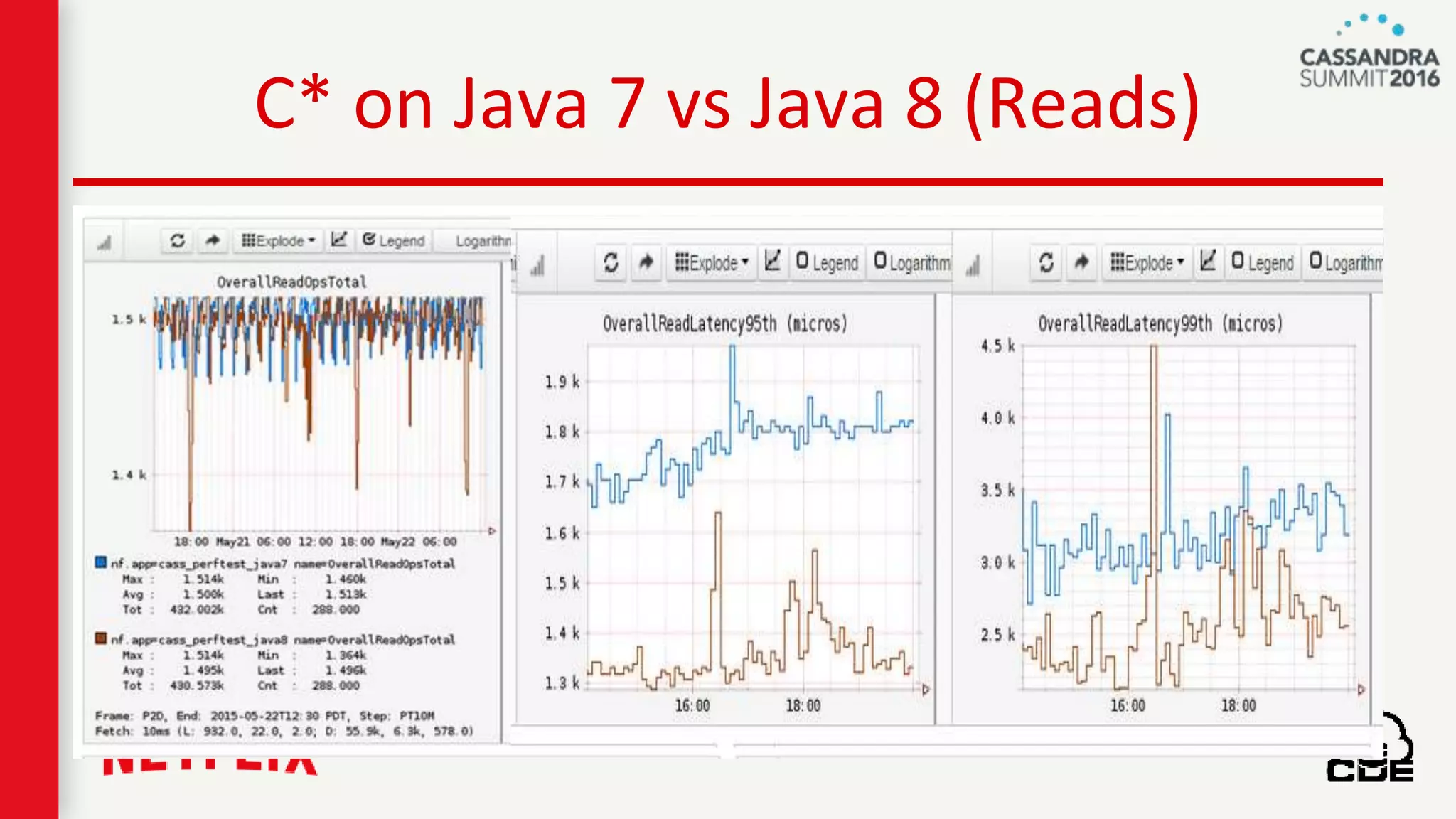
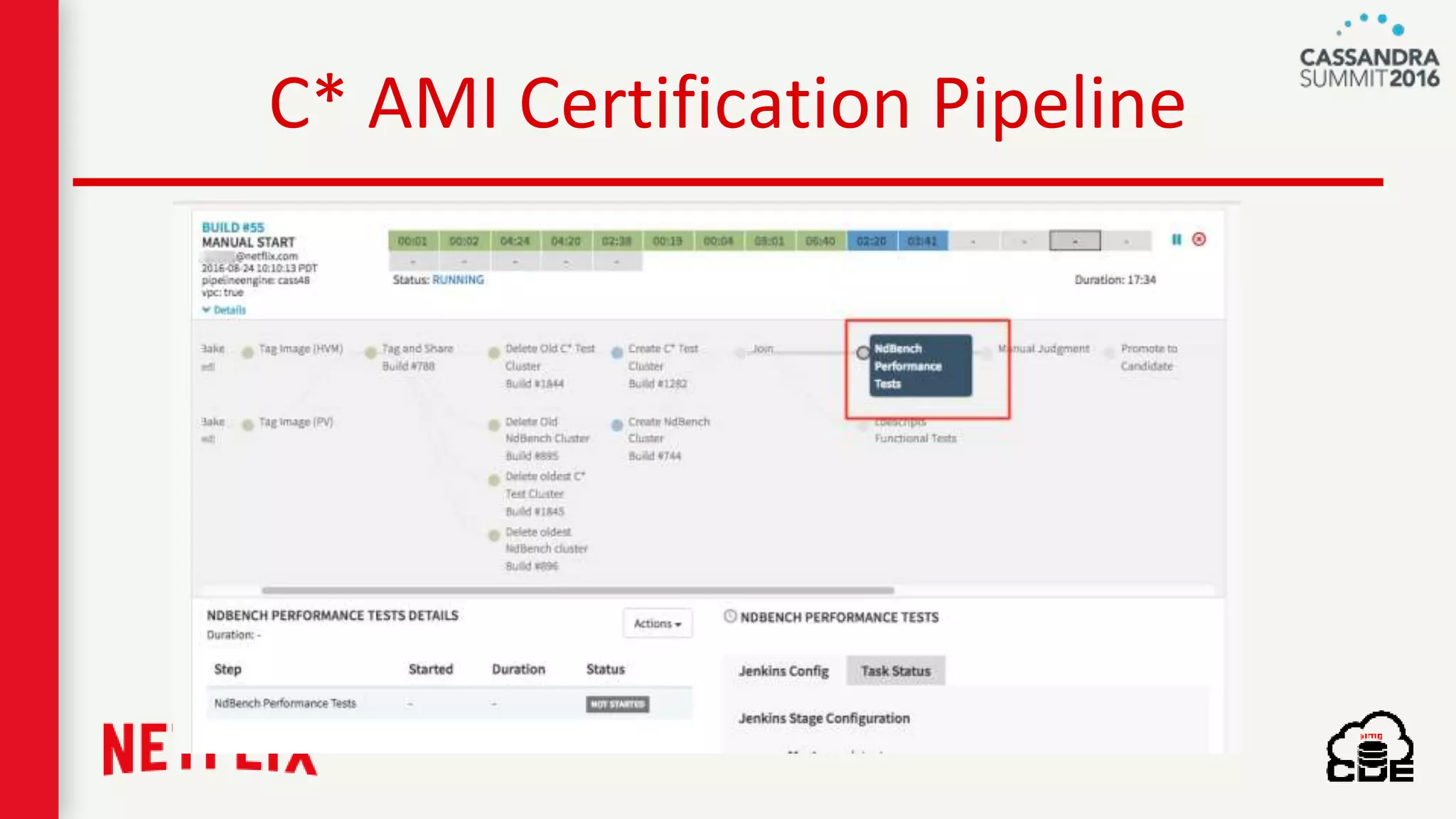
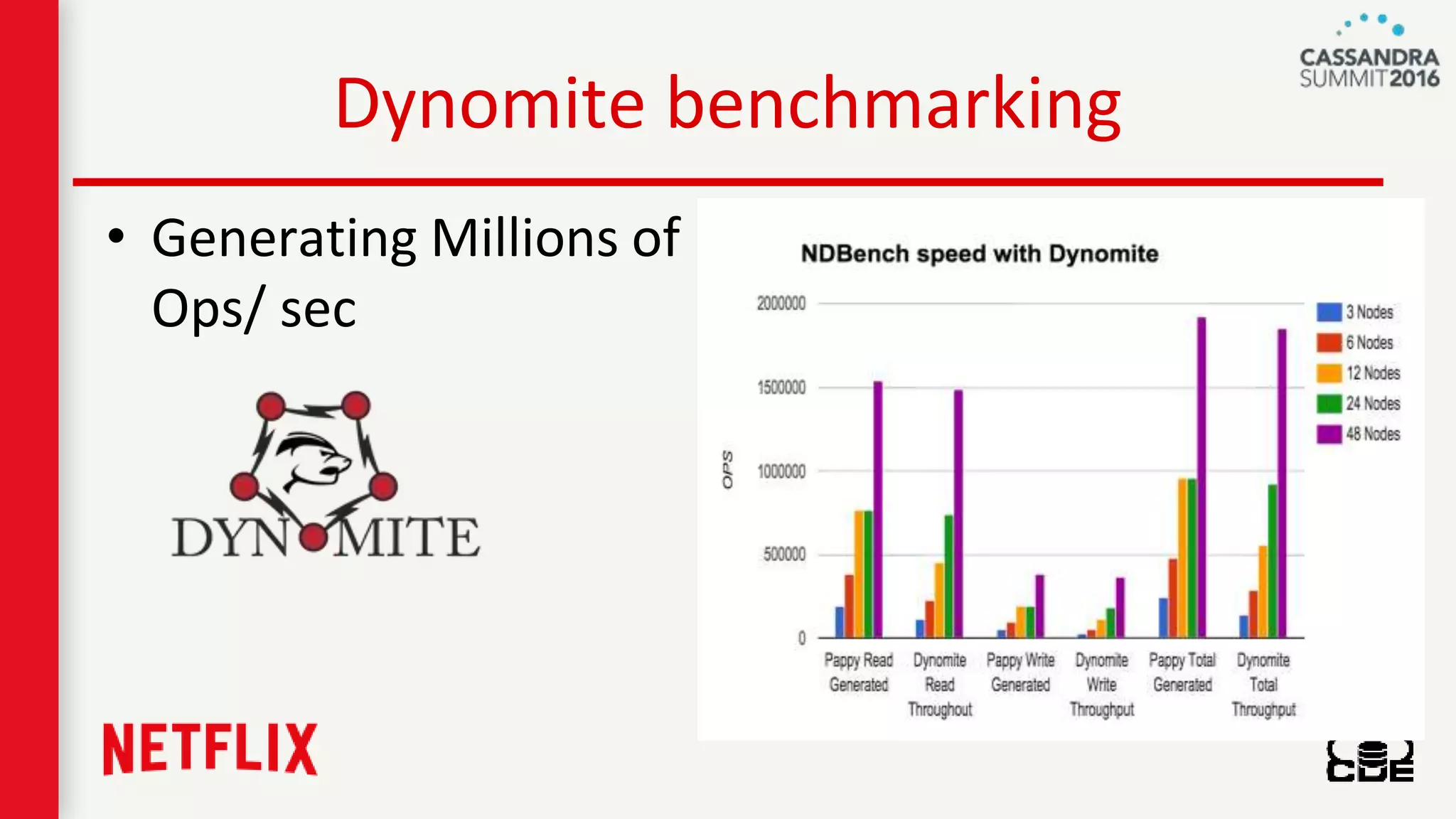
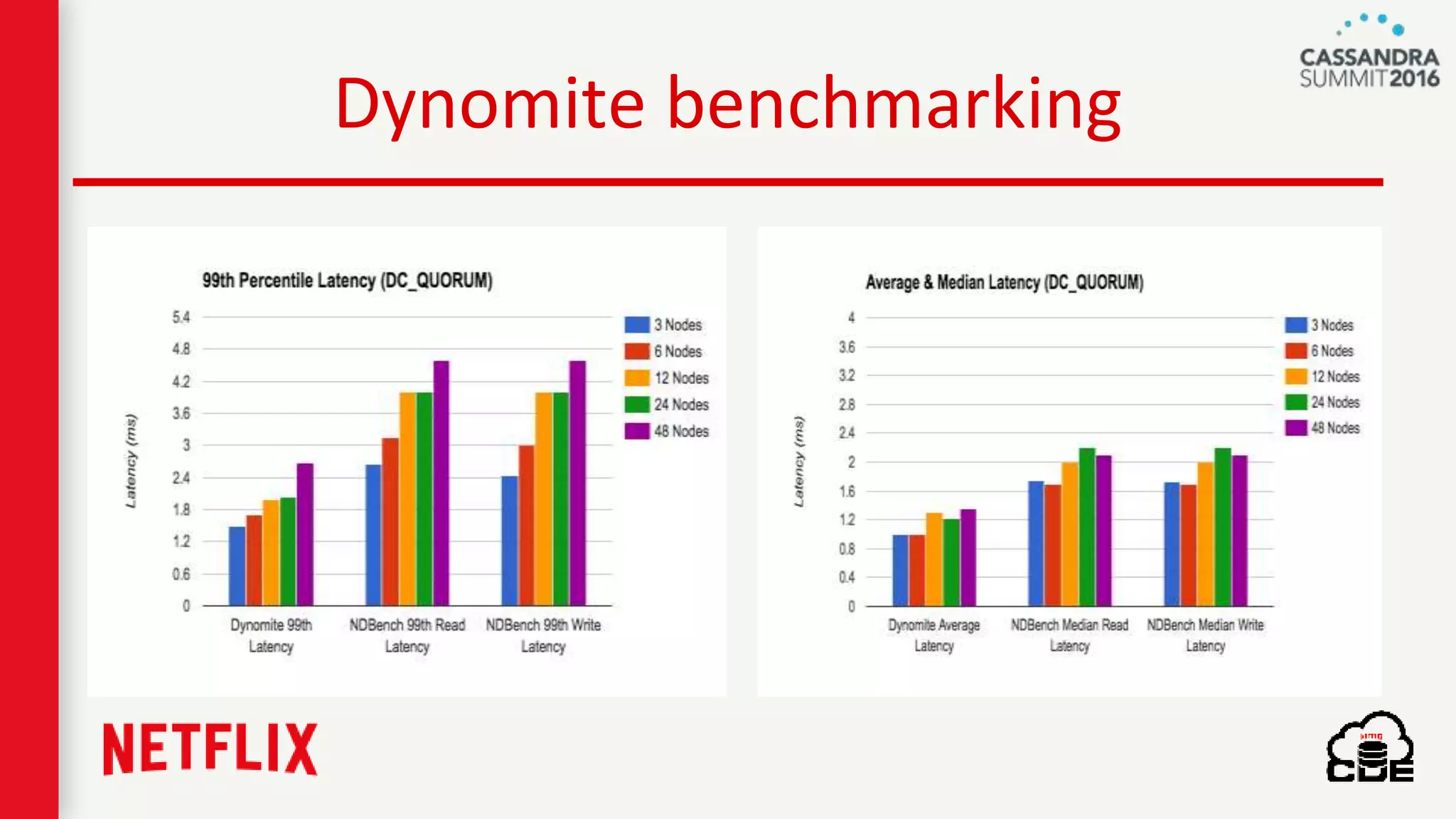





The document discusses ndbench, a benchmarking tool developed by Netflix for performance testing across various data stores, primarily Cassandra. It highlights ndbench's flexible architecture, configuration options, and its integration with Netflix's open-source infrastructure. The tool has achieved significant milestones, including successful migrations and improved performance metrics, and is designed to validate data model integrity and persistence layer efficacy in cloud environments.



![DataEngConf SF16 - BYOMQ: Why We [re]Built IronMQ](https://cdn.slidesharecdn.com/ss_thumbnails/byomq-160414230807-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































