This document discusses hash functions and their applications. It covers hash function properties, popular hash functions used in applications like hash tables and sets, and how to evaluate hash functions. It also discusses Bloom filters, including how to tune them, and HashFile, a hash-oriented storage structure that provides constant-time lookups from disk. The document concludes with future work ideas like implementing new hash functions and extending HashFile capabilities.
![Hash Functions FTW*
Fast Hashing, Bloom Filters & Hash-Oriented Storage
Sunny Gleason
* For the win (see urbandictionary FTW[1]); this expression has nothing to do with hash functions](https://image.slidesharecdn.com/hashfunctionsftw-100719112524-phpapp02/85/Hash-Functions-FTW-1-320.jpg)
![Hash Functions FTW*
Fast Hashing, Bloom Filters & Hash-Oriented Storage
Sunny Gleason
* For the win (see urbandictionary FTW[1]); this expression has nothing to do with hash functions](https://image.slidesharecdn.com/hashfunctionsftw-100719112524-phpapp02/75/Hash-Functions-FTW-1-2048.jpg)

![Hash Functions
int getIntHash(byte[] data); // 32-bit
long getLongHash(byte[] data) // 64-bit
int v1 = hash(“foo”); int v2 = hash(“goo”);
int hash(byte[] value) { // a simple hash
int h = 0;
for (byte b: value) { h = (h<<5) ^ (h>>27) ^ b; }
return h % PRIME;
}](https://image.slidesharecdn.com/hashfunctionsftw-100719112524-phpapp02/85/Hash-Functions-FTW-3-320.jpg)

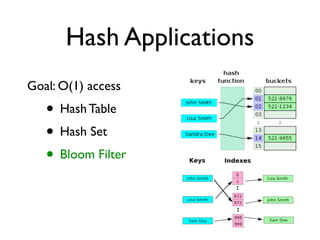




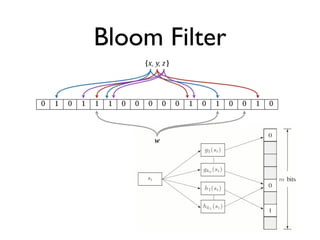


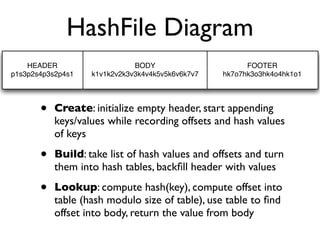
![Hash-Oriented Storage
• HashFile : 64-bit clone of djb’s constant db
“CDB”
• Plain ol’ Key/Value storage:
add(byte[] k, byte[] v), byte[] lookup(byte[] k)
• Constant aka “Immutable” Data Store
create(), add(k, v) ... , build() ... before lookup(k)
• Use properties of hash table to achieve
O(1) disk seeks per lookup](https://image.slidesharecdn.com/hashfunctionsftw-100719112524-phpapp02/85/Hash-Functions-FTW-13-320.jpg)