Download as PDF, PPTX




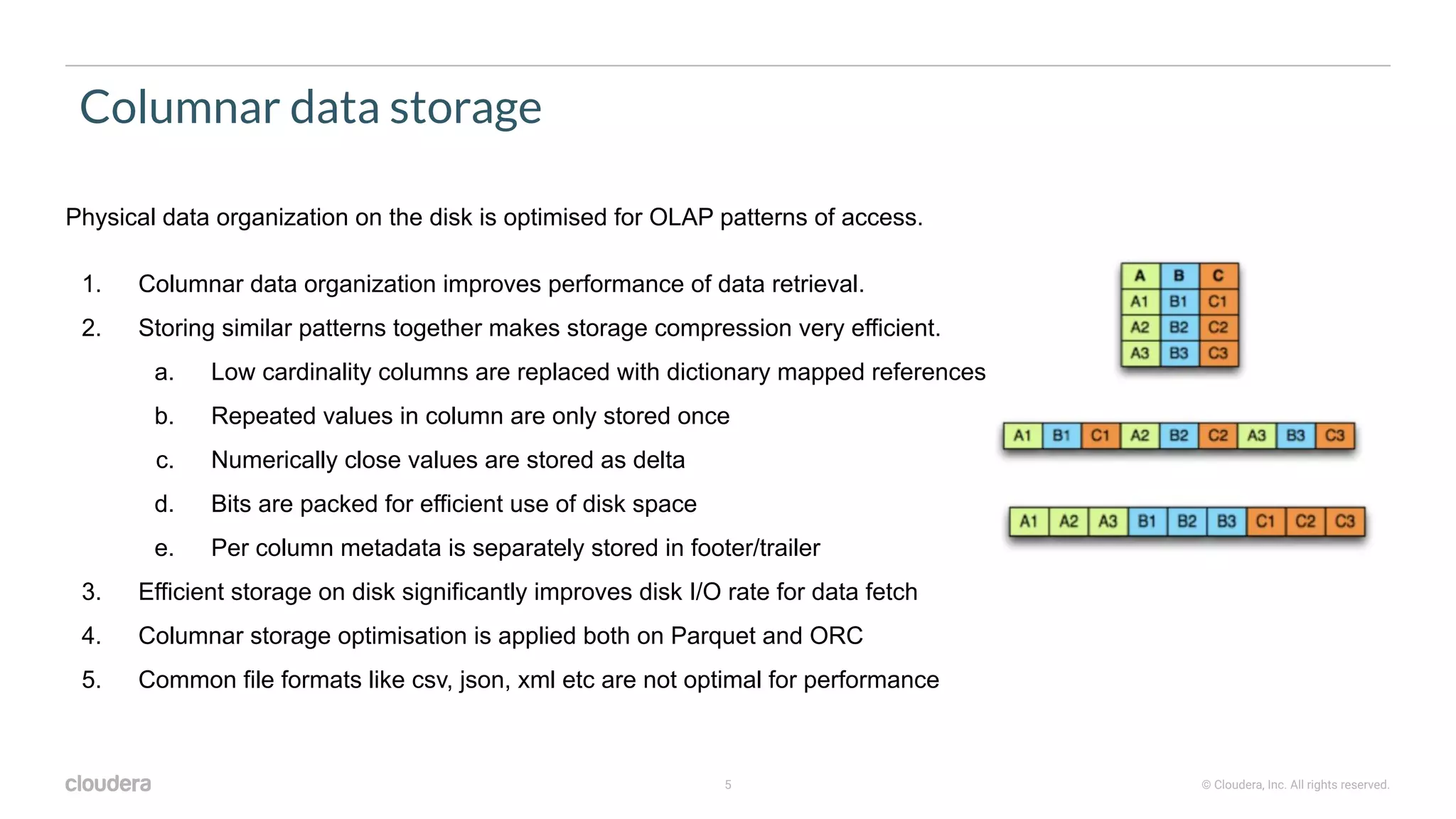











The document outlines best practices for partitioning and bucketing in Hadoop data modeling, emphasizing the importance of denormalization and optimizing for query performance. It details the benefits of columnar storage formats like ORC and Parquet, and the negative implications of excessive partitioning leading to small file issues. Key recommendations include limiting partitioning levels, maintaining optimal file sizes, and utilizing metadata for efficient query optimization.



































































