Download to read offline














































![61
[1] Alan Akbik, Tanja Bergmann, and Roland Vollgraf. Pooled contextualized em- beddings for named enBty recogniBon. In Proceedings of the 2019 Conference of the North American Chapter of the
AssociaBon for ComputaBonal Linguis- Bcs: Human Language Technologies, Volume 1 (Long and Short Papers), pages 724–728, 2019.
[2] Felipe Almeida and Geraldo Xex ́eo. Word embeddings: A survey. arXiv preprint arXiv:1901.09069, 2019.
[3] Gabriel Bernier-Colborne. IdenBfying semanBc relaBons in a specialized corpus through distribuBonal analysis of a cooccurrence tensor. In Proceedings of the Third Joint Conference on Lexical and
ComputaBonal SemanBcs (* SEM 2014), pages 57–62, 2014.
[4] Parminder BhaBa, E Busra Celikkaya, and Mohammed Khalilia. End-to-end joint enBty extracBon and negaBon detecBon for clinical text. In InternaBonal Workshop on Health Intelligence, pages
139–148. Springer, 2019.
[5] Ann Bies, Mark Ferguson, Karen Katz, Robert MacIntyre, Victoria Tredinnick, Grace Kim, Mary Ann Marcinkiewicz, and Briea Schasberger. BrackeBng guide- lines for treebank ii style penn treebank
project. University of Pennsylvania, 97: 100, 1995.
[6] Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral net- works and locally connected networks on graphs. arXiv preprint arXiv:1312.6203, 2013.
[7] Jose Camacho-Collados and Mohammad Taher Pilehvar. From word to sense embeddings: A survey on vector representaBons of meaning. J. ArBf. Int. Res., 63(1):743788, September 2018. ISSN
1076-9757. doi: 10.1613/jair.1.11259. URL heps://doi.org/10.1613/jair.1.11259.
[8] Ricardo JGB Campello, Davoud Moulavi, and J ̈org Sander. Density-based clus- tering based on hierarchical density esBmates. In Pacific-Asia conference on knowledge discovery and data mining,
pages 160–172. Springer, 2013.
[9] Jing Chen, Chenyan Xiong, and Jamie Callan. An empirical study of learning to rank for enBty search. In Proceedings of the 39th InternaBonal ACM SIGIR conference on Research and Development in
InformaBon Retrieval, pages 737– 740, 2016.
[10] Fenia Christopoulou, Makoto Miwa, and Sophia Ananiadou. A walk-based model on enBty graphs for relaBon extracBon. arXiv preprint arXiv:1902.07023, 2019.
[11] Scoe Deerwester, Susan T Dumais, George W Furnas, Thomas K Landauer, and Richard Harshman. Indexing by latent semanBc analysis. Journal of the American society for informaBon science,
41(6):391–407, 1990.
[12] Gianluca DemarBni, Tereza Iofciu, and Arjen P De Vries. Overview of the inex 2009 enBty ranking track. In InternaBonal Workshop of the IniBaBve for the EvaluaBon of XML Retrieval, pages 254–
264. Springer, 2009.
[13] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and KrisBna Toutanova. Bert: Pre- training of deep bidirecBonal transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[14] JesseDunietzandDanGillick.AnewenBtysaliencetaskwithmillionsonraining examples. In Proceedings of the 14th Conference of the European Chapter of the AssociaBon for ComputaBonal
LinguisBcs, volume 2: Short Papers, pages 205– 209, 2014.
[15] Oren Etzioni, Michael Cafarella, Doug Downey, Ana-Maria Popescu, Tal Shaked, Stephen Soderland, Daniel S Weld, and Alexander Yates. Unsupervised named- enBty extracBon from the web: An
experimental study. ArBficial intelligence, 165(1):91–134, 2005.
[16] YunBan Feng, Hongjun Zhang, Wenning Hao, and Gang Chen. Joint extracBon of enBBes and relaBons using reinforcement learning and deep learning. Com- putaBonal intelligence and
neuroscience, 2017, 2017.
[17] Kavita Ganesan and Chengxiang Zhai. Opinion-based enBty ranking. Informa- Bon retrieval, 15(2):116–150, 2012.
[18] Palash Goyal and Emilio Ferrara. Graph embedding techniques, applicaBons, and performance: A survey. Knowledge-Based Systems, 151:78–94, 2018.
[19] Hannaneh Hajishirzi, Leila Zilles, Daniel S Weld, and Luke Zeelemoyer. Joint coreference resoluBon and named-enBty linking with mulB-pass sieves. In Pro- ceedings of the 2013 Conference on
Empirical Methods in Natural Language Pro- cessing, pages 289–299, 2013.
[20] Kazi Saidul Hasan and Vincent Ng. AutomaBc keyphrase extracBon: A survey of the state of the art. In Proceedings of the 52nd Annual MeeBng of the AssociaBon for ComputaBonal LinguisBcs
(Volume 1: Long Papers), pages 1262–1273, 2014.
Reference](https://image.slidesharecdn.com/thesisslides1-200408163655/85/Hierarchical-Entity-Extraction-and-Ranking-with-Unsupervised-Graph-Convolutions-61-320.jpg)
![62
[21] Takaaki Hasegawa, Satoshi Sekine, and Ralph Grishman. Discovering relaBons among named enBBes from large corpora. In Proceedings of the 42nd annual
meeBng on associaBon for computaBonal linguisBcs, page 415. AssociaBon for ComputaBonal LinguisBcs, 2004.
[22] Mikael Henaff, Joan Bruna, and Yann LeCun. Deep convoluBonal networks on graph-structured data. arXiv preprint arXiv:1506.05163, 2015.
[23] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
[24] Johannes Hoffart, Mohamed Amir Yosef, Ilaria Bordino, Hagen Fu ̈rstenau, Man- fred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum. Robust disambiguaBon of
named enBBes in text. In Proceedings of the Con- ference on Empirical Methods in Natural Language Processing, pages 782–792. AssociaBon for ComputaBonal LinguisBcs, 2011.
[25] Benjamin Horne. NELA2017, 2019. URL heps://doi.org/10.7910/DVN/ ZCXSKG.
[26] Alpa Jain and Marco Pennacchioq. Open enBty extracBon from web search query logs. In Proceedings of the 23rd InternaBonal Conference on Computa- Bonal LinguisBcs, COLING 10, page
510518, USA, 2010. AssociaBon for Com- putaBonal LinguisBcs.
[27] Xin Jiang, Yunhua Hu, and Hang Li. A ranking approach to keyphrase ex- tracBon. In Proceedings of the 32nd internaBonal ACM SIGIR conference on Research and development in informaBon
retrieval, pages 756–757, 2009.
[28] Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zeelemoyer, and Omer Levy. Spanbert: Improving pre-training by represenBng and predicBng spans. arXiv preprint
arXiv:1907.10529, 2019.
[29] Arzoo KaByar and Claire Cardie. Nested named enBty recogniBon revisited. In
Proceedings of the 2018 Conference of the North American Chapter of the Asso- ciaBon for ComputaBonal LinguisBcs: Human Language Technologies, Volume 1 (Long Papers), pages 861–871,
2018.
[30] Steven Kearnes, Kevin McCloskey, Marc Berndl, Vijay Pande, and Patrick Riley. Molecular graph convoluBons: moving beyond fingerprints. Journal of computer- aided molecular design,
30(8):595–608, 2016.
[31] Thomas N Kipf and Max Welling. Semi-supervised classificaBon with graph convoluBonal networks. arXiv preprint arXiv:1609.02907, 2016.
[32] R ́emi Lebret and Ronan Collobert. Word emdeddings through hellinger pca. arXiv preprint arXiv:1312.5542, 2013.
[33] Kenton Lee, Luheng He, Mike Lewis, and Luke Zeelemoyer. End-to-end neural coreference resoluBon. arXiv preprint arXiv:1707.07045, 2017.
[34] Kenton Lee, Luheng He, and Luke Zeelemoyer. Higher-order coreference reso- luBon with coarse-to-fine inference. arXiv preprint arXiv:1804.05392, 2018.
[35] Qimai Li, Xiao-Ming Wu, Han Liu, Xiaotong Zhang, and Zhichao Guan. La- bel efficient semi-supervised learning via graph filtering. In Proceedings of the IEEE Conference on Computer Vision
and Paeern RecogniBon, pages 9582– 9591, 2019.
[36] Zhiyuan Liu, Wenyi Huang, Yabin Zheng, and Maosong Sun. AutomaBc keyphrase extracBon via topic decomposiBon. In Proceedings of the 2010 con- ference on empirical methods in natural
language processing, pages 366–376. As- sociaBon for ComputaBonal LinguisBcs, 2010.
[37] Peter Lofgren, Siddhartha Banerjee, and Ashish Goel. Personalized pagerank esBmaBon and search: A bidirecBonal approach. In Proceedings of the Ninth ACM InternaBonal Conference on
Web Search and Data Mining, pages 163– 172, 2016.
[38] Yi Luan, Dave Wadden, Luheng He, Amy Shah, Mari Ostendorf, and Hannaneh Hajishirzi. A general framework for informaBon extracBon using dynamic span graphs. arXiv preprint
arXiv:1904.03296, 2019.
[39] Kevin Lund and Curt Burgess. Producing high-dimensional semanBc spaces from lexical co-occurrence. Behavior research methods, instruments, & computers, 28 (2):203–208, 1996.
[40] Mitchell Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of english: The penn treebank. 1993.
Reference](https://image.slidesharecdn.com/thesisslides1-200408163655/85/Hierarchical-Entity-Extraction-and-Ranking-with-Unsupervised-Graph-Convolutions-62-320.jpg)
![63
[41] Fionn Murtagh and Pedro Contreras. Algorithms for hierarchical clustering: an overview. WIREs Data Mining and Knowledge Discovery, 2(1):86–97, 2012.
doi: 10.1002/widm.53. URL https://onlinelibrary.wiley.com/doi/abs/ 10.1002/widm.53.
[42] Vincent Ng and Claire Cardie. Improving machine learning approaches to coref- erence resolution. In Proceedings of the 40th annual meeting on association for computational linguistics, pages 104–111. Association
for Computational Lin- guistics, 2002.
[43] Thien Huu Nguyen and Ralph Grishman. Graph convolutional networks with argument-aware pooling for event detection. In Thirty-second AAAI conference on artificial intelligence, 2018.
[44] Xiaodong Ning, Lina Yao, Boualem Benatallah, Yihong Zhang, Quan Z Sheng, and Salil S Kanhere. Source-aware crisis-relevant tweet identification and key
information summarization. ACM Transactions on Internet Technology (TOIT), 19(3):1–20, 2019.
[45] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The pager- ank citation ranking: Bringing order to the web. Technical report, Stanford InfoLab, 1999.
[46] Nanyun Peng, Hoifung Poon, Chris Quirk, Kristina Toutanova, and Wen-tau Yih. Cross-sentence n-ary relation extraction with graph lstms. Transactions of the Association for Computational Linguistics, 5:101–115, 2017.
[47] Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empir- ical methods in natural language processing (EMNLP),
pages 1532–1543, 2014.
[48] Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word represen- tations. arXiv preprint arXiv:1802.05365, 2018.
[49] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representa- tions. CoRR, abs/1802.05365, 2018. URL
http://arxiv.org/abs/1802.05365.
[50] Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Olga Uryupina, and Yuchen Zhang. Conll-2012 shared task: Modeling multilingual unrestricted coref- erence in ontonotes. In Joint Conference on EMNLP and
CoNLL-Shared Task, pages 1–40. Association for Computational Linguistics, 2012.
[51] Douglas LT Rohde, Laura M Gonnerman, and David C Plaut. An improved method for deriving word meaning from lexical co-occurrence. Cognitive Psy- chology, 7:573–605, 2004.
[52] Sunil Kumar Sahu, Fenia Christopoulou, Makoto Miwa, and Sophia Ananiadou. Inter-sentence relation extraction with document-level graph convolutional neu- ral network. arXiv preprint arXiv:1906.04684, 2019.
[53] Richard Socher, John Bauer, Christopher D Manning, and Andrew Y Ng. Parsing with compositional vector grammars. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume
1: Long Papers), pages 455–465, 2013.
[54] Wee Meng Soon, Hwee Tou Ng, and Daniel Chung Yong Lim. A machine learning approach to coreference resolution of noun phrases. Computational linguistics, 27(4):521–544, 2001.
[55] Peter D Turney and Patrick Pantel. From frequency to meaning: Vector space models of semantics. Journal of artificial intelligence research, 37:141–188, 2010.
[56] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L# ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages
5998–6008, 2017.
[57] Alex D Wade, Kuansan Wang, Yizhou Sun, and Antonio Gulli. Wsdm cup 2016: Entity ranking challenge. In Proceedings of the ninth ACM international conference on web search and data mining, pages 593–594, 2016.
[58] Chengyu Wang, Guomin Zhou, Xiaofeng He, and Aoying Zhou. Nerank+: a graph-based approach for entity ranking in document collections. Frontiers of Computer Science, 12(3):504–517, 2018.
[59] Yi-fang Brook Wu, Quanzhi Li, Razvan Stefan Bot, and Xin Chen. Domain- specific keyphrase extraction. In Proceedings of the 14th ACM international conference on Information and knowledge management, pages
283–284, 2005.
[60] Chenyan Xiong, Russell Power, and Jamie Callan. Explicit semantic ranking for academic search via knowledge graph embedding. In Proceedings of the 26th international conference on world wide web, pages 1271–
1279, 2017.
[61] Ying Xiong, Yedan Shen, Yuanhang Huang, Shuai Chen, Buzhou Tang, Xiaolong Wang, Qingcai Chen, Jun Yan, and Yi Zhou. A deep learning-based system for pharmaconer. In Proceedings of The 5th Workshop on BioNLP
Open Shared Tasks, pages 33–37, 2019.
[62] Vikas Yadav and Steven Bethard. A survey on recent advances in named entity recognition from deep learning models, 2019.
[63] Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. Embed- ding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575, 2014.
[64] Meishan Zhang, Yue Zhang, and Guohong Fu. End-to-end neural relation ex- traction with global optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1730–
1740, 2017.
[65] Yuhao Zhang, Peng Qi, and Christopher D Manning. Graph convolution over pruned dependency trees improves relation extraction. arXiv preprint arXiv:1809.10185, 2018.
Reference](https://image.slidesharecdn.com/thesisslides1-200408163655/85/Hierarchical-Entity-Extraction-and-Ranking-with-Unsupervised-Graph-Convolutions-63-320.jpg)

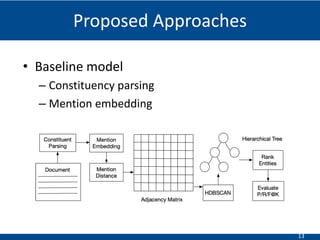
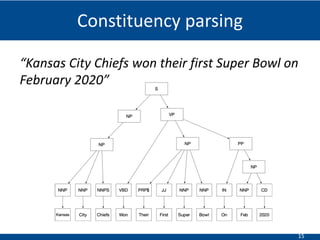
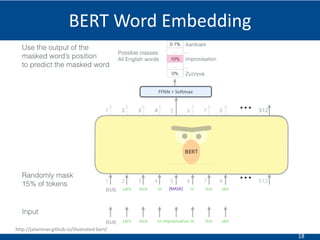
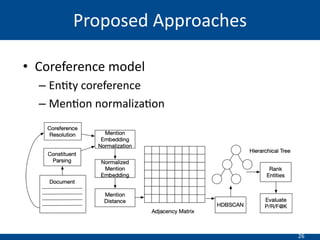
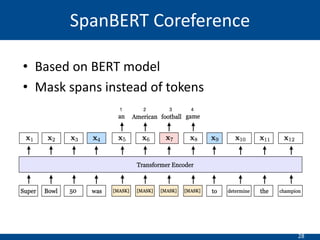
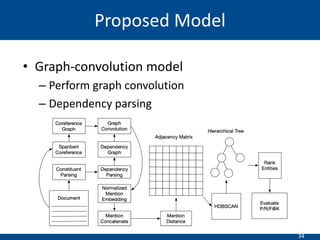
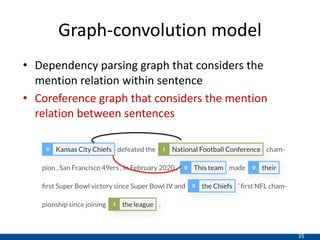
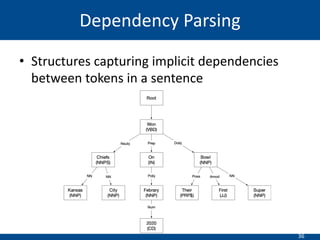
The document summarizes a presentation on hierarchical entity extraction and ranking using unsupervised graph convolutions. It outlines the proposed approaches which include using constituency parsing to extract mention candidates, BERT to obtain contextualized word embeddings, and graph convolution on a dependency parsing graph and coreference graph to normalize mention embeddings. It describes the experiments on a political news dataset, comparing the proposed graph-based model to baselines. The analysis shows the graph model achieves meaningful entity extraction, ranking and hierarchies.


































































